SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
-
ArXiv URL: http://arxiv.org/abs/2310.06770v3
-
作者: Karthik Narasimhan; Alexander Wettig; Ofir Press; John Yang; Kexin Pei; Carlos E. Jimenez; Shunyu Yao
-
发布机构: Princeton University; University of Chicago
TL;DR
本文提出了一个名为 SWE-bench 的大规模、真实世界的软件工程基准,通过要求语言模型(Language Models, LMs)解决来自12个流行Python仓库的真实GitHub问题,发现即使是最先进的模型也难以完成这些复杂的代码编辑任务,揭示了当前模型能力的巨大局限性。
关键定义
本文提出了一个核心基准,并在此基础上构建了评估体系:
- SWE-bench: 一个评估框架,包含 2294 个软件工程问题。每个问题实例由一个真实的 GitHub 问题(Issue)描述和一个完整的代码仓库(codebase)快照组成。模型的任务是生成一个代码补丁(patch),以解决该问题并通过相关的单元测试。
- Fail-to-pass Test: 本文在构建基准时使用的一个关键筛选标准。指的是在应用解决方案补丁之前会失败、但在应用之后会通过的测试用例。这确保了每个任务都有明确、可验证的解决方案,且解决方案确实解决了指定的问题。
相关工作
- 研究现状与瓶颈: 当前的语言模型在许多基准上已达到饱和,但这些基准(如HumanEval)往往是为评估目的而人为设计的、自成一体的小型编程问题。它们无法反映真实世界软件工程的复杂性,例如需要导航大型代码库、理解跨多个文件和类的代码交互,以及处理冗长的上下文。
- 本文待解决的问题: 本文旨在创建一个更具挑战性、更贴近现实的基准,以评估下一代语言模型在真实软件工程场景中的能力。具体来说,本文要探索语言模型是否能从一个问题描述出发,在整个代码仓库的范围内进行复杂的代码编辑,以修复错误或实现新功能,而不仅仅是生成独立的代码片段。
本文方法
SWE-bench 基准构建
本文的核心方法论是其基准的构建流程,该流程旨在从海量的开源项目中自动化地筛选出高质量、可评估的任务实例。整个流程分为三个阶段:
 图1: SWE-bench任务实例的构建流程,从合并的拉取请求中筛选,要求其解决一个问题、贡献了测试并且能成功安装。
图1: SWE-bench任务实例的构建流程,从合并的拉取请求中筛选,要求其解决一个问题、贡献了测试并且能成功安装。
-
阶段一:仓库选择与数据抓取 (Repo selection and data scraping): 从 12 个流行的 Python 开源 GitHub 仓库中抓取了约 90000 个拉取请求(Pull Requests, PRs)。选择流行仓库是因为它们通常有更好的维护、清晰的贡献指南和更高的测试覆盖率。
-
阶段二:基于属性的过滤 (Attribute-based filtering): 对 PRs进行初步筛选,保留同时满足以下两个条件的候选任务:(1) PR 明确地解决了一个 GitHub 问题;(2) PR 修改了仓库的测试文件,这表明开发者很可能为验证修复或新功能编写了新的测试。
-
阶段三:基于执行的过滤 (Execution-based filtering): 对每个候选任务进行验证。首先,仅应用 PR 中对测试文件的修改,运行测试并记录失败的测试用例。然后,应用 PR 中对代码文件的修改,再次运行测试。只有当至少存在一个“fail-to-pass”测试时(即从失败变为通过),该任务实例才被保留。此步骤确保了每个任务都有一个可靠的、可自动验证的评估标准。
经过这三层过滤,最终得到了包含 2294 个任务实例的 SWE-bench。
SWE-bench 任务形式与特点
- 任务形式:
- 输入 (Input): 一个问题描述文本和一个完整的代码库。
- 输出 (Output): 一个以 \(diff\) 格式表示的代码补丁文件,描述了为解决问题所需对代码库进行的修改。
- 评估 (Evaluation): 系统会自动应用模型生成的补丁,并运行与该任务关联的单元测试。如果补丁成功应用且所有相关测试通过,则认为模型成功解决了该问题。最终指标是“解决率”(Resolved %)。
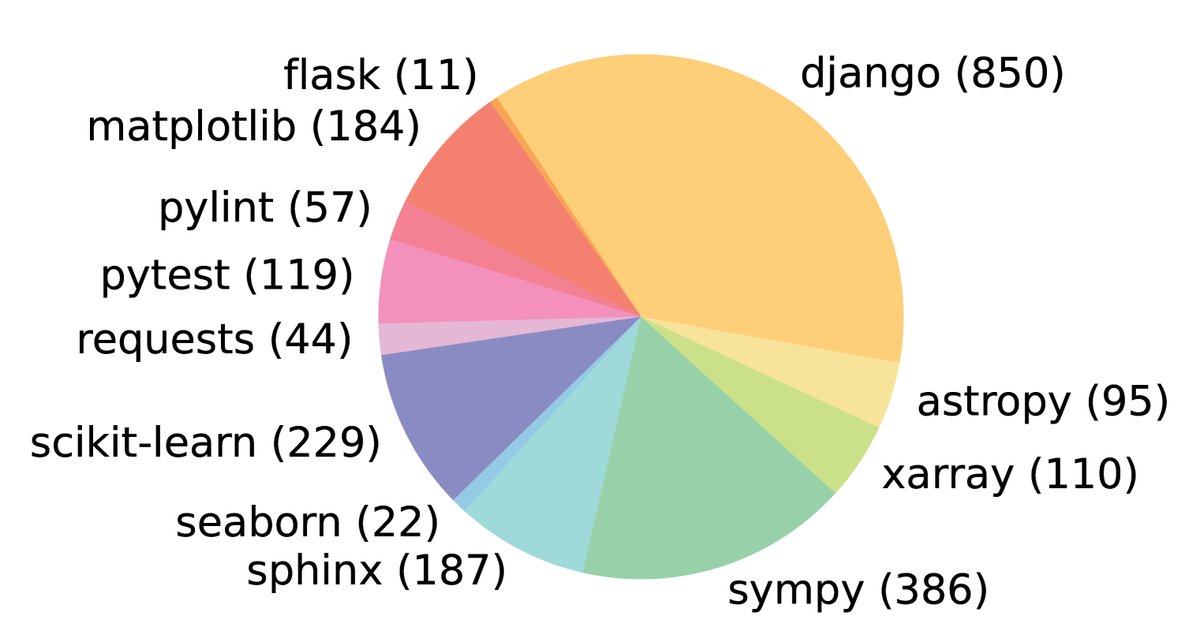 图2: SWE-bench 任务在12个开源GitHub仓库中的分布。
图2: SWE-bench 任务在12个开源GitHub仓库中的分布。
- 核心特点:
- 真实世界任务: 任务来源于真实的用户报告和开发者解决方案,涉及复杂且庞大的代码库。
- 可持续更新: 构建流程自动化程度高,可以轻松扩展到新的仓库或持续引入新的问题,有效避免了模型训练数据污染问题。
- 多样的长输入: 问题描述平均长度为 195 个单词,代码库平均包含 43.8 万行代码,要求模型具备在海量上下文中定位和推理的能力。
- 鲁棒的评估: 每个任务都包含用于验证问题是否被解决的 \(fail-to-pass\) 测试,以及大量用于检查是否引入新错误的回归测试。
- 跨上下文代码编辑: 解决方案平均需要编辑 1.7 个文件和 3.0 个函数,挑战模型进行多点、跨文件协作修改的能力。
| 属性 | 类别 | 平均值 | 最大值 |
|---|---|---|---|
| 问题文本 | 长度 (词) | 195.1 | 4477 |
| 代码库 | 文件数 (非测试) | 3,010 | 5,890 |
| 代码行数 (非测试) | 438K | 886K | |
| 黄金补丁 | 编辑行数 | 32.8 | 5888 |
| 编辑文件数 | 1.7 | 31 | |
| 编辑函数数 | 3.0 | 36 | |
| 测试 | Fail to Pass 数 | 9.1 | 1633 |
| 总计测试数 | 120.8 | 9459 |
表1: SWE-bench 任务实例的各项属性统计。
SWE-bench Lite
为了方便研究者快速上手和迭代,本文还提供了一个轻量级子集 SWE-bench Lite,包含 300 个从原数据集中采样的、相对更独立的任务实例,主要关注功能性 bug 的修复。
SWE-Llama 模型
为了评估开源模型在该任务上的能力,本文对 CodeLlama 模型进行了微调,推出了 SWE-Llama。
- 动机: 标准的 CodeLlama 模型无法很好地遵循 SWE-bench 复杂的指令来生成代码库级别的编辑。
- 训练数据: 从另外 37 个与测试集不重叠的 Python 仓库中收集了 19000 个问题-PR对。
- 微调方法: 采用监督式微调,输入为问题文本和“神谕”(oracle)检索出的相关代码文件,目标是生成与真实 PR 一致的“黄金补丁”。为提高效率,使用了 LoRA 技术,并且只训练了注意力子层的权重。
实验结论
实验设置
由于代码库远超模型的上下文窗口,本文采用了一种基于检索的方法来构建模型输入。
- 稀疏检索 (Sparse Retrieval): 使用 BM25 算法根据问题描述检索最相关的代码文件作为上下文。
- “神谕”检索 (Oracle Retrieval): 作为分析的上限,直接将真实解决方案中被修改过的文件提供给模型。这在现实中不可行,但有助于分析检索系统对最终性能的影响。
评估的模型包括 Claude 2、ChatGPT-3.5、GPT-4 以及本文微调的 SWE-Llama 7b 和 13b。
核心实验结果
1. 现有模型性能极低,任务极具挑战性。
- 在最贴近现实的 BM25 检索设置下,所有模型都表现不佳。表现最好的 Claude 2 也仅解决了 1.96% 的问题。这表明解决真实世界的软件工程问题对于当前最先进的语言模型来说仍然是一个巨大的挑战。
| 模型 | SWE-bench (% Resolved) | SWE-bench (% Apply) | SWE-bench Lite (% Resolved) | SWE-bench Lite (% Apply) |
|---|---|---|---|---|
| Claude 3 Opus | 3.79 | 46.56 | 4.33 | 51.67 |
| Claude 2 | 1.97 | 43.07 | 3.00 | 33.00 |
| ChatGPT-3.5 | 0.17 | 26.33 | 0.33 | 10.00 |
| GPT-4-turbo | 1.31 | 26.90 | 2.67 | 29.67 |
| SWE-Llama 7b | 0.70 | 51.74 | 1.33 | 38.00 |
| SWE-Llama 13b | 0.70 | 53.62 | 1.00 | 38.00 |
表2: 各模型在使用BM25检索器时的性能对比。% Resolved 指成功解决问题的比例,% Apply 指生成的补丁能成功应用的比例。
2. 检索质量和上下文长度是关键瓶颈。
- 在“神谕”检索设置下,Claude 2 的解决率提升至 4.8%,这说明检索的准确性至关重要。
- 然而,即使提供更多上下文(增加 BM25 检索的 token 限制),模型性能反而下降。如下图所示,随着输入总长度的增加,模型性能显著降低,这证实了“大海捞针”问题:模型容易被大量不相关的上下文干扰,难以定位到需要修改的关键代码。
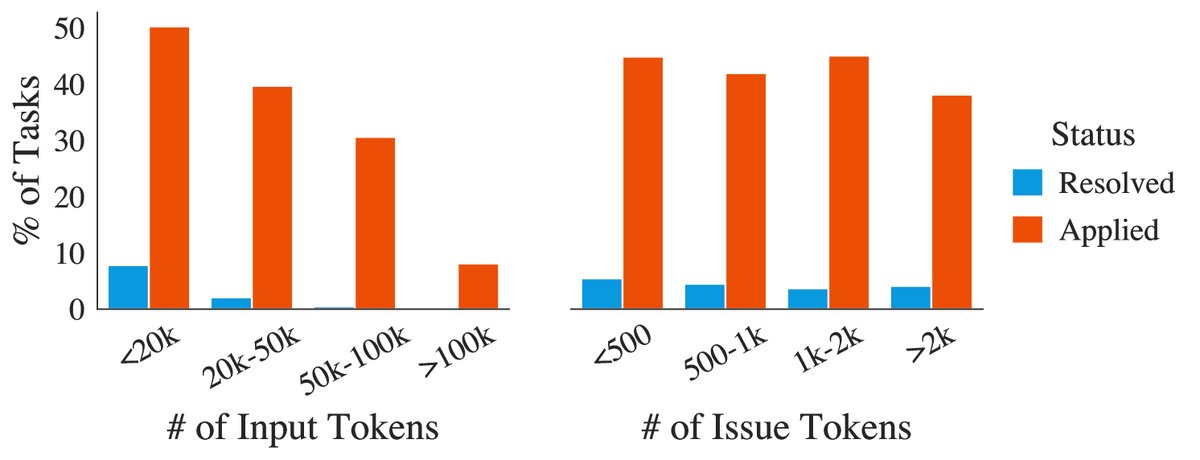 图3: Claude 2 的性能随着输入总长度的增加而下降,但与问题描述本身的长度关系不大。
图3: Claude 2 的性能随着输入总长度的增加而下降,但与问题描述本身的长度关系不大。
3. 模型生成的解决方案更简单。
- 与人类编写的“黄金补丁”相比,模型成功生成的补丁通常更短、修改的文件更少。这表明模型目前只能处理相对简单、局部化的修改,难以进行结构性的、涉及多文件的复杂重构。
| 模型 | 总行数 | 添加行数 | 删除行数 | 函数数 | 文件数 |
|---|---|---|---|---|---|
| Claude 2 | 19.6 | 4.2 | 1.9 | 1.1 | 1.0 |
| 黄金补丁 (对应) | 44.1 | 12.0 | 5.8 | 2.1 | 1.2 |
| 所有黄金补丁 | 74.5 | 22.3 | 10.5 | 3.0 | 1.7 |
表3: 模型生成的成功补丁与黄金补丁的平均编辑统计对比(在“神谕”检索设置下)。
4. 质性分析揭示了模型的“贪心”和“原始”行为。
- 通过案例分析发现,即使模型定位到正确的函数,也倾向于采用最直接、最简单的逻辑修复问题,而忽略了代码库中已有的设计模式、配置选项或代码风格。它们生成的代码更像是“原始”的 Python 代码,而没有很好地利用项目自身的库和抽象。
最终结论
真实世界的软件开发远比简单的代码补全复杂。SWE-bench 通过模拟真实的开源协作流程,为评估和发展语言模型提供了一个忠实且极具挑战性的环境。实验结果表明,当前最先进的语言模型在解决实际软件工程问题方面仍处于起步阶段,在代码定位、长上下文理解和复杂推理方面存在巨大提升空间。本文希望该基准能够推动未来语言模型向着更实用、更智能、更自主的方向发展。