The Era of Agentic Organization: Learning to Organize with Language Models
-
ArXiv URL: http://arxiv.org/abs/2510.26658v1
-
作者: Qingxiu Dong; Furu Wei; Li Dong; Shaohan Huang; Xun Wu; Zewen Chi
-
发布机构: Microsoft Research
TL;DR
本文提出了一种名为 AsyncThink 的新推理范式,它允许大型语言模型通过一种“组织者-工作者”协议,将复杂的思考过程分解为可并发执行的子任务,并通过强化学习自主学会如何优化这种异步协同结构,从而在降低推理延迟的同时提升了解决问题的准确性。
关键定义
本文提出或沿用了以下对理解其核心思想至关重要的概念:
- 智能体组织 (Agentic Organization):指多个智能体(Agents)组成一个协同系统,通过分工合作来解决超出单个智能体能力的复杂问题。本文的目标是实现这种组织形式。
- AsyncThink:本文提出的核心推理范式,其特点是能将模型的内部思考过程组织成可并发执行的结构。它不是一种固定的流程,而是一种可学习的、动态的组织策略。
- 组织者-工作者协议 (Organizer-Worker Thinking Protocol):实现 AsyncThink 的具体机制。在该协议下,同一个大语言模型扮演两种角色:
- 组织者 (Organizer):负责全局协调,通过特定动作(如 \(<FORK>\) 分配任务,\(<JOIN>\) 合并结果)来动态规划和管理整个思考流程。
- 工作者 (Worker):接收组织者分配的子任务(sub-query),独立执行思考,并返回中间知识或结果。
- 关键路径延迟 (Critical-Path Latency):衡量 AsyncThink 效率的核心指标。它不是简单的所有任务耗时总和,而是考虑了并发执行后,完成整个任务所需的最短时间,即整个思考有向无环图中的最长路径长度。
相关工作
当前,大语言模型作为单个智能体已展现出强大的推理能力,但要实现多个智能体协同解决问题的“智能体组织”愿景,仍存在诸多瓶颈。
主流的并行思考(parallel thinking)方法通常是让多个智能体独立生成完整的思考链,最后再汇总结果。这种方法的局限性在于:
- 延迟瓶颈:总延迟受限于最慢的那个思考链,并且最终的聚合步骤也会引入额外延迟。
- 适应性差:它们依赖于人工设计的、固定的工作流(fixed workflows),无法根据不同问题的特性动态调整策略(例如,何时分治,何时逐步推理)。
- 学习困难:如何为所有可能的问题都设计出最优的思考结构,是一个难以解决的问题。
因此,本文旨在解决的核心问题是:如何让 AI 系统摆脱固定的、手动设计的协作模式,转而自主地学习一种动态、高效的组织策略,以并发的方式协同思考,从而在提升问题解决能力的同时最小化推理延迟。
本文方法
为了实现可学习的智能体组织,本文提出了 AsyncThink 范式,其核心是组织者-工作者协议以及一个两阶段学习流程。
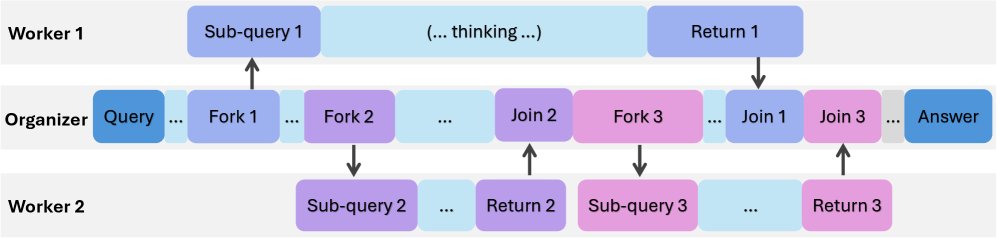
组织者-工作者协议
该协议定义了模型内部的协作方式,同一个 LLM 骨干网络同时扮演组织者和工作者两种角色,通过纯文本的动作标签进行交互。
组织者 (Organizer)
组织者是贯穿整个思考过程的核心,负责全局协调。它通过生成特定的动作标签来控制流程:
- \(<THINK>\): 在自己的解码线程中继续进行思考。
- \(<FORK-i>\): 将一个子查询 $i$ 分配给一个空闲的工作者。格式为 \(<FORK-i>sub-query content</FORK-i>\)。
- \(<JOIN-i>\): 请求获取之前分配的子查询 $i$ 的结果。如果工作者尚未完成,组织者会暂停等待,直到接收到结果。结果会以 \(<RESULT-i>worker's output</RESULT-i>\) 的形式插入到组织者的上下文中。
- \(<FINISH>\): 结束推理过程,并给出最终答案。
工作者 (Worker)
在一个容量为 $c$ 的智能体池中,有 $c-1$ 个工作者。它们接收组织者的指令,独立执行子查询,并将结果返回。组织者在发出 \(<FORK>\) 后可以继续自己的思考,而工作者则并发执行任务,实现了异步性。
这种设计将思考过程的执行结构本身也变成了模型可以生成和优化的对象,从而为动态适应性和学习提供了基础。传统的顺序思考和并行思考都可以视为该协议下的特例。
学习组织能力
本文设计了一个两阶段的训练流程来教会模型如何使用 AsyncThink。
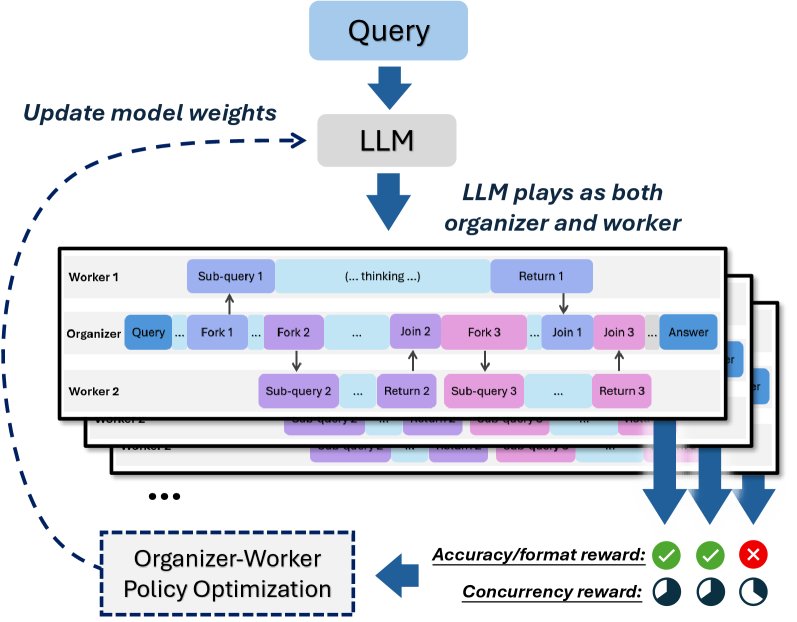
阶段一:冷启动格式微调 (Cold-Start Format Fine-Tuning)
由于缺少现成的异步思考语料,此阶段的目标是让模型先学会协议的语法。
- 数据合成:使用 GPT-4o 分析问题,将其分解为条件独立的思考片段,并生成符合组织者-工作者协议格式的思考轨迹。
- 结构多样化:为避免模型只学会几种固定的思考模式,通过在提示中随机注入不同的动作序列样本,引导模型生成更多样化的思考结构。
- 监督微调:在合成的数据上对模型进行标准的监督微调(SFT),使其能够生成合法的动作标签。此阶段模型只学会了“形似”,还不能有效地利用该结构解决问题。
阶段二:强化学习 (Reinforcement Learning)
此阶段的目标是让模型学会有效地利用异步思考来提升性能,即学会“神似”。
- 奖励模型 (Reward Modeling):设计了一个复合奖励函数来引导模型的学习方向,综合考虑了准确性、格式正确性和并发效率。
- 准确性奖励 ($R_{\text{A}}$):根据最终答案的正确性给予奖励。
- 格式错误惩罚 ($R_{\text{FE}}$):对不合规的动作(如重复分配、超出工作者容量等)进行惩罚。
- 并发效率奖励 ($R_{\eta}$):这是鼓励模型并行思考的关键。它通过计算思考并发率 \(η\) 来给予奖励,\(η\) 定义为在整个推理过程中活跃工作者的平均比例。
其中 $a_t$ 是在时间步 $t$ 的活跃工作者数量,$T$ 是关键路径延迟。总奖励 $R_i$ 的计算方式为:
\[R_{i}=\begin{cases}R_{\text{FE}}&, \text{轨迹 } i \text{ 存在格式错误}\\ R_{\text{A}}+\lambda R_{\eta}&, \text{其他情况}\end{cases}\] - 策略优化:采用扩展的组相对策略优化(GRPO)算法。它将组织者和所有相关工作者的思考轨迹视为一个整体单元来计算奖励和优势函数,从而将奖励信号同时传递给组织者和工作者,协同优化整个思考策略。
实验结论
本文在多解倒计时(Multi-Solution Countdown)、数学推理和数独等任务上对 AsyncThink 进行了评估。
关键实验结果
- 多解倒计时任务:相比顺序思考和并行思考基线,AsyncThink 在准确率上取得了显著优势。例如,在要求找到全部4个解的严格标准下,AsyncThink 达到了 89.0% 的准确率,而基线方法仅为 68.6% 和 70.5%。
- 数学推理任务:在 AIME-24 和 AMC-23 基准上,AsyncThink 同样获得了最佳综合性能,并且其关键路径延迟远低于基线。例如,相比并行思考,AsyncThink 在取得更高准确率的同时,推理延迟降低了 28%。这证明了通过学习来进行任务分解和并发执行的有效性——多个短而精的思考片段组合优于一个冗长的思考链。
| 模型 | AIME-24 准确率 (%) | AMC-23 准确率 (%) | 关键路径延迟 |
|---|---|---|---|
| Qwen3-4B-Base | 4.3 | 12.0 | 798 |
| 顺序思考-L1K | 13.0 | 33.3 | 913 |
| 顺序思考-L2K | 17.4 | 43.3 | 1761 |
| 并行思考-L1K | 17.4 | 40.7 | 935 |
| 并行思考-L2K | 21.7 | 44.0 | 1789 |
| AsyncThink (本文) | 26.1 | 46.7 | 1282 |
- 泛化能力测试:将在倒计时任务上训练的 AsyncThink 模型直接用于解决从未见过的 4x4 数独任务。结果显示,AsyncThink 的性能远超基线,证明了它学习到的是一种通用的组织和协调能力,而不仅仅是针对特定任务的策略。
| 模型 | 4x4 数独准确率 (%) | 关键路径延迟 |
|---|---|---|
| 顺序思考 | 45.3 | 2405.0 |
| 并行思考 | 43.8 | 2445.5 |
| AsyncThink (本文) | 53.5 | 1505.0 |
消融研究与分析
- 学习阶段的必要性:移除格式微调阶段,模型性能大幅下降,表明该阶段为后续的强化学习提供了必要的语法基础。移除并发效率奖励,模型准确率下降且延迟增高,验证了该奖励在引导模型学习并行化方面的重要性。
- 学习动态:在强化学习过程中,模型的准确率和并发率稳步提升,而关键路径延迟则先增后减,最终稳定在较低水平。这表明模型从最初倾向于“多想一会儿”,逐渐学会了如何“聪明地并发想”,从而优化了效率。
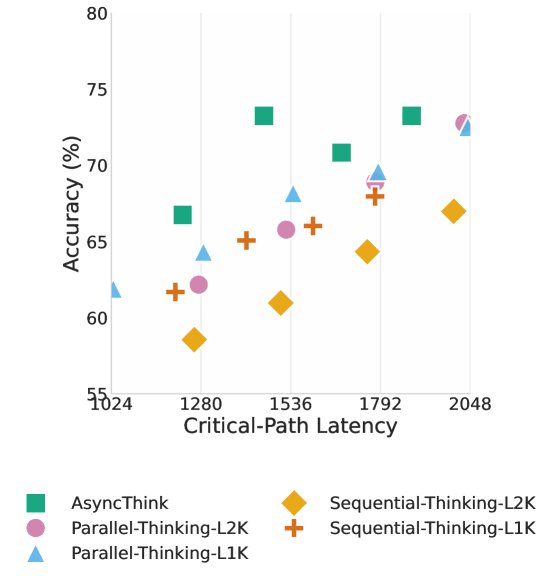
- 准确率-延迟边界:实验结果表明,AsyncThink 在准确率和延迟之间取得了更优的权衡(Pareto-optimal frontier),能够在更低的延迟下达到与基线方法相当甚至更高的准确率。
总结
实验结果有力地证明,AsyncThink 是一种成功的推理范式。通过让模型学习如何动态地组织其内部思考过程,AsyncThink 不仅能有效提升复杂推理任务的准确率,还能显著降低推理延迟,并表现出强大的泛化能力。这为实现更高效、更智能的 AI 协作系统(即“智能体组织”)开辟了新的道路。