Staircase Streaming for Low-Latency Multi-Agent Inference
-
ArXiv URL: http://arxiv.org/abs/2510.05059v1
-
作者: Xu; Ben Athiwaratkun; Jue Wang; Bhuwan Dhingra; Junlin Wang; James Zou; Ce Zhang
-
发布机构: Duke University; Stanford University; Together AI; University of Chicago
TL;DR
本文提出了一种名为“阶梯式流式传输 (Staircase Streaming)”的方法,通过让多智能体系统中的后续智能体(如聚合器)在接收到前序智能体(如提议者)的部分输出块(chunks)后便开始生成,而非等待其完整输出,从而将序贯依赖转变为流水线并行处理,显著降低了多智能体推理的首Token时间 (TTFT),同时基本保持了响应质量。
关键定义
本文提出或重点使用了以下核心概念:
- 阶梯式流式传输 (Staircase Streaming):一种为多智能体推理系统设计的低延迟策略。其核心思想是,系统中的智能体之间以“块 (chunk)”为单位流式传输生成内容。下游智能体无需等待上游智能体完成全部内容的生成,而是在收到第一个或后续的输出块后,立即开始处理和生成自己的输出,从而实现各智能体生成过程的并行化和流水线化,减少空闲等待时间。
- 首Token时间 (Time to First Token, TTFT):衡量交互式应用延迟的关键指标,指从用户发送请求到接收到模型生成的第一个token所需的时间。本文的主要优化目标就是降低多智能体系统中的TTFT。
- 块 (Chunk):在阶梯式流式传输中,模型生成的文本被分割成的基本单元。上游智能体生成一个块就立即发送给下游智能体。块的大小是一个关键超参数,它平衡了延迟和计算效率。
相关工作
当前,利用多个大型语言模型(LLM)进行协作的“多智能体推理”研究(如Mixture-of-Agents, Multi-Agent Debate)已成为提升响应质量和一致性的前沿方向。这些方法通过引入额外的推理步骤(如多个提议、多轮辩论)来整合多个LLM的“集体智慧”,其性能常能超越单个最先进的模型。
然而,这些方法的关键瓶颈在于其固有的高延迟。后续的推理步骤必须等待所有前序步骤完全生成中间输出后才能开始,导致首Token时间 (TTFT) 大幅增加。对于聊天机器人等需要实时响应的应用,长达数秒甚至数十秒的延迟严重影响用户体验。
因此,本文旨在解决的核心问题是:如何在不牺牲多智能体推理带来的质量提升的前提下,显著降低其推理延迟,特别是TTFT?
本文方法
方法核心思想
本文提出的阶梯式流式传输旨在打破多智能体推理中严格的序贯依赖,代之以一种流水线式的执行模式。其核心思想是:下游智能体(如聚合器)不必等待上游智能体(如提议者)生成完整的响应,而是在收到来自上游智能体的第一个文本块(chunk)后,便立即开始生成最终响应。
该方法的直觉基于两个观察:
- 部分输出已包含足够信息:即使是部分生成的文本,也已经能为下游LLM提供有价值的、多样化的观点。
- 关键信息前置:LLM的响应通常会将核心观点放在开头,后续内容多为对核心观点的阐释、举例或补充。
 上图(a)展示了在常规流式传输中,聚合器必须等待最慢的提议者完成全部生成后才能开始工作,导致TTFT很长。而(b)展示了阶梯式流式传输,聚合器在收到各提议者的第一个输出块后便开始生成,实现了提议者和聚合器之间的并行处理,从而大幅缩短了TTFT。
上图(a)展示了在常规流式传输中,聚合器必须等待最慢的提议者完成全部生成后才能开始工作,导致TTFT很长。而(b)展示了阶梯式流式传输,聚合器在收到各提议者的第一个输出块后便开始生成,实现了提议者和聚合器之间的并行处理,从而大幅缩短了TTFT。
基于MoA的实现
以混合智能体(Mixture-of-Agents, MoA)框架为例,阶梯式流式传输的实现如下:
- 并行提议:多个提议者(Proposers)$P_1, …, P_N$ 并行接收用户问题 $Q$,并开始生成各自的响应。
- 分块传输:每个提议者 $P_i$ 生成一小块文本 $R_{i,1}$ 后,不是继续生成,而是立即将这个块发送给聚合器(Aggregator)$A$。
- 早期聚合:聚合器 $A$ 在收到所有(或指定数量)提议者的第一块输出 ${R_{1,1}, …, R_{N,1}}$ 后,将它们整合进自己的提示(prompt)中,并开始生成最终答案的第一个块 $S_1$。
- 流水线执行:在聚合器生成 $S_1$ 的同时,提议者们也在并行地生成它们的第二个块 $R_{i,2}$。当聚合器完成 $S_1$ 后,它会等待接收新的块 ${R_{1,2}, …, R_{N,2}}$,更新其提示,然后生成第二个答案块 $S_2$。这个过程不断重复,形成了一种计算重叠的“阶梯式”流水线。
创新点及优点
本文方法的核心创新在于打破了智能体间严格的串行依赖,实现了流水线式的并行处理。
其最显著的优点是大幅降低TTFT。TTFT的计算公式从依赖于最慢提议者的总生成时间,转变为仅依赖于其第一个块的生成时间:
\[\text{TTFT}_{\text{normal}} = \max_{1\leq i\leq N}\left(\sum_{j=1}^{\text{eos}}T_{R_{i,j}}\right)+T_{\text{prefill}}\] \[\text{TTFT}_{\text{staircase}} = \max_{1\leq i\leq N}\left(T_{R_{i,1}}\right)+T_{\text{prefill}}\]其中 $T_{R_{i,j}}$ 是提议者 $i$ 生成第 $j$ 个块的时间,$T_{\text{prefill}}$ 是聚合器处理初始输入所需的时间。由于第一个块 $R_{i,1}$ 的生成时间远小于总生成时间,TTFT得以显著降低。
前缀缓存优化 (Prefix-Caching Optimized)
为了进一步提升效率,本文还提出了一种利用前缀缓存(Prefix-Caching)的优化变体。在标准的阶梯式流式传输中,聚合器每次收到新块时都需要重新处理其增长的提示。而通过前缀缓存技术,聚合器可以重用之前已计算过的提示部分的键值对(KV cache),只需增量处理新收到的文本块。这种方法虽然可能使聚合器 prompt 中来自同一提议者的内容变得不连续,但能节省大量重计算开销,进一步提升吞吐量(TPS)。
实验结论
实验在Arena-Hard和AlpacaEval等基准上进行,将阶梯式流式传输应用于MoA和MAD两种主流多智能体框架。
核心实验结果
| 方法 | ArenaHard 胜率 | AlpacaEval LC Win | TTFT (秒) | TPS (tokens/秒) |
|---|---|---|---|---|
| Gemma-2-9B-IT (基线) | 40.6 | 48.5 | 0.06 | 69.4 |
| MAD | 50.8 | 55.8 | 6.70 | 35.9 |
| + staircase | 45.9 | 55.2 | 0.45 | 44.7 |
| MoA | 47.5 | 56.8 | 10.6 | 28.3 |
| + staircase | 48.3 | 55.1 | 0.47 | 43.4 |
| + staircase & prefix-cache | 46.9 | 53.0 | 0.45 | 45.0 |
- 效率验证:阶梯式流式传输取得了显著的效率提升。与原始的MoA和MAD相比,TTFT降低了高达93%,同时端到端吞吐量(TPS)提升了高达1.6倍。
- 质量保持:在大幅降低延迟的同时,响应质量(以基准测试胜率衡量)与原始的多智能体方法基本持平,仅有轻微、可接受的下降。这证明了该方法在效率和质量之间取得了优异的平衡。
- 通用性:该方法在MoA和MAD上均表现出色,证明了其作为一种通用优化策略的潜力。
- 前缀缓存优化:该变体在TTFT相似的情况下,进一步提升了TPS,但胜率有轻微降低,为用户提供了不同场景下的性能权衡选项。
其他发现
-
扩展性:该方法可以有效扩展到更大规模的模型(如70B、110B系列)。在大型模型上的实验显示,阶梯式MoA不仅保持了较低的TTFT,其响应质量也远超单个最佳的大模型。
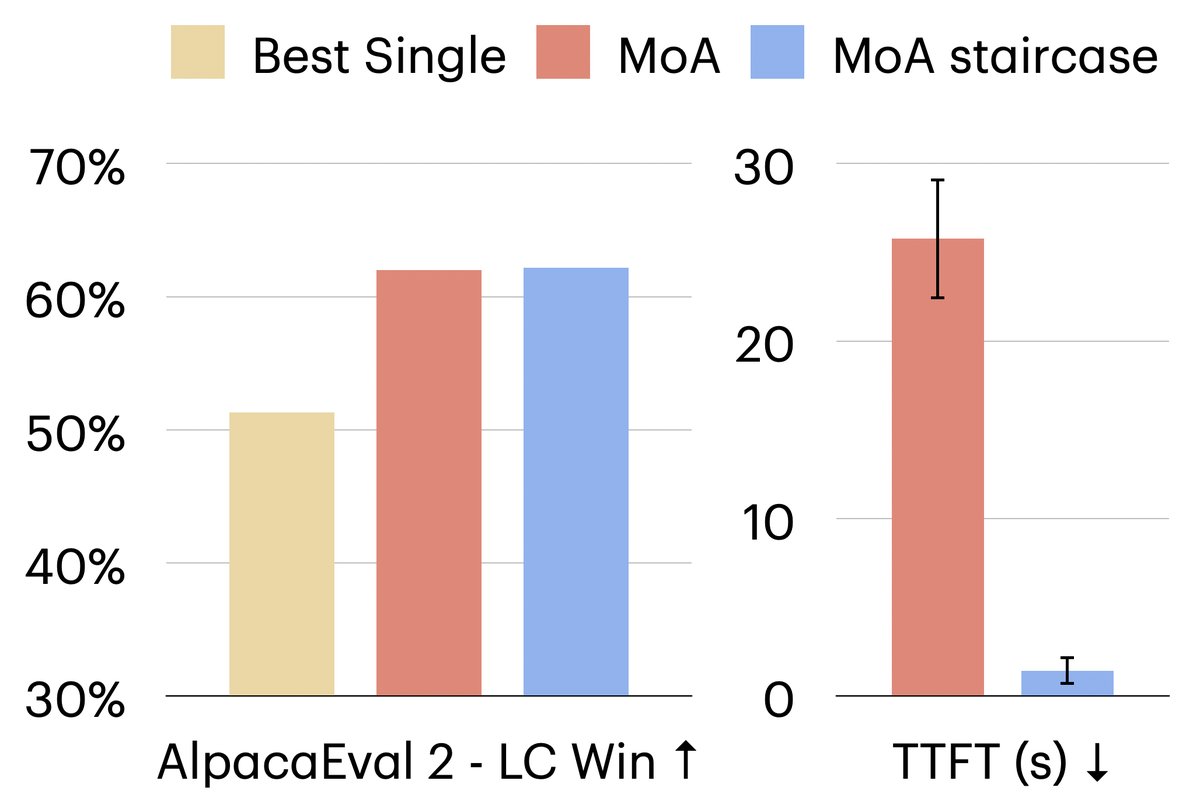
-
超参数影响:第一个块的大小是影响TTFT和最终质量的关键超参数。实验表明,块太小(如4个token)会略微影响质量,块太大则会增加TTFT。在本次实验中,初始块大小为8个token时,在质量和延迟之间取得了最佳平衡。
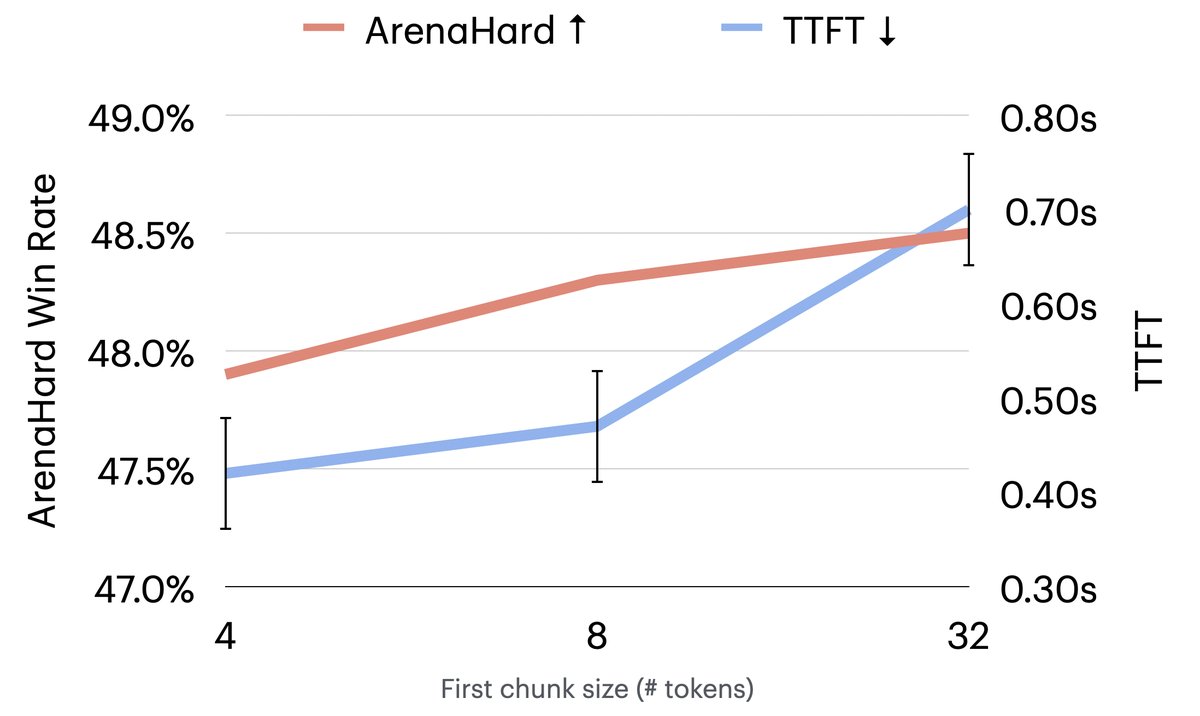
最终结论
本文成功证明了阶梯式流式传输是一种简单而高效的策略,它通过将多智能体系统中的序贯推理转变为流水线并行处理,能够在几乎不牺牲响应质量的前提下,极大地降低推理延迟,解决了多智能体系统在实时应用中的一个核心痛点。