SSL4RL: Revisiting Self-supervised Learning as Intrinsic Reward for Visual-Language Reasoning
-
ArXiv URL: http://arxiv.org/abs/2510.16416v1
-
作者: Yifei Wang; Qi Zhang; Wei Lin; Xiaohan Wang; Stefanie Jegelka; Yisen Wang; Chenheng Zhang; Jiajun Chai; Guojun Yin; Xiaojun Guo
-
发布机构: MIT; Meituan; Peking University; TUM
TL;DR
本文提出了一种名为 SSL4RL 的新框架,通过将自监督学习(SSL)任务重新定义为可验证的内在奖励,对视觉语言模型(VLM)进行强化学习(RL)微调,从而在无需人工标注或AI评判器的情况下有效提升模型的视觉推理与对齐能力。
关键定义
- SSL4RL (Self-supervised Learning for Reinforcement Learning): 一种新颖的训练框架,其核心思想是将在预训练中用于表征学习的自监督学习(SSL)任务(如预测图像旋转角度、重建被遮蔽的图像块等)转化为强化学习(RL)中的内在奖励信号。通过这种方式,它为大型模型的后训练(post-training)阶段提供了一种可自动验证、可大规模扩展且无需外部监督的奖励机制,用于对齐模型行为。
- 可验证奖励 (Verifiable Rewards): 指那些可以通过确定性程序或明确的基准答案(ground-truth)自动计算其正确性的奖励信号。在 SSL4RL 框架中,自监督任务的固有目标(如正确的旋转角度、原始的图像块位置)直接提供了这种可验证的奖励,与依赖人类偏好或“LLM-as-a-judge”等模糊、有偏的奖励信号形成鲜明对比。
相关工作
当前,视觉语言模型(VLM)虽然强大,但存在系统性缺陷:在处理视觉中心任务时,它们倾向于忽略视觉证据,依赖语言先验知识;在进行多模态推理时,又常常利用文本捷径而非真正基于视觉内容进行推理。
强化学习(RL),特别是基于人类反馈的强化学习(RLHF),已成为对齐大模型行为的主流范式。然而,其成功依赖于高质量的奖励信号。在数学、编程等领域,可以通过程序化验证器(verifier)提供可靠奖励,即所谓的“验证器驱动的RL”。但在更广泛的领域,由于缺乏此类验证器,研究者常退而求其次使用“LLM-as-a-judge”方案,但其奖励信号充满噪声、存在偏见且易被攻击。
本文旨在解决的核心问题是:如何在缺乏人类偏好数据或可靠外部验证器的场景下,为视觉语言模型的强化学习训练提供一种可扩展、可靠且低成本的奖励机制,以增强模型的视觉基础能力和推理的忠实度。
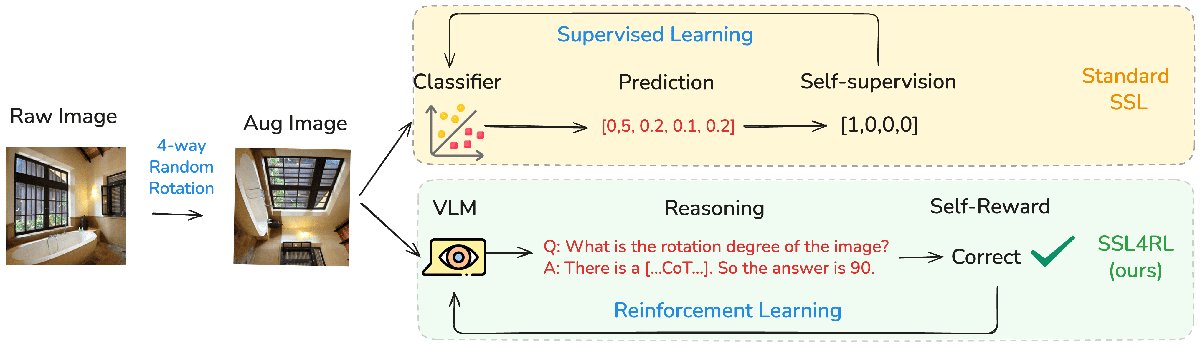
本文方法
SSL4RL框架
SSL4RL 的核心是将自监督学习(SSL)目标重新诠释为强化学习(RL)的奖励函数,用于模型的后训练。该框架将每个 SSL 任务形式化地定义为一个 RL 问题。
具体来说,一个 SSL 任务定义了一个“环境”:
- 状态与动作:一个数据损坏函数 $c(x) = (\tilde{x}, y)$ 将一个原始输入 $x$(例如一张图片)转换成一个损坏后的上下文 $\tilde{x}$(例如旋转后的图片)和一个基准真相目标 $y$(例如旋转角度)。
- 策略:模型 $\pi_{\theta}$(即 VLM)作为一个策略,它接收损坏的输入 $\tilde{x}$ 并生成一个预测输出 $\hat{y}$(例如,一段描述旋转角度的文本)。
- 奖励:一个奖励函数 $r(\hat{y}, y)$ 通过比较模型的预测 $\hat{y}$ 与基准真相 $y$ 来计算一个标量奖励。由于 $y$ 是从数据本身派生出来的,这个奖励是可验证且自足的。
通过这个过程,任何 SSL 任务都可以生成密集的、可自动计算的奖励信号,为 RL 训练提供动力。
将SSL任务转化为RL奖励
本文研究了四种代表性的视觉 SSL 任务,并将它们转化为 RL 奖励: 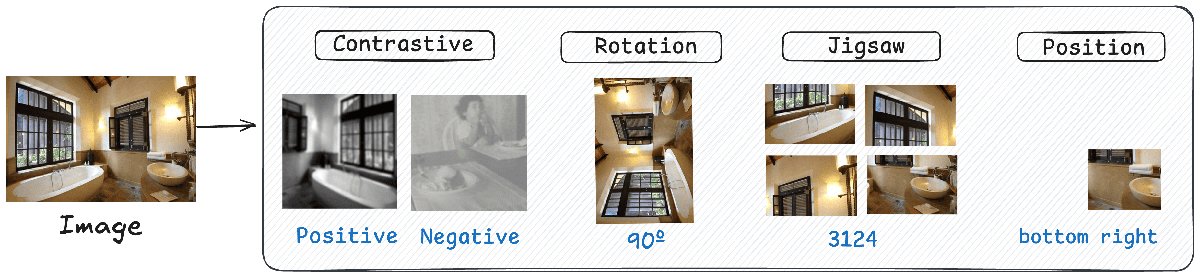
- 旋转预测 (Rotation Prediction): 图像被随机旋转一个角度 $y \in {0^\circ, 90^\circ, 180^\circ, 270^\circ}$。模型需要预测原始的旋转角度 $\hat{y}$。奖励为 $r=\mathbb{1}[\hat{y}=y]$。
- 拼图游戏 (Jigsaw): 图像被分割成网格(如2x2),然后打乱顺序。模型需要预测正确的排列顺序 $\hat{y}$。奖励为 $r=\mathbb{1}[\hat{y}=y]$。
- 对比学习 (Contrastive Learning): 对同一张图像生成多个增强视图(正样本)和其他图像的视图(负样本)。模型需要区分正负样本对。奖励 $r$ 模仿 InfoNCE 损失,鼓励正样本对的高相似度和负样本对的低相似度。
- 位置预测 (Position Prediction): 从图像的特定位置 $y$(如某个象限)提取一个图像块。模型需要根据这个图像块预测其在原图中的位置 $\hat{y}$。奖励为 $r=\mathbb{1}[\hat{y}=y]$。
优化策略
本文采用分组强化策略优化(Grouped Reinforcement Policy Optimization, GRPO)算法进行训练。该算法旨在最大化以下带正则化的目标函数:
\[\mathcal{J}(\theta)=\mathbb{E}_{\tau\sim\pi_{\theta}}\!\left[R(\tau)-\beta\,\mathrm{KL}\!\left(\pi_{\theta}(\cdot \mid \tau)\,\ \mid \,\pi_{0}(\cdot \mid \tau)\right)\right],\]其中,$R(\tau)$ 是从 SSL 任务中得到的奖励,$\pi_0$ 是一个参考策略(通常是 RL 训练前的模型),$\beta$ 是控制 KL 散度惩罚项强度的超参数。KL 散度项用于防止模型在训练过程中与原始行为偏离过远,从而稳定训练过程。GRPO 是 PPO 的一种变体,专为大批量的大语言模型训练进行了计算效率优化。
创新点
- 范式创新:SSL4RL 的核心创新在于重新利用(repurpose)自监督学习任务。传统上,SSL 被用作预训练阶段的表征学习工具;而 SSL4RL 则将其转化为后训练(对齐)阶段的可验证奖励源。它开创性地将表征学习与推理对齐两个过程联系起来。
- 无监督对齐:该方法最大的优点是实现了对 VLM 的有效对齐,而无需任何人工标注、人类偏好数据或外部验证器/评判器。它从数据本身挖掘监督信号,具有极高的可扩展性和经济性。
- 强化视觉基础:与传统的 RLHF 倾向于优化语言输出的“风格”和“帮助性”不同,SSL4RL 通过解决视觉谜题(如旋转、定位),直接迫使模型增强其视觉感知、空间理解和细节分辨能力,从而强化了模型的视觉基础(visual grounding)。
实验结论
实验在视觉语言推理和纯视觉分类任务上验证了 SSL4RL 的有效性。
视觉语言推理任务
在 MMBench 和 SEED-Bench 这两个多模态推理基准上,SSL4RL 带来了显著提升。
- 总体性能: SSL4RL 微调后的模型在 MMBench 上平均提升 7.39%,在 SEED-Bench 上平均提升 8.94%。特别是在 MMBench 的关系推理(Relation Reasoning)任务上提升了 39 个百分点,在 SEED-Bench 的视觉推理(Visual Reasoning)任务上提升了 19.63 个百分点。
| 模型 | 平均 | 常识推理 | 属性推理 | 关系推理 | 存在推理 | 场景推理 |
|---|---|---|---|---|---|---|
| Qwen-2.5-VL-3B-Instruct (Base) | 68.32 | 70.07 | 78.41 | 41.54 | 74.00 | 77.60 |
| SSL4RL (我们的方法) | ||||||
| 旋转 | 78.21 | 76.65 | 87.27 | 80.54 | 82.67 | 84.18 |
| 拼图 | 72.48 | 72.88 | 85.00 | 56.41 | 79.33 | 82.20 |
| 对比 | 69.27 | 70.38 | 80.91 | 55.13 | 75.33 | 77.01 |
| 位置 | 77.58 | 78.50 | 88.64 | 70.51 | 83.33 | 84.39 |
部分MMBench DEV-EN上的Qwen2.5-VL-3B-Instruct模型结果
| 模型 | 平均 | 属性识别 | 计数 | 位置推理 | 颜色识别 | 场景理解 |
|---|---|---|---|---|---|---|
| Qwen-2.5-VL-3B-Instruct (Base) | 60.10 | 69.22 | 47.79 | 62.43 | 74.49 | 57.08 |
| SSL4RL (我们的方法) | ||||||
| 旋转 | 66.80 | 74.15 | 53.64 | 69.57 | 81.39 | 63.82 |
| 拼图 | 62.13 | 70.62 | 48.96 | 65.65 | 76.99 | 58.73 |
| 对比 | 61.90 | 70.01 | 48.25 | 64.90 | 76.81 | 58.75 |
| 位置 | 69.04 | 77.10 | 55.71 | 71.79 | 82.35 | 65.69 |
部分SEED-Bench上的Qwen2.5-VL-3B-Instruct模型结果
- 任务对比: 位置预测 (Position) 和 旋转预测 (Rotation) 任务效果最好。位置预测迫使模型整合局部细节与全局布局,提升空间理解能力。旋转预测则通过呈现“反常识”的图像(物体非标准朝向),迫使模型摆脱语言先验,更深入地理解视觉内容。
- 失败案例: 标准的对比学习 (Contrastive) 任务表现不佳,甚至导致性能下降。研究者推测其默认的数据增强强度不足,导致模型仅学到表面不变性。
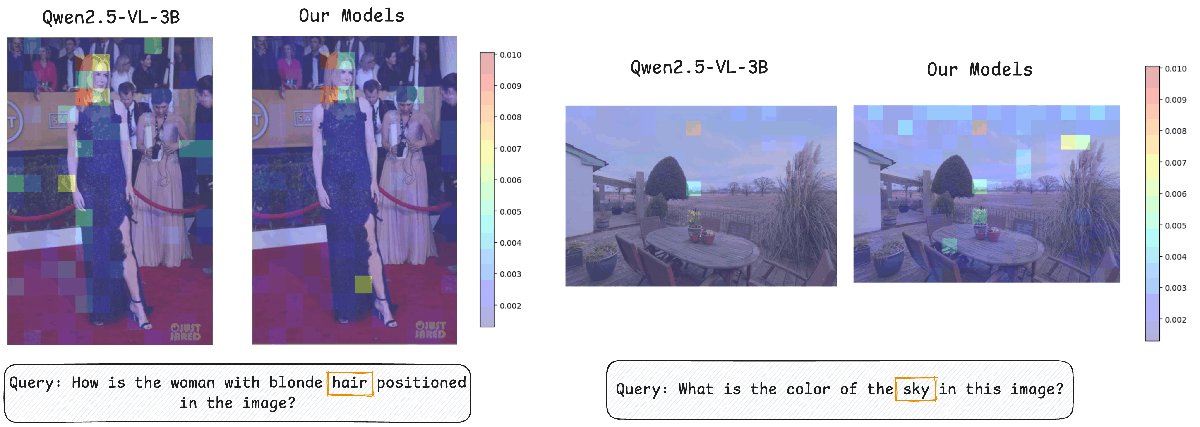
- 定性分析: SSL4RL 训练后的模型展现出更精准的注意力(如下图)和更少的对语言先验的依赖,倾向于基于真实的视觉证据作答。
消融研究
任务难度

- 提高 SSL 任务的难度(如增加拼图格数、增强对比学习的数据增强强度)对不同任务影响不同。
- 对于对比学习,增加难度(更强的增强)能显著提升性能,因为它迫使模型学习更鲁棒的特征。
- 对于本身就较难的拼图和旋转任务,过度增加难度可能导致负迁移,损害下游任务性能。
模型规模
- 在更大的 7B 模型上,SSL4RL 仍然有效,但性能增益相比 3B 模型有所减弱。
- 这可能是因为固定的 SSL 任务对于更大、能力更强的模型来说过于简单,无法构成有效挑战。这揭示了 SSL4RL 任务的设计需要与模型能力相匹配。
任务组合
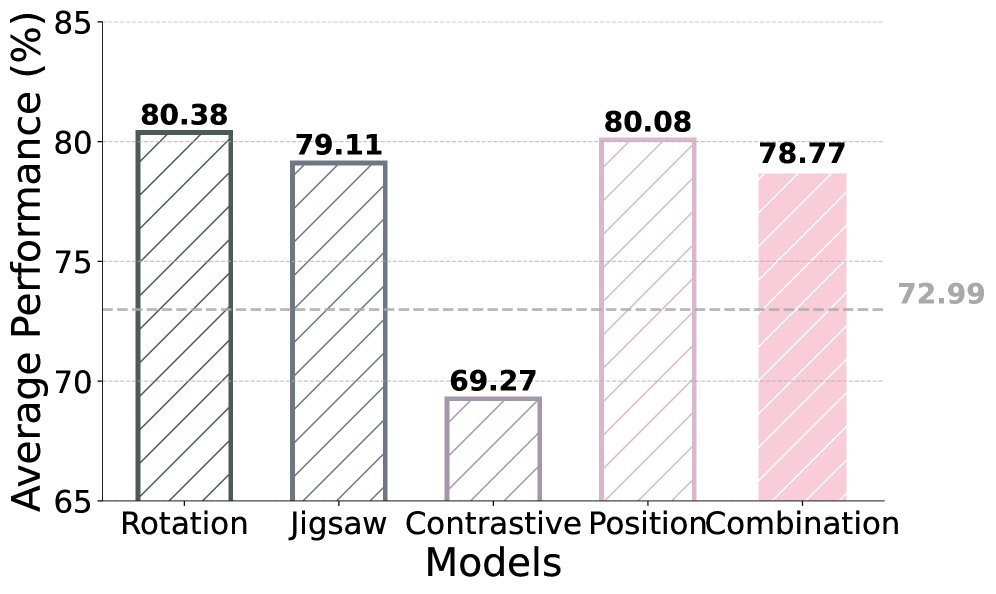
- 简单地将四种 SSL 奖励组合在一起进行训练,并没有比单一效果最好的任务(如旋转或位置)带来更显著的提升。
- 这表明不同任务可能引入冲突的学习信号,需要更复杂的组合策略(如动态加权、课程学习)才能实现协同效应。
视觉中心任务
在 ImageNet-1K 分类任务上,SSL4RL 同样提升了性能。有趣的是,在此任务上,对比学习任务表现出色。这表明 SSL 任务的选择应与下游任务的目标紧密相关:ImageNet 这类实例判别任务恰好受益于对比学习所培养的对增强不变的表征能力。
| 模型 | 直接回答 | 20选项 | 200选项 |
|---|---|---|---|
| Qwen-2.5-VL-3B-Instruct (Base) | 59.90 | 58.55 | 57.20 |
| SSL4RL (我们的方法) | |||
| 旋转 | 64.10 | 62.70 | 61.40 |
| 拼图 | 61.60 | 60.10 | 58.60 |
| 对比 | 67.40 | 66.80 | 65.52 |
| 位置 | 68.60 | 68.00 | 67.14 |
ImageNet-1K上的分类准确率 (%)
跨领域扩展:图学习
本文将 SSL4RL 框架成功扩展到图结构数据领域,通过属性遮蔽、邻居预测和链接预测等 SSL 任务,在节点分类和链接预测基准上取得了显著增益。这证明了 SSL4RL 作为一个通用范式的潜力。
| 任务 | 模型 | 平均增益 | Cora | PubMed | WikiCS | Products | fb15k237 | wn18rr |
|---|---|---|---|---|---|---|---|---|
| 节点分类 | ||||||||
| 3B | +13.79% | +24.47% | +8.78% | +8.12% | ||||
| 7B | +1.79% | +3.54% | +0.47% | +1.36% | ||||
| 链接预测 | ||||||||
| 3B | +8.49% | +3.04% | +7.37% | +15.06% | ||||
| 7B | +1.68% | +0.81% | +1.03% | +3.20% |
图学习任务上的性能增益
总结
本文证明了自监督学习任务可以作为一种丰富、可验证且可扩展的内在奖励来源,通过强化学习有效提升视觉语言模型的推理和对齐能力。这一发现为构建更安全、更强大的多模态基础模型开辟了一条新路径,统一了自监督学习和强化学习的优势,并减少了对昂贵的人工标注和不可靠的 AI 评判器的依赖。