SynthDrive: Scalable Real2Sim2Real Sensor Simulation Pipeline for High-Fidelity Asset Generation and Driving Data Synthesis
-
ArXiv URL: http://arxiv.org/abs/2509.06798v1
-
作者: Yubin Hu; Qian Zhang; Wei Yin; Ruohong Mei; Weiqiang Ren; Xiaoyang Guo
-
发布机构: Horizon Robotics; Tsinghua University
TL;DR
本文提出了 SynthDrive,一个可扩展的“真实-仿真-真实 (real2sim2real)”数据流,它通过从单张图片自动挖掘并生成高保真度的3D资产,用于合成自动驾驶中的罕见场景(corner-case)数据,以提升感知模型的性能。
关键定义
- SynthDrive: 本文提出的一个可扩展的自动化数据生成系统,专为自动驾驶仿真设计,能够自动挖掘罕见物体图像、生成高保真3D资产并合成多样化的驾驶场景数据。
- 真实-仿真-真实 (Real2Sim2Real): 一种数据生成范式,指从真实世界数据 (Real) 出发(如网络图片),通过仿真 (Sim) 技术创建数字资产和场景,最终生成接近真实世界 (Real) 的合成数据,形成一个闭环流程。
- 混合式3D资产生成管线 (Hybrid 3D asset generation pipeline): 本文提出的一种从单张图片生成高保真3D模型的核心技术。它结合了基于大型重建模型 (Large Reconstruction Model, LRM) 的粗糙模型初始化、基于法线监督的迭代式网格优化,以及一种增强的纹理融合算法,以实现高精度的几何和纹理。
相关工作
当前自动驾驶的传感器仿真数据生成方法主要有两类。第一类是基于计算机图形学 (Computer Graphics, CG) 的平台,如CARLA。这类方法依赖于手动制作的3D资产,虽然能够构建仿真场景,但资产的真实感和多样性不足,难以扩展以覆盖海量的罕见案例,缺乏可扩展性。
 图1:不同自动驾驶仿真方法的比较。左:CARLA[1],一个基于CG的平台,使用手工制作的资产,缺乏真实感和可扩展性。中:NeuSim[2],一种仅限于车辆的资产重建方法,需要复杂的多模态图像和LiDAR数据。右:本文方法,一个能够生成多样化通用资产的全自动数据合成框架。图中展示了自动构建的资产库,包括交通元素、车辆和道路基础设施。
图1:不同自动驾驶仿真方法的比较。左:CARLA[1],一个基于CG的平台,使用手工制作的资产,缺乏真实感和可扩展性。中:NeuSim[2],一种仅限于车辆的资产重建方法,需要复杂的多模态图像和LiDAR数据。右:本文方法,一个能够生成多样化通用资产的全自动数据合成框架。图中展示了自动构建的资产库,包括交通元素、车辆和道路基础设施。
另一类是基于学习的3D重建方法,如NeuSim。这类方法能够从真实数据中重建出更逼真的资产,但通常仅限于特定类别(如车辆),且需要复杂的多传感器输入(如多视角图像和激光雷达数据),这限制了它们在通用物体上的应用灵活性和可扩展性。此外,近期的单视图3D生成方法虽然提升了效率,但生成的几何和纹理质量对于高要求的仿真应用来说仍然不足。
本文旨在解决上述问题,提出一个成本低、可扩展性强、能从单张图片生成任意类别高保真3D资产的自动化数据合成管线,以满足自动驾驶系统对多样化、高质量罕见场景数据的迫切需求。
本文方法
本文提出了SynthDrive,一个自动化的“真实-仿真-真实”数据生成框架,包含资产挖掘、3D资产生成和场景合成三大核心模块。
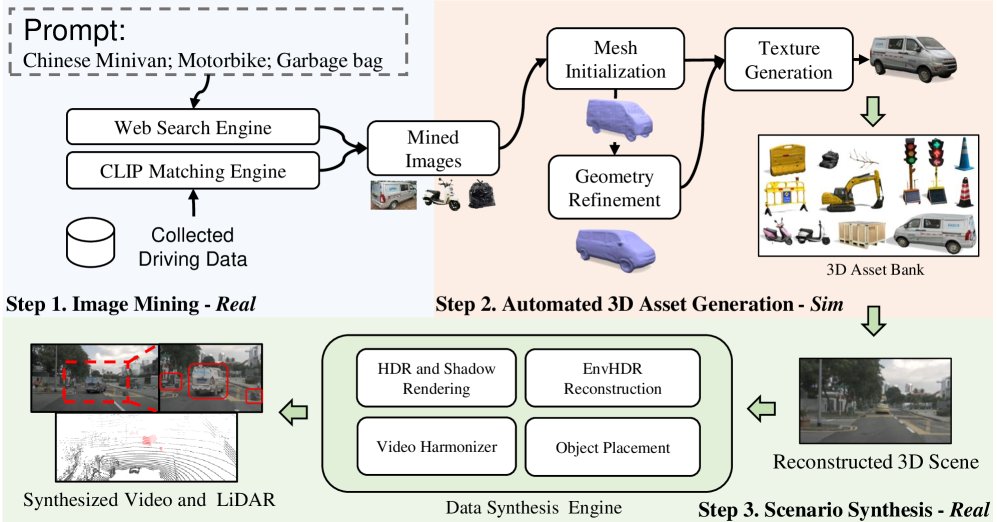 图2:SynthDrive框架。1) 给定文本提示,系统通过CLIP[21]从现有驾驶数据或网络搜索引擎中自动挖掘资产图像。2) 使用提出的混合多阶段图像到3D算法从这些图像中重建高质量3D资产,生成一个全面的3D资产库。3) 最终通过将从资产库中查询到的3D资产与真实图像(或重建的3D场景[24, 25, 26])大规模、可扩展地融合来渲染合成数据。
图2:SynthDrive框架。1) 给定文本提示,系统通过CLIP[21]从现有驾驶数据或网络搜索引擎中自动挖掘资产图像。2) 使用提出的混合多阶段图像到3D算法从这些图像中重建高质量3D资产,生成一个全面的3D资产库。3) 最终通过将从资产库中查询到的3D资产与真实图像(或重建的3D场景[24, 25, 26])大规模、可扩展地融合来渲染合成数据。
## 整体流程
-
图像挖掘 (Image Mining): 管线始于图像挖掘。系统接收一个描述罕见物体的文本提示(如“便携式交通灯”),然后使用CLIP模型在现有驾驶数据库和互联网上进行检索,自动收集多样的目标图像,无需手动采集。
-
自动化3D资产生成 (Automatic 3D Asset Generation): 这是本文的核心技术贡献。该模块接收单张挖掘到的图像,通过一个混合式的多阶段流程生成高保真、带纹理的3D网格模型。
-
场景合成 (Scenario Synthesis): 生成的3D资产被无缝集成到真实的驾驶视频或重建的3D环境中。通过环境光照估计、阴影渲染和色彩协调等技术,确保合成的场景具有高度的真实感。
## 核心创新:高保真3D资产生成
本文提出的3D资产生成管线旨在从单张图片中恢复出具有精细几何和高清纹理的3D模型,其流程如下图所示,主要包含三个关键步骤:
 图3:提出的3D资产生成管线示意图。给定一张输入图像,使用多视图扩散模型[16]和法线估计模型[22]生成多视图图像和法线图。从LRM重建的粗糙网格开始,通过迭代的法线感知网格优化来细化几何。最终纹理通过改进的纹理融合策略得到增强,以保留高分辨率细节。
图3:提出的3D资产生成管线示意图。给定一张输入图像,使用多视图扩散模型[16]和法线估计模型[22]生成多视图图像和法线图。从LRM重建的粗糙网格开始,通过迭代的法线感知网格优化来细化几何。最终纹理通过改进的纹理融合策略得到增强,以保留高分辨率细节。
### 网格初始化
首先,使用多视图扩散模型 (Zero123++) 从输入单图生成一组视角一致的多视图图像。然后,将这些图像输入一个大型重建模型 (Large Reconstruction Model, LRM),如InstantMesh,快速生成一个拓扑结构良好的粗糙3D网格。同时,利用法线估计模型 (StableNormal) 从多视图图像中预测出对应的法线图,作为后续几何优化的监督信号。
### 迭代式网格优化
为了解决初始网格几何细节不足的问题,本文设计了一个迭代优化过程。该过程使用可微分渲染器,从当前网格渲染出多视角的法线图和轮廓图。通过一个损失函数来比较渲染结果与先前生成的“伪真值”(法线图和轮廓),并反向传播梯度以更新网格的顶点位置。损失函数定义为:
\[\mathcal{L} = L_{n} + \lambda_{mask}L_{mask} + \lambda_{lap}L_{lap},\]其中,$L_n$是渲染法线与预测法线之间的L2损失,$L_{mask}$是渲染轮廓与真值轮廓的损失,$L_{lap}$是拉普拉斯平滑项,用于保证网格表面的平滑性。在每次迭代中,网格会进行细分、优化和平滑处理,从而逐步增加几何细节并避免陷入局部最优。
### 纹理生成
为确保资产的真实感,本文提出了一种增强的纹理生成策略。首先,使用一个基于扩散的超分辨率模型将多视图图像的分辨率提升两倍,以恢复更多纹理细节。接着,通过一种显式的纹理融合算法,而非直接使用LRM的颜色输出,来生成最终纹理。具体来说,对于网格上的每个顶点,算法会找到其法线方向与相机视角最接近的视图,并从该视图的高分辨率图像中采样颜色。对于视图接缝处的顶点,使用拉普拉斯平滑进行颜色过渡。最后,通过颜色传播填充不可见区域,最终生成一个完整、细节丰富的高清纹理贴图。
## 场景合成
生成的3D资产会被整合到驾驶场景中。首先,通过激光雷达或多视图立体视觉重建路面几何,并利用目标跟踪器确定无碰撞的放置区域。然后,估计场景的HDR环境光照,以确保插入资产的阴影和光照效果的真实性。最后,将渲染后的资产与背景图像进行融合,并通过视频协调器调整色彩、对比度等,使合成效果更加逼真。
实验结论
## 3D资产生成评估
定性结果:如下图所示,与InstantMesh、CRM等基线方法相比,本文方法生成的3D模型在几何和纹理质量上均表现出显著优势。无论是时钟的数字、汽车的后视镜等精细结构,还是复杂的纹理细节,本文方法都能高质量地重建。即使是来自互联网、光照和几何复杂的图像,该方法也表现出良好的泛化能力。
| Ours | CRM | InsMesh | Wonder3D | Ours | CRM | InsMesh | Wonder3D | | :—: | :—: | :—: | :—: | :—: | :—: | :—: | :—: |
 图4:不同方法的定性比较。(a)-(f)为输入。本文的网格显示出更优的几何和纹理质量。
图4:不同方法的定性比较。(a)-(f)为输入。本文的网格显示出更优的几何和纹理质量。
定量结果:在GSO和3DRealCar数据集上的评估表明,本文方法在各项几何和视觉质量指标上均超越了所有基线方法。 在GSO数据集上,与表现次优的方法相比,本文方法在倒角距离 (Chamfer Distance, CD) 上降低了14.1%,在体积交并比 (Volume IoU) 上提升了7.1%,在PSNR上提升了13.1%(见表I)。 在3DRealCar数据集上,即使是对于困难视角,本文方法的性能下降幅度也最小,证明了其强大的360度视角泛化能力(见表II)。
TABLE I: GSO数据集上的结果。CD:倒角距离。
| 方法 | CD$\downarrow$ | 体积 IoU$\uparrow$ | PSNR$\uparrow$ | SSIM$\uparrow$ | LPIPS$\downarrow$ |
|---|---|---|---|---|---|
| Magic123 | 0.0516 | 0.4528 | 12.69 | 0.7984 | 0.2442 |
| SyncDreamer | 0.0261 | 0.5421 | 14.00 | 0.8165 | 0.2591 |
| Wonder3D | 0.0199 | 0.6244 | 13.31 | 0.8121 | 0.2554 |
| CRM | 0.0173 | 0.6286 | 16.22 | 0.8381 | 0.2143 |
| InsMesh | 0.0191 | 0.5810 | 16.84 | 0.8408 | 0.1749 |
| Ours | 0.0164 | 0.6731 | 19.05 | 0.8724 | 0.1255 |
TABLE II: 在RealCar360正常/困难评估集上不同方法的结果。CD:倒角距离。
| 方法 | CD$\downarrow$ | 体积 IoU$\uparrow$ | PSNR$\uparrow$ | SSIM$\uparrow$ | LPIPS$\downarrow$ |
|---|---|---|---|---|---|
| Wonder3D | 0.0283/0.0322 | 0.48/0.40 | 14.50/13.90 | 0.768/0.793 | 0.204/0.263 |
| CRM | 0.0240/0.0330 | 0.54/0.43 | 15.29/14.42 | 0.808/0.775 | 0.167/0.180 |
| InsMesh | 0.0190/0.0256 | 0.69/0.56 | 16.53/14.76 | 0.845/0.794 | 0.157/0.177 |
| Ours | 0.0170/0.0184 | 0.76/0.70 | 16.98/16.51 | 0.857/0.851 | 0.128/0.133 |
## 下游任务评估
将SynthDrive生成的合成数据加入到2D和3D目标检测任务的训练中,可以显著提升模型在罕见物体类别上的性能。
- 2D检测:在自采数据集上,加入合成数据后,“A字架”和“警告三角牌”这两个罕见类别的平均精度(AP)和平均召回率(AR)分别提升了3-4%(见表III)。
- 3D检测:在NuScenes数据集上,加入20%的合成数据后,整体mAP提升了2.1%,NDS提升了1.7%。其中,样本稀少的“摩托车”类别的AP提升了4.0%(见表IV)。
这些结果验证了本文方法生成的高保真合成数据能有效弥补真实数据的不足,提升下游感知模型的鲁棒性。
TABLE III: 在自采数据集上的2D检测结果对比。
| 训练数据 | A字架 | 警告三角牌 | ||
|---|---|---|---|---|
| AP$\uparrow$(%) | AR$\uparrow$ (%) | AP$\uparrow$ (%) | AR$\uparrow$ (%) | |
| 真实数据 | 24.3 | 39.2 | 72.4 | 73.3 |
| 真实+合成数据 | 27.4(+3.1) | 43.1(+3.9) | 76.5(+4.1) | 77.1(+3.8) |
TABLE IV: 在NuScenes数据集上的3D检测结果对比。
| 3D 检测 | 各类别 AP↑ | ||||
|---|---|---|---|---|---|
| 训练数据 | NDS↑ | mAP↑ | 摩托车 | 交通锥 | 工程车辆 |
| 真实数据 | 40.7 | 33.5 | 36.1 | 54.1 | 10.5 |
| 真实+20%合成数据 | 42.4 (+1.7) | 35.6 (+2.1) | 40.1 (+4.0) | 54.2 (+0.1) | 12.7 (+2.2) |
| 真实+50%合成数据 | 41.6 (+0.9) | 35.2 (+1.7) | 40.5 (+4.4) | 54.7 (+0.6) | 10.4 (-0.1) |
 图5:带有相机和LiDAR仿真的合成示例。高质量的挖掘3D资产使得罕见驾驶场景的直接合成成为可能。
图5:带有相机和LiDAR仿真的合成示例。高质量的挖掘3D资产使得罕见驾驶场景的直接合成成为可能。
## 消融研究
消融实验证明了本文方法设计的有效性:
- 网格优化迭代:实验表明,迭代20步左右,几何精度指标(如F-score和CD)趋于收敛,在精度和效率之间取得了良好平衡。
- 纹理融合:对比实验显示,本文提出的纹理融合策略能显著提升纹理的清晰度和锐度,而没有该策略的纹理则显得模糊。
## 总结
本文提出的SynthDrive框架通过一个全自动的资产挖掘、生成和合成流程,有效地解决了自动驾驶仿真中罕见场景数据获取难、成本高的问题。其核心的混合式3D资产生成方法在几何精度和纹理真实感上均达到了业界领先水平。实验证明,利用该框架生成的合成数据能够显著提高下游2D和3D感知任务的性能,展现了其在推动自动驾驶系统向更安全、更鲁棒方向发展方面的巨大潜力。