Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First
-
ArXiv URL: http://arxiv.org/abs/2509.00997v1
-
作者: Matei Zaharia; Shubham Agarwal; Alan Zhu; Ion Stoica; Aditya G. Parameswaran; Joseph E. Gonzalez; Ruiqi Chen; Alvin Cheung; Shreya Shankar; Shu Liu; 等12人
-
发布机构: University of California, Berkeley
TL;DR
本文指出,未来的数据系统将主要服务于由大型语言模型(LLM)驱动的智能体,并提出了一种“智能体优先”(agent-first)的数据系统新架构,以高效处理智能体工作负载中普遍存在的高吞吐量、异构、冗余和可引导的“智能体推测”(agentic speculation)过程。
关键定义
- Agentic Speculation (智能体推测):指智能体为完成给定数据任务而进行的高吞吐量探索和解决方案构建过程。它包含大量为了解数据(即获得“根基” (grounding))而发出的探索性、甚至可能是浪费的查询,以及对部分或完整解决方案的尝试与验证。
- Probes (探针):本文提出的用于替代传统“查询” (queries) 的新概念。探针不仅包含SQL等具体操作指令,还附带了关于请求背景的元信息,例如智能体所处的阶段(元数据探索或方案构建)、意图、所需精度、优先级等。这些信息有助于数据系统更智能地进行优化。
- Briefs (简报):在探针中以自然语言形式提供的陈述,用于描述探针的目标、意图、近似需求和其他开放式信息。数据系统内的智能体解释器会利用简报来指导优化和执行。
- Agentic Memory Store (智能体记忆存储):一种持久化、可查询的语义缓存,用于存储先前探针获得的根基信息,如查询结果、部分解决方案、数据和元数据的语义信息。其目的是让智能体能够复用已知信息,提高后续探索的效率。
相关工作
当前的数据系统主要为两种工作负载设计:由人类驱动的、较为间歇的分析查询,或由终端应用程序驱动的、目标明确的请求。然而,随着大型语言模型(LLM)变得越来越强大和廉价,由LLM智能体代表用户操作数据将成为主导性的工作负载。
这些智能体虽然推理能力强,但缺乏对底层数据和系统特性的先天“根基”。它们通过不知疲倦地尝试各种可能性来弥补这一点,这一过程被称为“智能体推测”。这种推测行为会产生巨大规模、高度冗余且效率低下的查询,对现有数据系统构成了巨大挑战,现有系统并未针对这种工作负载进行优化,其巨大的规模和低效性将成为性能瓶颈。
本文旨在解决的核心问题是:如何重新设计数据系统,使其能够原生且高效地支持智能体工作负载,特别是“智能体推测”过程,从而帮助LLM智能体更高效地确定最佳行动方案。
本文方法
本文提出了一种“智能体优先”的数据系统架构愿景,其核心创新在于改变了数据系统与用户(智能体)的交互范式,从被动响应查询转变为主动引导和协同优化。
智能体优先的数据系统架构
该架构的核心组件如下图所示,旨在利用智能体推测的四大特性:规模性(scale)、异构性(heterogeneity)、冗余性(redundancy)和可引导性(steerability)。
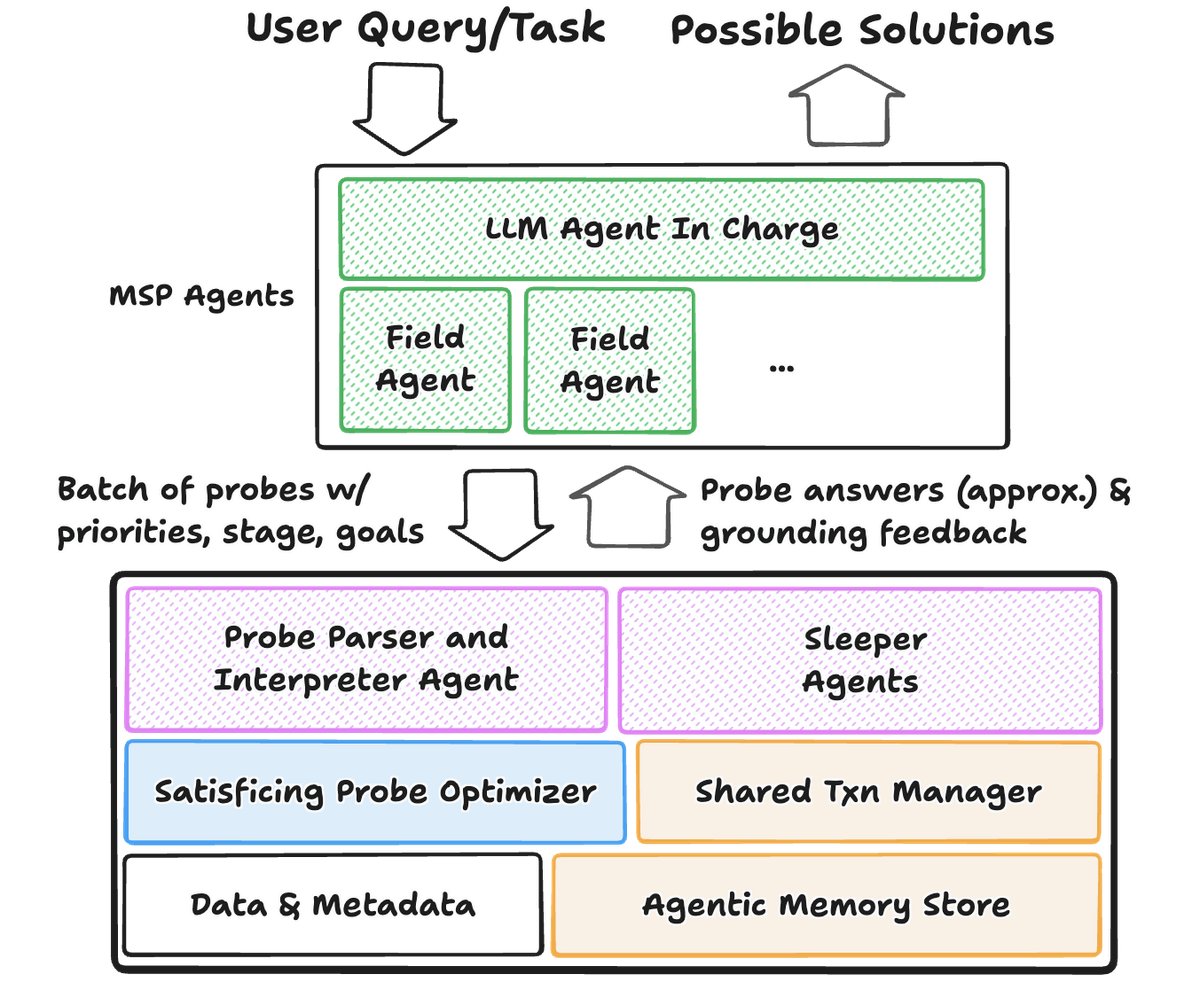
该架构主要包括:
- 查询接口:智能体发出“探针”(Probes),其中包含SQL以及描述意图和需求的“简报”(Briefs)。系统不仅返回答案,还通过“睡眠智能体”(sleeper agents)主动提供“根基反馈”(grounding feedback)来引导智能体。
- 探针解释与优化器:系统内的“智能体解释器”(Agentic Interpreter)解析探针和简报。而后,“探针优化器”(Probe Optimizer)的目标不再是完美执行每个查询,而是“满意化”(satisfice),即在满足智能体当前步骤需求的前提下,通过近似查询处理(Approximate Query Processing)和多查询优化(Multi-query Optimization)等技术,最小化总处理时间。
- 存储与事务层:引入“智能体记忆存储”(Agentic Memory Store)作为语义缓存,保存探索成果。同时,设计了新的“共享事务管理器”(Shared Transaction Manager),以高效处理多分支、高冗余的假设性更新(what-if updates),支持大规模并行分叉和快速回滚。
创新点
本文方法与传统数据系统的本质区别在于,它将智能体视作一等公民,并围绕其工作特性进行全新设计。
- 从被动响应到主动引导:传统系统被动地精确回答查询。本文提出的系统则能理解智能体的意图(通过探针和简报),并主动提供上下文提示、成本估算和优化建议,从而“引导”智能体走向更高效的探索路径。
- 以“满意”为优化目标:优化目标从最小化单次查询延迟或最大化吞吐量,转变为最小化完成整个智能体任务的总时间。这意味着系统可以为了长远效率而选择执行近似查询、修剪冗余探针,或在探索早期提供粗粒度结果。
- 为推测而生的并发模型:传统的事务模型强调隔离。本文提出的模型则专为推测服务,支持大规模、廉价的状态分叉(forking)和回滚。它利用分支间的相似性来共享状态和计算,而不是为每个假设都创建完整隔离的副本,实现了“类固醇版的多版本并发控制(MVCC on steroids)”。
查询接口
- 从智能体到数据系统:智能体通过\(探针\)与系统交互。探针中的\(简报\)允许智能体用自然语言表达其目标、所处阶段(如元数据探索)、近似需求等。此外,接口支持超越SQL的语义相似性搜索等灵活操作,以帮助智能体在不清楚数据结构时进行探索。
- 从数据系统到智能体:系统不再仅仅返回查询结果,而是主动提供两类反馈来\(引导\)智能体:
- 辅助信息:如发现相关的其他表、解释空结果的原因(类似why-not provenance)等。
- 成本反馈:提供查询的预估成本,建议修改查询范围或批处理请求以提高效率。
探针处理与优化
- 支持探索:优化器能够识别并优先处理探索性查询,并利用\(智能体记忆存储\)避免重复的元数据查询。
- 探针内优化(Intra-Probe Optimization):在处理一批探针时,优化器基于简报中的意图和成本估算,决定运行哪些查询、近似到何种程度,并利用多查询优化技术共享计算。
- 探针间优化(Inter-Probe Optimizations):跨越多个交互轮次,系统通过观察查询历史和智能体意图来优化决策,例如,通过缓存或物化频繁使用的中间结果来加速未来的探针。
索引、存储与事务
- 智能体记忆存储:这是一个持久化的语义缓存,存储先前探索中发现的有用信息,如数据编码格式、时间粒度、有效的查询模式等,供后续探针直接或间接使用。
- 分支更新(Branched Updates):为支持智能体探索多个“what-if”假设,该系统需要一个新的事务框架。该框架的核心是\(多世界隔离\)(multi-world isolation),即逻辑上隔离每个假设分支,但在物理上尽可能共享存储。这要求极高效的分叉(forking)和回滚(rollbacks)机制,远超传统数据库的能力。
实验结论
本文通过两个案例研究验证了“智能体推测”工作负载的关键特性,并证明了其设计理念的合理性。
- BIRD (text2SQL) 数据集研究:
- 有效性:无论是并行还是串行增加智能体的尝试次数,任务的成功率都显著提高(14%-70%),证明了智能体推测的“规模性”有助于提升准确率。
- 冗余性:在50次独立的并行尝试中,不同大小的子查询计划的独立数量仅占总数的10-20%,揭示了巨大的计算共享潜力。
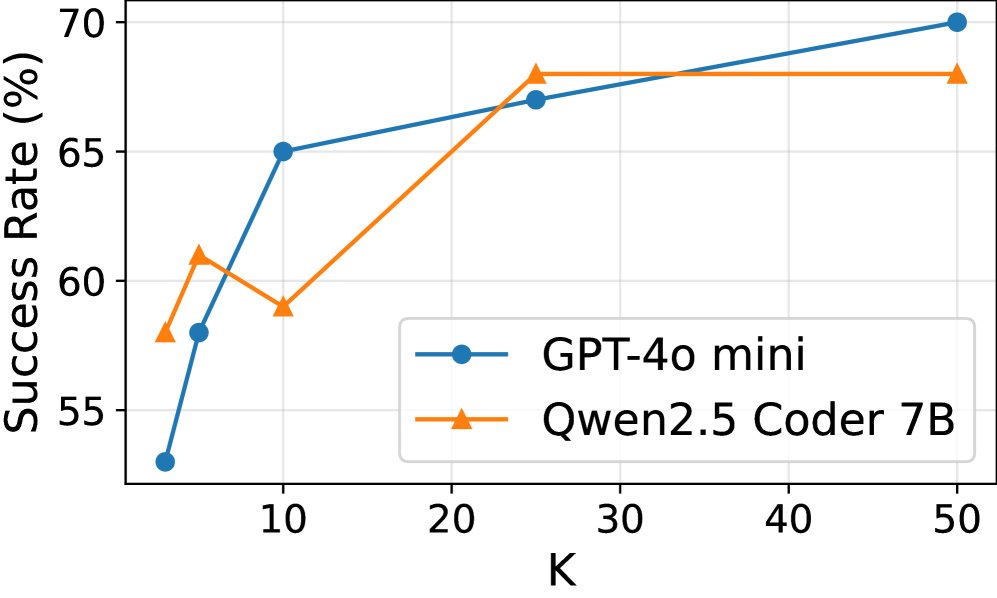 (a) 成功率 vs. 尝试次数 (K)
(a) 成功率 vs. 尝试次数 (K)
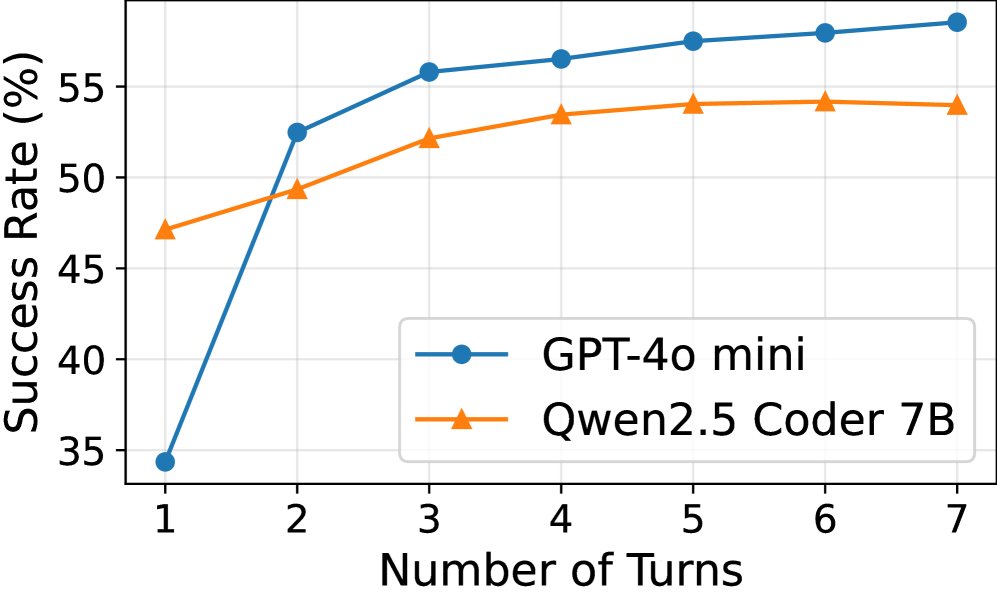 (b) 成功率 vs. 交互轮次
(b) 成功率 vs. 交互轮次
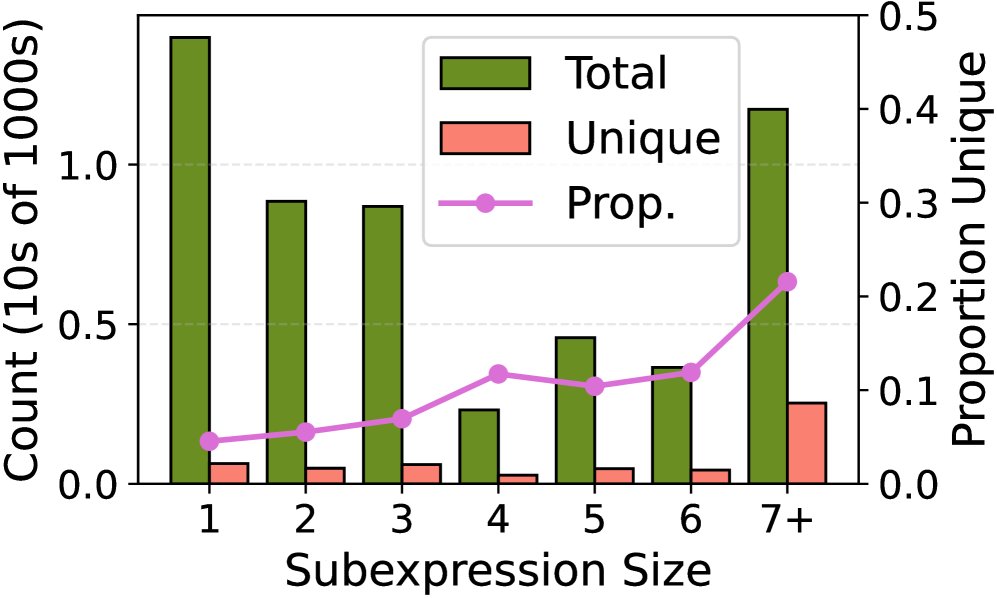 (a) 按子表达式大小
(a) 按子表达式大小
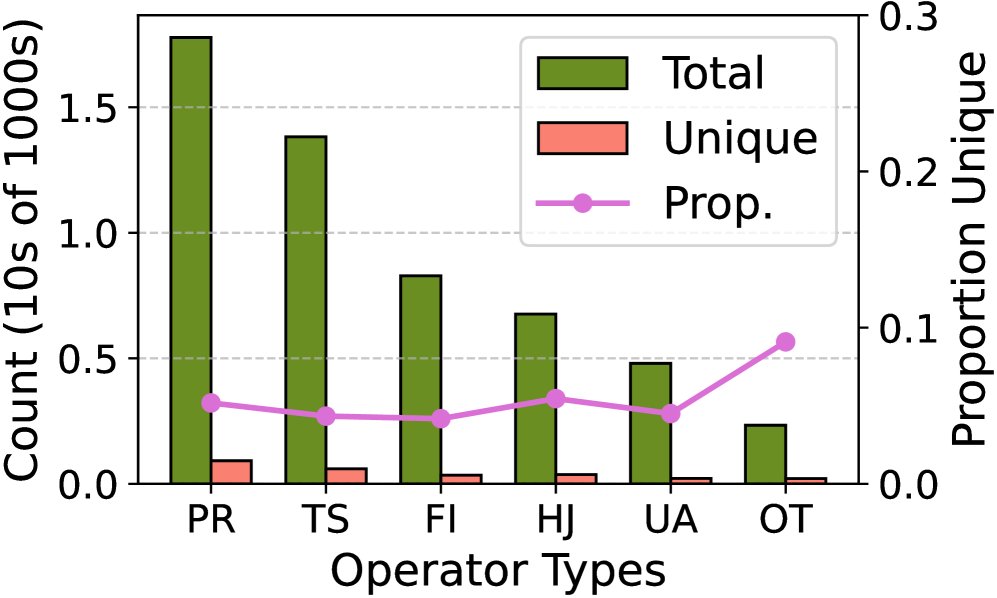 (b) 按根操作类型
(b) 按根操作类型
- 跨数据库数据整合任务研究:
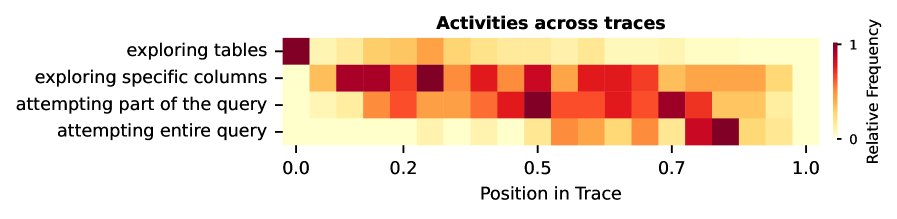
- 异构性:智能体的行为轨迹清晰地显示出不同阶段:早期主要进行元数据和样本数据探索,随后是统计信息查询,最后进入部分或完整解决方案的构建,证实了智能体推测需求的“异构性”。
- 可引导性:通过向智能体提供专家提示(模拟系统提供的“根基”),完成任务所需的SQL查询总数平均减少了18.1%,部分查询类型的减少幅度高达36.6%。这表明智能体推测是“可引导的”,主动提供信息能显著提升效率。
| 活动 | 平均次数 (无提示) | 平均次数 (有提示) | 减少比例 (%) |
|---|---|---|---|
| 探索表 | 3.44 | 2.95 | -14.2 |
| 探索特定列 | 3.56 | 2.57 | -27.7 |
| 尝试部分查询 | 4.28 | 2.71 | -36.6 |
| 尝试完整查询 | 1.26 | 1.05 | -16.6 |
| 所有SQL查询 | 12.67 | 10.38 | -18.1 |
最终结论:实验结果有力地证明了智能体工作负载具有规模性、冗余性、异构性和可引导性等独特特征。这些特征使得现有数据系统难以高效应对,同时也为新一代“智能体优先”的数据系统架构提供了明确的优化方向和机遇。