The Art of Scaling Reinforcement Learning Compute for LLMs
-
ArXiv URL: http://arxiv.org/abs/2510.13786v1
-
作者: David Brandfonbrener; Sai Surya Duvvuri; Lovish Madaan; Rishabh Tiwari; Inderjit S. Dhillon; Devvrit Khatri; Rachit Bansal; Rishabh Agarwal
-
发布机构: Harvard University; Meta; Periodic Labs; UCL; University of California, Berkeley; University of Texas at Austin
TL;DR
本文通过大规模系统性研究,首次为大语言模型(LLMs)的强化学习(RL)训练提出了一个可预测的规模化框架,并基于此提出了一套名为 \(ScaleRL\) 的最佳实践方法,旨在将RL训练的规模化从“艺术”转变为可预测的“科学”。
关键定义
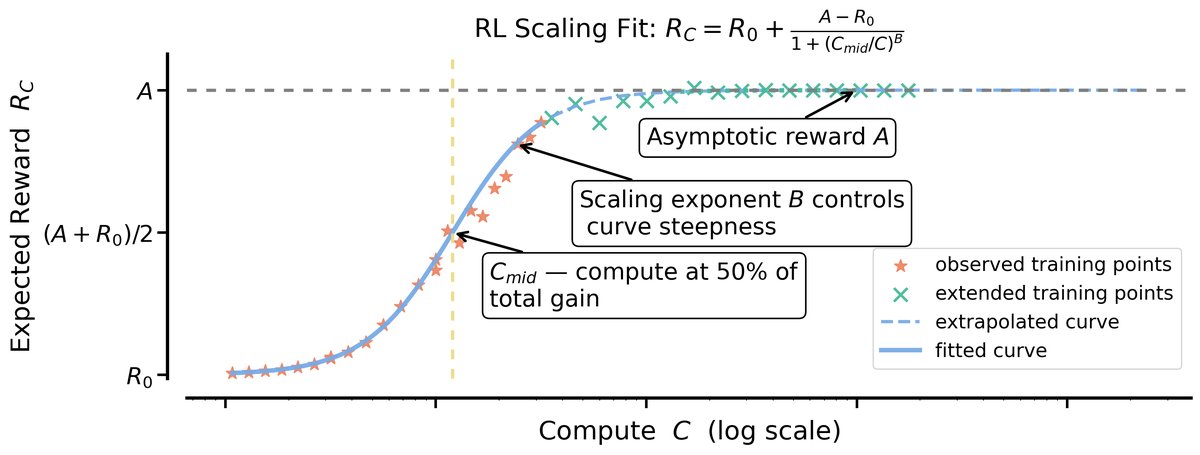
本文的核心是建立一个用于预测RL性能的框架,其关键是使用S型(sigmoidal)函数来拟合计算量与性能之间的关系。
-
计算-性能S型曲线 (Sigmoidal Compute-Performance Curve):本文提出使用以下S型函数来建模在独立同分布(iid)验证集上的预期奖励 $R_C$ 与训练计算量 $C$ 之间的关系:
\[R_{C}-R_{0}=(A-R_{0}) \times \frac{1}{1+(C_{\text{mid}}/C)^{B}}\]其中:
- $A$:渐近性能 (Asymptotic Performance),表示在计算量趋于无穷大时模型可以达到的最高性能(或通过率)上限。
- $B$:缩放指数 (Scaling Exponent),决定了性能曲线的陡峭程度,代表了计算效率。$B$ 值越大,达到性能上限所需计算量越少。
- $C_{\text{mid}}$:计算中点 (Compute Midpoint),代表达到一半渐近奖励增益时所需的计算量,与计算效率 $B$ 共同决定了学习速度。
- $R_0$:初始奖励。
相关工作
-
研究现状: 强化学习(RL)已成为训练前沿大语言模型(LLMs)的核心环节,用于解锁如推理、智能体(Agent)能力等高级功能。随之而来的是,用于RL训练的计算资源预算急剧增加。然而,与已经建立起成熟“规模法则”(scaling laws)的预训练阶段不同,RL领域缺乏一套原则性的方法论来指导如何有效地扩展计算资源。
-
存在问题: 当前RL的规模化更像一门“艺术”而非“科学”。相关研究多为针对特定场景的孤立算法或模型训练报告,提供的解决方案缺乏普适性,无法指导如何开发随计算量可预测扩展的RL方法。这导致研究进展严重依赖昂贵的大规模实验,将大多数研究者排除在外。
-
本文目标: 本文旨在解决RL规模化过程中“如何扩展”和“扩展什么”这两个基本问题。通过建立一个可预测的分析框架,使得研究者能够通过低计算量的早期实验来评估不同RL方法的可扩展性,从而更经济、高效地推进研究。
本文方法
本文的方法论核心分为两部分:首先,通过大规模实证研究,识别出影响RL规模化效率和性能上限的关键设计选择;其次,基于这些发现,整合出一套名为\(ScaleRL\)的最佳实践配方。
大规模实证研究
本文在8B参数规模的模型上进行了超过400,000 GPU小时的实验,系统性地研究了多种设计选择对S型扩展曲线中渐近性能 $A$ 和计算效率 $B$ 的影响。
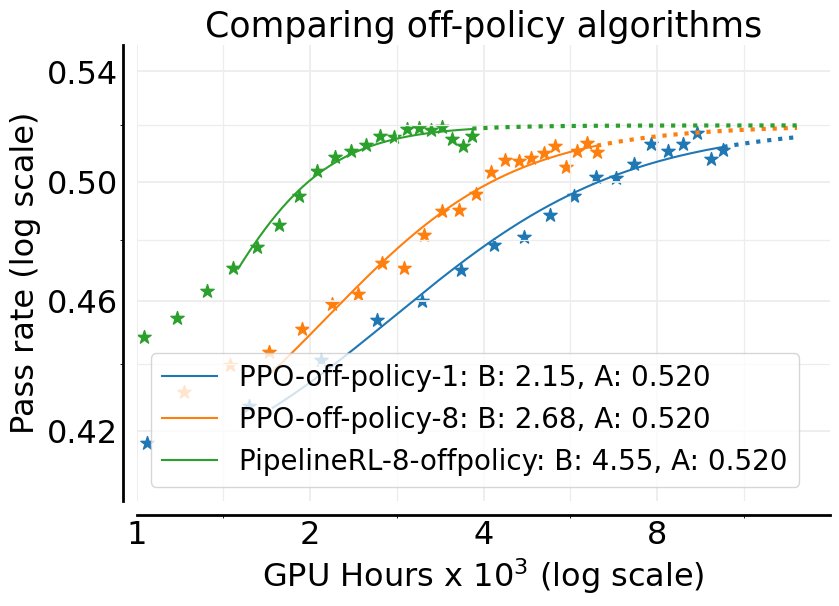
异步RL设置
本文首先对比了两种主流的异步离策略(off-policy)RL设置:
- PPO-off-policy-$k$:生成器(generators)为一批提示生成轨迹,然后训练器(trainers)对这批数据进行 $k$ 次梯度更新。
- PipelineRL-$k$:生成器以流式方式持续生成轨迹,训练器完成一次更新后立即将新参数推送给生成器。这减少了训练过程中的空闲时间。
实验表明,\(PipelineRL\) 在不牺牲渐近性能 $A$ 的前提下,显著提升了计算效率 $B$。
算法选择
在\(PipelineRL-8\)的基础上,本文进一步探索了六个算法设计维度:
- 损失函数类型 (Loss Type):对比了DAPO、GSPO和CISPO。实验发现,CISPO(截断重要性采样的普通策略梯度)和GSPO(序列级重要性采样)显著优于DAPO,能够达到更高的渐近性能 $A$。CISPO在训练后期表现略好。
- LoRA头的FP32精度 (FP32 Precision for LLM logits):由于生成器和训练器使用不同计算核心,会导致数值不匹配,影响重要性采样(IS)比率的计算。在模型的LoRA头使用FP32精度进行计算,可以显著缓解此问题,将渐近性能 $A$ 从0.52提升至0.61。
- 损失聚合 (Loss Aggregation):对比了样本平均、提示平均和Token平均三种方式。发现“提示平均”(每个prompt贡献相同的权重)能达到最高的渐近性能。
- 优势归一化 (Advantage Normalization):对比了提示级、批次级和无归一化三种方式。发现三者性能相似,“批次级归一化”在理论上更稳健且表现略好。
- 零方差过滤 (Zero-Variance Filtering):对于那些所有生成结果奖励都相同的“零方差”提示,它们不产生有效梯度信号。实验证明,在计算损失时过滤掉这些提示,可以提升渐近性能。
- 自适应提示过滤 (Adaptive Prompt Filtering):作为一种数据课程(data curriculum)策略,对于那些通过率已经很高的“简单”提示(例如通过率 > 0.9),将其从后续训练中永久移除。这能更好地利用计算资源,提升扩展性。
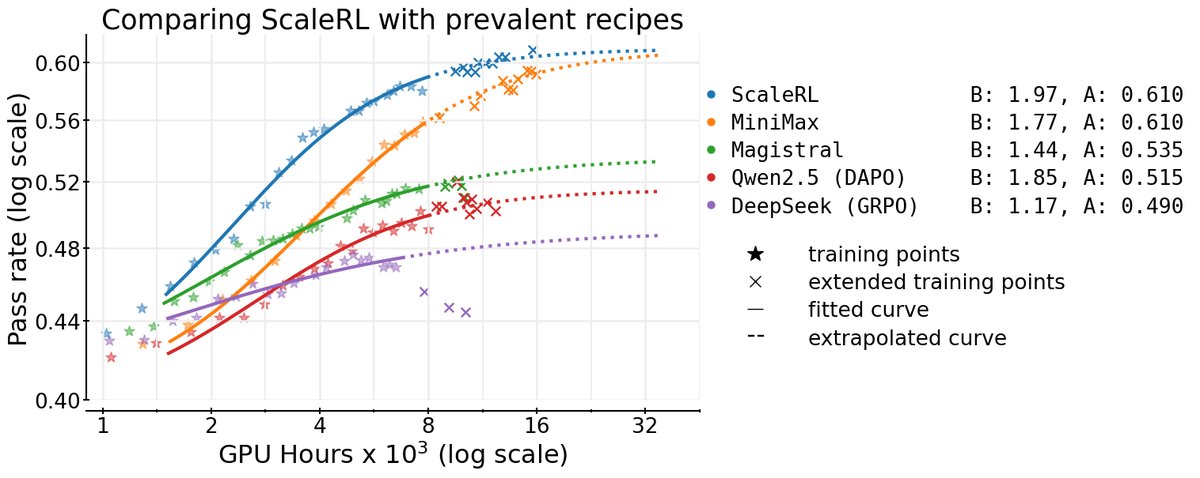
\(ScaleRL\):可预测规模化的RL配方
基于上述实证研究,本文整合出了 \(ScaleRL\) 配方。它并非一个全新的算法,而是现有最佳实践的集合。
\(ScaleRL\) 核心组件
\(ScaleRL\) 是一套异步RL配方,具体包括:
- 异步框架:\(PipelineRL-8\)。
- 长度控制:强制长度中断,通过在超长生成后附加特定短语来终止思考过程。
- 损失函数:CISPO损失,结合了REINFORCE和截断重要性采样。
- 损失聚合与归一化:提示级损失聚合与批次级优势归一化。
- 精度:在LoRA头使用FP32精度。
- 数据策略:零方差过滤和自适应提示过滤(移除通过率>0.9的提示)。
其损失函数 $\mathcal{J}_{\mathrm{\texttt}}(\theta)$ 定义为:
\[\mathcal{J}_{\mathrm{\texttt{{ScaleRL}}}}(\theta)=\hskip-6.99997pt\underset{\begin{subarray}{c}x\sim D,\\ \{y_{i}\}_{i=1}^{G}\sim\pi_{gen}^{\theta_{old}}(\cdot\mid x)\end{subarray}}{\mathbb{E}}\hskip-3.99994pt\left[\frac{1}{\sum_{g=1}^{G} \mid y_{g} \mid }\sum_{i=1}^{G}\sum_{t=1}^{ \mid y_{i} \mid }\texttt{sg}(\mathrm{min}(\rho_{i,t},\epsilon))\hat{A}_{i}^{\text{norm}}\,\log\pi_{train}^{\theta}(y_{i,t})\right],\]其中 \(sg\) 是停止梯度函数,$\rho_{i,t}$ 是Token级重要性采样比率,$\hat{A}^{\mathrm{norm}}_{i}$ 是批次归一化后的优势。
实验结论
本文通过一系列精心设计的实验,验证了其提出的规模化框架和 \(ScaleRL\) 配方的有效性。
关键实验发现
- 渐近天花板效应 (Asymptotic Ceilings):不同的RL方法在计算资源无限时,其性能会饱和于不同的上限 $A$。例如,更换损失函数类型(从DAPO到CISPO)能显著提高这个天花板。
- 交叉效应 (Crossover Effects):在低计算量下表现更优的方法,在高计算量下可能表现更差。本文的S型曲线框架能够通过早期训练数据拟合参数,从而预测长期扩展潜力,帮助研究者识别真正可扩展的方法。
- 效率与上限的分离: 许多常见的干预措施,如优势归一化、数据课程等,主要影响的是计算效率 $B$(即达到上限的速度),而对性能上限 $A$ 的影响不大。
\(ScaleRL\)的性能验证
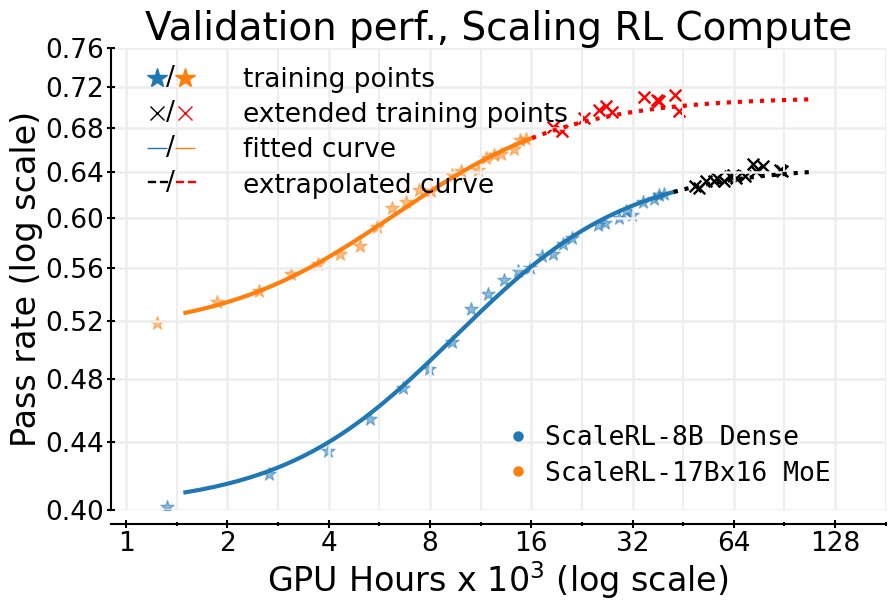
- 可预测性: 在一个高达10万GPU小时的单次RL训练中,\(ScaleRL\) 的实际性能与仅根据早期训练数据(约1.5k GPU小时)外推的S型曲线高度吻合,证明了该框架在极大计算规模下的预测能力。
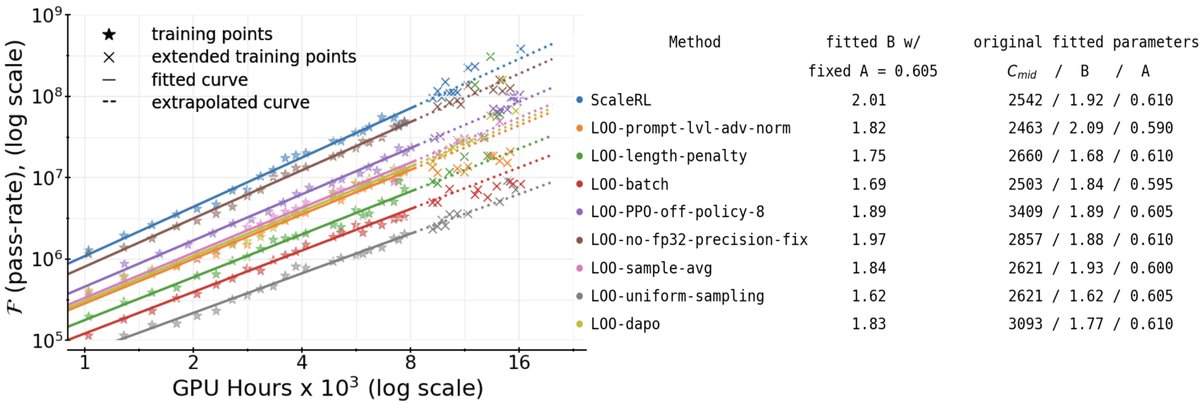
- 有效性: 通过留一法(Leave-One-Out, LOO)消融实验,证实了\(ScaleRL\)中的每一个组件都对整体性能有积极贡献。\(ScaleRL\)始终是所有配置中表现最好的,无论是在渐近性能还是计算效率上都优于或持平于其他变体。
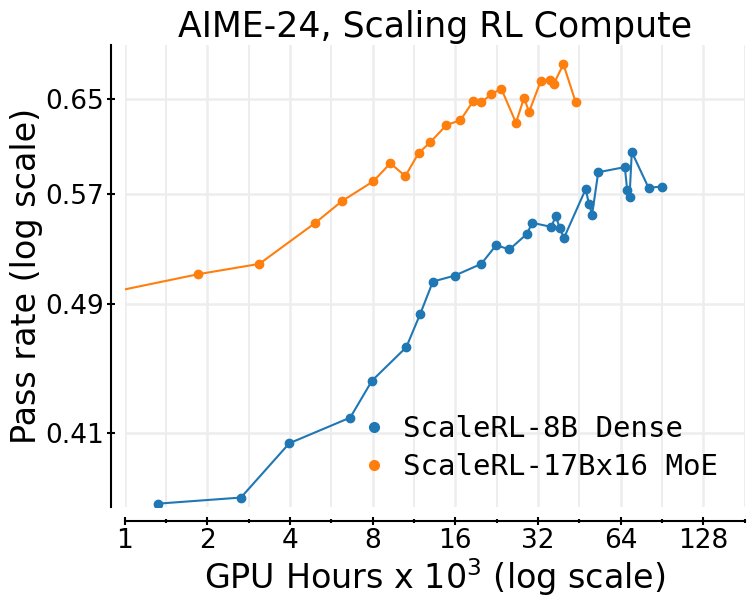
- 泛化性: \(ScaleRL\) 的可预测规模化能力在多个维度上都得到了验证,包括增大批次大小、增加生成长度(最高32,768个Token)、在数学和代码上进行多任务RL训练,以及应用于更大的专家混合(MoE)模型。
最终结论
本文成功地为LLM的RL训练建立了一个严谨的科学框架,并提供了一套名为 \(ScaleRL\) 的实用配方。这项工作将RL训练的规模化从依赖直觉和昂贵试错的“艺术”,推向了类似于预训练阶段的可预测、可度量的“科学”,为未来高效评估和开发新的RL算法铺平了道路。