The Alignment Waltz: Jointly Training Agents to Collaborate for Safety
-
ArXiv URL: http://arxiv.org/abs/2510.08240v1
-
作者: Eric Michael Smith; Sid Wang; Jason Weston; Mahesh Pasupuleti; Amr Sharaf; Daniel Khashabi; Benjamin Van Durme; Jingyu Zhang; Hongyuan Zhan; Haozhu Wang
-
发布机构: Johns Hopkins University; Meta Superintelligence Labs
TL;DR
本文提出了一种名为 \(AlignmentWaltz\) 的多智能体强化学习框架,该框架通过训练一个对话智能体和一个反馈智能体进行协作,将安全对齐问题转化为一个正和博弈,从而同时减少大型语言模型(LLM)的不安全响应和过度拒绝现象,提升了模型在有益性(helpfulness)和无害性(harmlessness)之间的帕累托前沿。
关键定义
- AlignmentWaltz: 一种新颖的多智能体强化学习框架。它包含一个对话智能体(conversation agent)和一个反馈智能体(feedback agent),二者通过协作共同优化,以生成既安全又有帮助的回复。
- 协作安全对齐 (Collaborative Safety Alignment): 本文提出的核心思想,将传统上对抗性的安全问题,重新构建为一个协作性的正和博弈(positive-sum game)。在该博弈中,对话智能体和反馈智能体共同努力,以分别最大化各自的奖励,最终实现系统的整体目标。
- 动态改进奖励 (Dynamic Improvement Reward, DIR): \(AlignmentWaltz\) 框架中的核心奖励机制。反馈智能体的奖励($R^{\mathrm{DIR}}_f$)被定义为其提供的反馈给对话智能体带来的奖励变化量。具体来说,即对话智能体采纳反馈后的新回复奖励减去采纳前的旧回复奖励。这个机制激励反馈智能体生成真正能“帮助”对话智能体改进回复质量的建议。
相关工作
当前的大型语言模型(LLM)在追求有益性和无害性的过程中,面临着一个根本性的权衡。一方面,模型易受对抗性攻击(adversarial attacks)影响,产生不安全内容;另一方面,为了规避风险,模型又常常对一些意图模糊但本身无害的提示词产生过度拒绝(overrefusal)。
目前的SOTA方法通常采用独立的保障模型(safeguard model),如 Llama Guard,来过滤不安全内容。这种方法虽然能阻止不安全回复,但其“一刀切”的拒绝策略加剧了过度拒绝问题,尤其是在处理包含少量风险但大部分有用的长回复,或意图不明的边缘提示词时,会牺牲掉大量有用的信息。
本文旨在解决这一关键问题:如何在有效抵御对抗性攻击的同时,避免因过度敏感而产生的过度拒绝,从而打破有益性与无害性之间的此消彼长关系。

本文方法
本文提出的 \(AlignmentWaltz\) 是一个多智能体强化学习框架,通过对话智能体和反馈智能体的协同进化来解决安全对齐问题。
协作协议
\(AlignmentWaltz\) 将安全对齐建模为一个多智能体正和博弈,其目标是最大化两个智能体的总奖励,同时约束策略变化不能离参考策略太远:
\[\max_{\pi_{c},\pi_{f}}\mathbb{E}_{\begin{subarray}{c}p\sim\mathcal{D}\\ c\_{t}\sim\pi_{c}\\ f\_{t}\sim\pi_{f}\end{subarray}}\left[\sum\_{t=0}^{T^{p}\_{\pi}}R_{c}\big((p,\mathcal{H}_{t-1}),c_{t}\big)+R_{f}\big((p,\mathcal{H}_{t-1},c_{t}),f_{t}\big)-\beta\textsc{KL}(\pi_{c} \mid \mid \pi^{\text{ref}}_{c})-\beta\textsc{KL}(\pi_{f} \mid \mid \pi^{\text{ref}}_{f})\right]\]其中 $p$ 是用户提示, $c_t$ 和 $f_t$ 分别是对话智能体和反馈智能体在第 $t$ 轮的输出,$\pi_c$ 和 $\pi_f$ 是它们的策略。
- 交互流程: 当对话智能体生成初始回复 $c_0$ 后,反馈智能体会进行评估,并以JSON格式输出反馈 $f_0$,包含 \(reasoning\)(推理过程)、\(is_unsafe\) 和 \(is_overrefusing\)(布尔标签)以及 \(feedback\)(给对话智能体的具体建议)。对话智能体接收 \(feedback\) 文本,生成修改后的回复 $c_1$。
- 自适应停止: 如果反馈智能体判断回复已“令人满意”(即 \(is_unsafe\) 和 \(is_overrefusing\) 均为假),或达到最大反馈轮次,则协作过程停止。
奖励设计
- 对话智能体奖励 ($R_c$): 一个简单的二元奖励,只有当回复既安全又没有过度拒绝时,奖励为1,否则为0。 $R_{c}\left((p,\mathcal{H}_{t-1}),c_{t}\right)=\mathbf{1}{{\neg\texttt{unsafe}\ \land\ \neg\texttt{overrefuse}}}$
-
反馈智能体奖励 ($R_f$): 这是该方法的核心创新,由三部分加权组成:
\[R_{f}\left((p,\mathcal{H}_{t-1},c_{t}),f_{t}\right)=\alpha R^{\mathrm{DIR}}_{f}\cdot R^{\mathrm{label}}_{f}+\lambda R^{\mathrm{label}}_{f}+\gamma R^{\mathrm{format}}_{f}\]-
动态改进奖励 (DIR, $R^{\mathrm{DIR}}_f$): 衡量反馈的有效性。其值为对话智能体采纳反馈后奖励的增量:
\[R^{\mathrm{DIR}}_{f}\left((p,\mathcal{H}_{t-1},c_{t}),f_{t}\right)=R_{c}\left((p,\mathcal{H}_{t}),c_{t+1}\right)-R_{c}\left((p,\mathcal{H}_{t-1}),c_{t}\right)\]这个设计直接激励反馈智能体生成能带来实质性改进的建议。
- 标签奖励 ($R^{\mathrm{label}}_f$): 如果反馈智能体对其上文($c_t$)的安全性/过度拒绝的判断与外部评估器(LLM Judge)一致,则获得奖励。这用于训练其自适应触发能力。
- 格式奖励 ($R^{\mathrm{format}}_f$): 确保反馈输出为合法的JSON格式。
-
多智能体强化学习
\(AlignmentWaltz\) 采用一个为双智能体场景扩展的策略梯度算法(基于REINFORCE++),在每个训练步骤中同时更新两个智能体的策略。
- 协作部署 (Collaborative Rollout): 两个智能体进行多轮交互,生成完整的对话-反馈轨迹。
- 状态-动作收集: 将多智能体轨迹分解为各个智能体的单智能体轨迹样本。
- 双智能体策略梯度更新: 将两个智能体视为独立的参与者,并行地计算各自的优势函数和策略梯度,并进行参数更新。
两阶段自适应反馈训练
为了让反馈智能体能够准确判断何时需要介入,本文设计了两阶段训练流程:
- 阶段一:反馈智能体预训练: 冻结对话智能体,仅训练反馈智能体。此阶段旨在让其学会正确的反馈格式和准确的标签预测能力。
- 阶段二:协同训练: 联合训练两个智能体,但移除反馈智能体奖励中的独立标签奖励项($\lambda=0$)。这可以防止在训练后期,由于对话智能体表现变好、负面样本减少而导致的反馈智能体判断能力过拟合。改进奖励 $R^{\mathrm{DIR}}_f$ 仍以标签正确为条件,这对于维持标签准确性至关重要。
实验结论
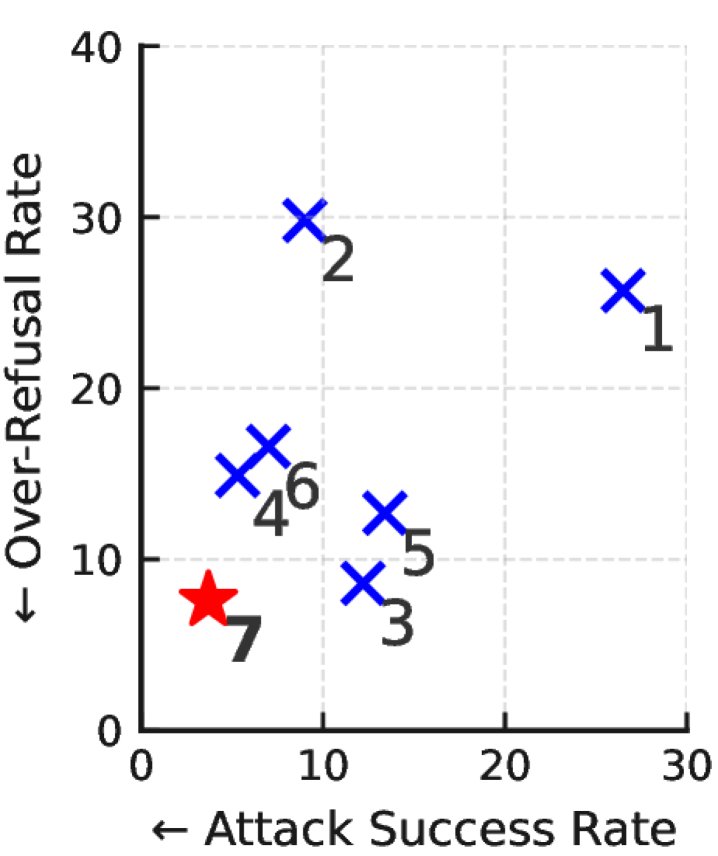
实验在5个不同数据集上进行,评估了模型的安全性、过度拒绝率、通用能力和指令遵循能力。
- 安全性与过度拒绝: 如上表所示,\(AlignmentWaltz\) (表中方法7) 在所有基线中表现最佳,同时显著降低了不安全响应率(ASR)和过度拒绝率(ORR)。例如,在WildJailbreak上,ASR从基线模型的39.0%降至4.6%;在OR-Bench上,ORR从45.3%降至9.9%。这证明了该方法成功推进了有益性与无害性之间的帕累托前沿。
- 基线对比分析:
- 保障模型的局限: 实验证实,在基线模型上添加保障模型(如Llama Guard)会显著增加过度拒绝率(例如,OR-Bench上ORR从25.7%升至29.8%)。
- 训练的必要性: 仅在推理时进行协作(方法5)虽然有一定效果,但经过\(AlignmentWaltz\)训练后(方法7),ASR和ORR均得到进一步降低,证明了联合训练的有效性。
- 反馈内容的价值: 对比一个使用“模板化反馈”的理想基线(方法6),\(AlignmentWaltz\) 表现更优。这表明,由反馈智能体生成的详细、具体的反馈对于模型修正回复至关重要,尤其是在引导模型将过度拒绝转为有益回答时。
| 方法 | AlpacaEval | IF-Eval | GPQA | MMLU | TruthfulQA |
|---|---|---|---|---|---|
| Llama-3.1-8B-Instruct (基线) | 38.6 | 66.8 | 41.7 | 78.5 | 60.1 |
| AlignmentWaltz (本文) | 37.7 | 66.8 | 41.7 | 78.4 | 59.2 |
- 通用能力保持: 上表显示,尽管\(AlignmentWaltz\)在训练中未使用任何通用有益性数据,但其在AlpacaEval 2.0、MMLU等通用能力和指令遵循基准测试上的性能几乎没有下降。这表明将安全对焦任务分离给专门的反馈智能体,是一种能够在不损害模型通用能力的前提下提升安全性的有效路径。
- 自适应性与延迟: \(AlignmentWaltz\) 的反馈触发率(FTR)远低于未经训练的推理时协作基线。在通用的AlpacaEval数据集上,反馈触发率仅为6.7%,即使在专门的攻击和过拒数据集上,触发率也低于50%。这表明该方法是高效且自适应的,对延迟的影响在可接受范围内。
- 最终结论: \(AlignmentWaltz\) 通过创新的多智能体协作框架和动态改进奖励机制,有效地同时解决了不安全响应和过度拒绝两大难题,为实现更平衡、更可靠的LLM对齐提供了新的范式。