The FM Agent
-
ArXiv URL: http://arxiv.org/abs/2510.26144v1
-
作者: Dou Shen; Haobo Zhang; Annan Li; Dawei Yin; Chufan Wu; Jianmin Wu; Quan Sun; Yingying Sun; Rui Yang; Mengmeng Zhang
-
发布机构: Baidu AI Cloud
TL;DR
本文提出一个名为FM Agent的通用多智能体框架,该框架创新性地结合了大型语言模型(LLM)的推理能力和大规模进化搜索,以自动化方式在运筹优化、机器学习、GPU内核优化和数学问题等多个领域解决复杂的现实世界挑战,并取得了最先进(SOTA)的成果。
关键定义
- FM Agent: 一个新颖的、通用的多智能体框架,其核心是将基于LLM的推理与大规模进化搜索相结合,旨在自主解决复杂的科学和工程问题。
- 冷启动阶段 (Cold Start Stage): 框架的初始阶段,通过集成多种生成式智能体和可选的专家指导,快速生成一个多样化且高质量的初始解方案群体,为后续进化奠定基础。
- 进化阶段 (Evolve Stage): 框架的核心优化阶段,采用基于“岛屿”的多样化种群进化策略。在该阶段,通过变异和交叉等操作对解方案进行迭代创新和改进。
- 岛屿模型 (Island Model): 进化阶段采用的一种多群体并行进化策略。将解方案群体分割到多个独立的“岛屿”上并行进化,同时允许岛屿间定期进行个体交换(“思想”交流),以维持种群多样性并避免陷入局部最优。
相关工作
当前,由大型语言模型(LLM)驱动的自主AI研究智能体正迅速发展,其中一个主流方向是利用多个LLM智能体,通过进化或强化学习式的搜索循环来解决复杂的开放式问题。然而,在工业界,如组合优化、机器学习、高性能计算内核调优等高价值领域,寻找高效解方案很大程度上仍依赖于具备深厚领域知识的专家进行手动的、项目制的迭代优化。这一过程不仅成本高昂,而且难以完全自动化。现有的一些自动化方法(如AI编译器)则因为依赖预定义规则而缺乏对新任务的泛化能力。
本文旨在解决的核心问题是:如何构建一个通用的、可扩展的、能够自主解决跨领域复杂问题的AI系统,从而减少对人类专家的依赖,并加速科学发现和工程创新的进程。
本文方法
FM Agent的框架被设计为一个两阶段的自主发现与优化过程,旨在高效地解决复杂问题。它首先通过“冷启动阶段”生成多样化的初始解池,然后进入“进化阶段”进行大规模的迭代寻优。整个框架构建在高性能的分布式基础设施之上,以支持大规模并行计算。
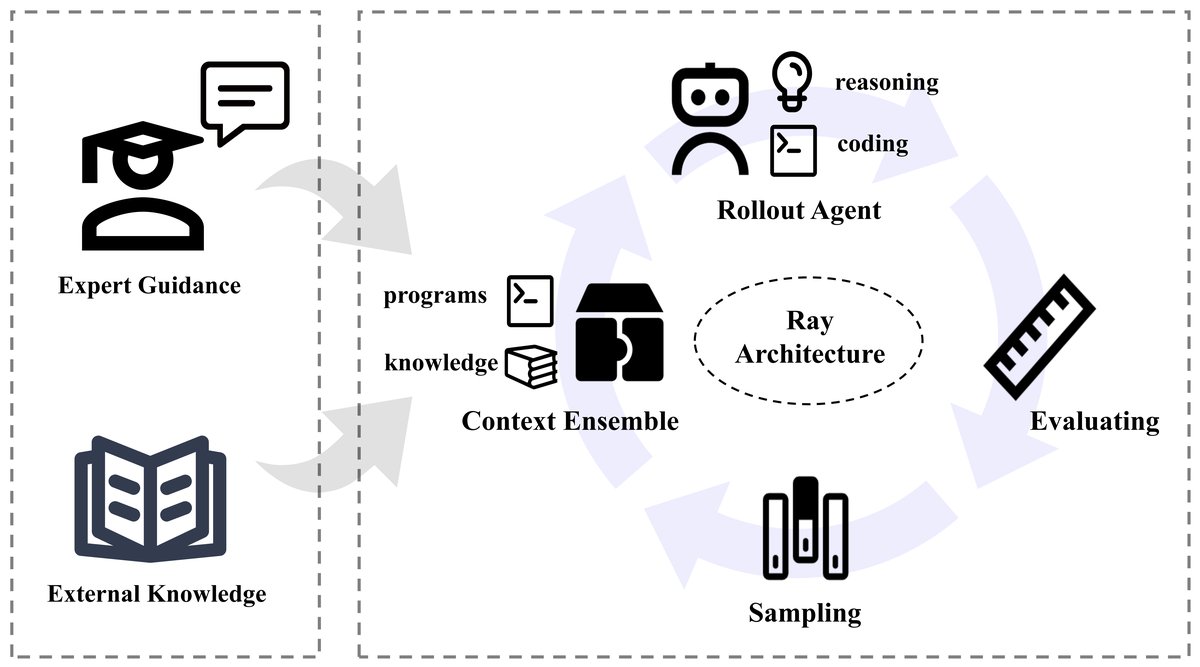
创新点
FM Agent的核心创新体现在其架构设计上,它将LLM的推理能力、进化计算的探索能力与可扩展的分布式系统无缝集成。
冷启动阶段
此阶段的目标是为后续的进化搜索构建一个具有高度多样性的高质量初始解方案种群,从而扩大全局搜索范围,有效防止过早收敛。
- 多样化智能体并行探索: 系统集成了多种类型的生成式智能体,它们可以通过差异化配置并行执行,探索不同的生成策略和优化方向。
- 引导式多样性: 通过引导智能体探索目标空间的不同区域,有意识地拓宽初始解方案的覆盖范围,为后续的深度优化创造条件。
进化阶段
进化模块是FM Agent的核心,它通过大规模、基于种群的搜索来对初始解方案进行创新和改进。其核心是一种高效进化策略。
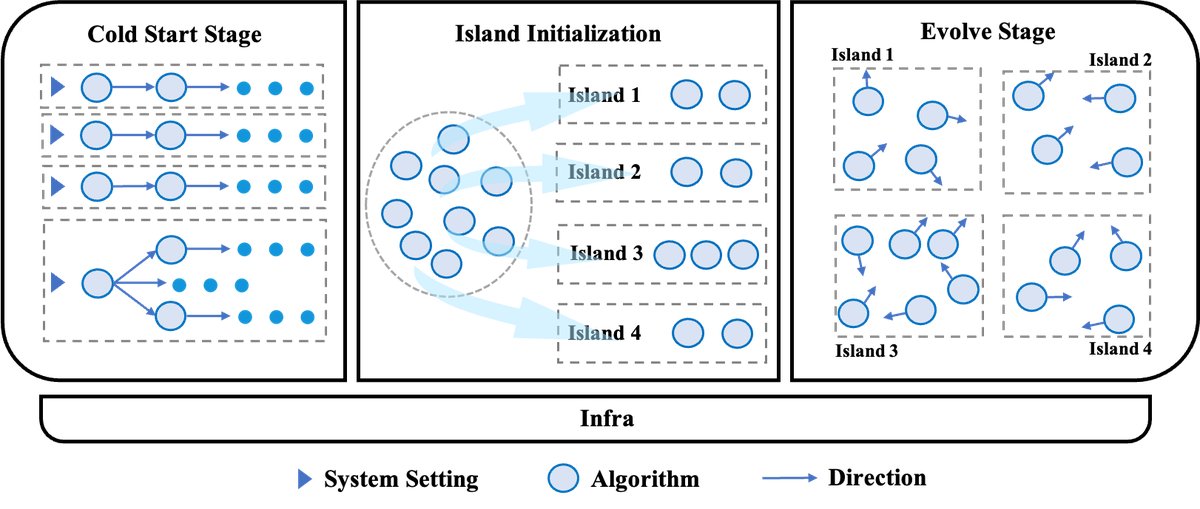
- 多岛屿进化: 框架采用多岛屿模型,将解方案划分到多个并行的“岛屿”中。大部分时间里,每个岛屿独立进化,探索不同的解空间区域;同时,框架促进岛屿间的定期交流,实现“思想”的交叉融合,防止整体搜索陷入局部最优。
- 效率进化策略: 框架采用自适应控制系统来引导每个岛屿内的进化。其关键是一个新颖的基于聚类的采样策略 (cluster-based sampling strategy),该策略通过动态调整选择压力,根据实时的种群多样性在探索(exploration)和利用(exploitation)之间取得平衡。同时,一个精英池会保留表现最佳的解方案以指导后代进化。
- 多维评估: 为了满足不同场景的评估需求,框架采用了灵活的多维评估模块。它不仅提供传统的适应度分数和由LLM进行的定性评估,还为复杂场景(如机器学习、内核生成)提供领域特定的评估策略,如同时考量准确率与延迟、资源利用率等,确保进化过程被全面的领域需求所引导。
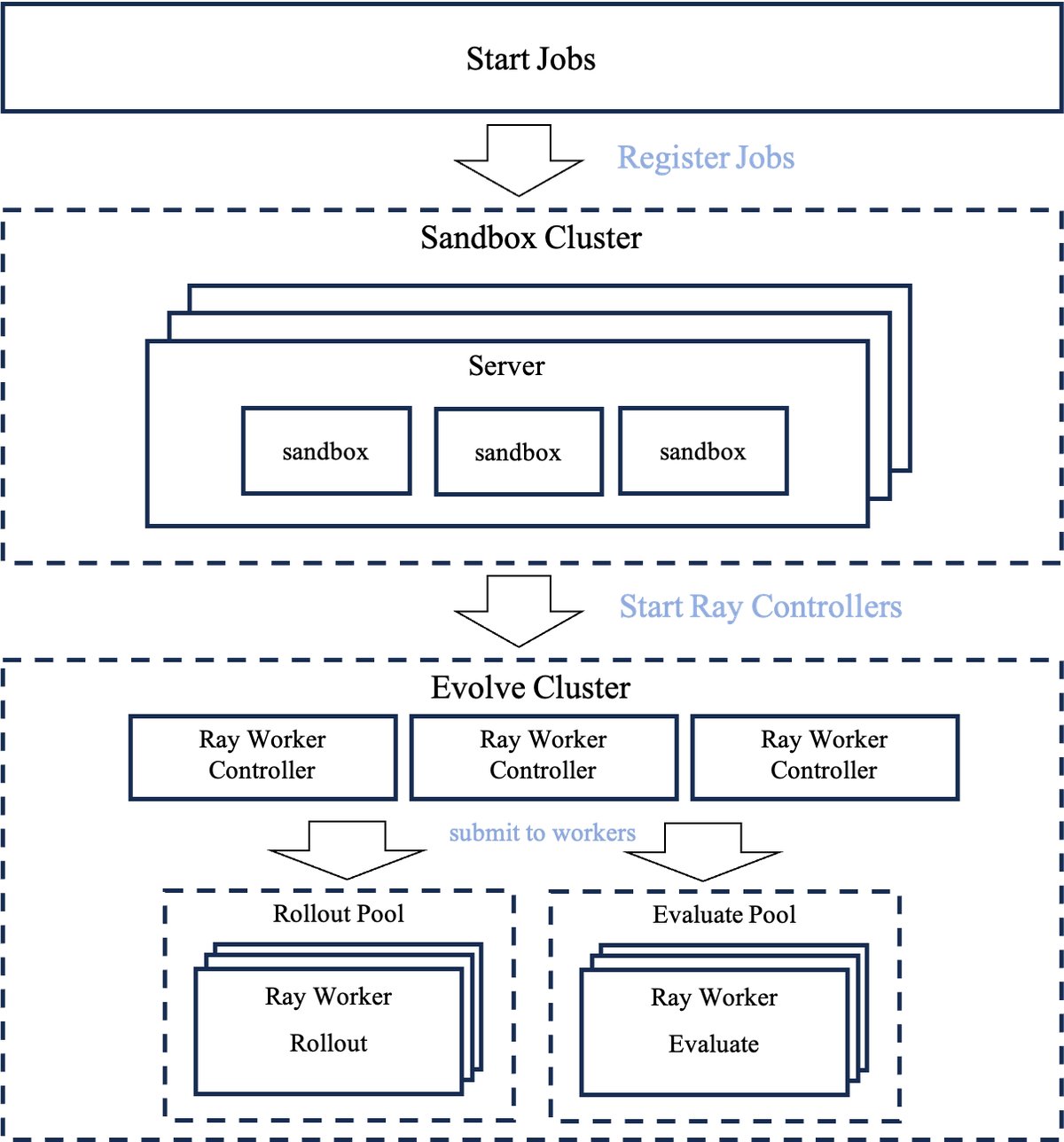
分布式基础设施
FM Agent的底层是一个为高吞吐量进化计算而构建的可扩展分布式基础设施。
- 可扩展性: 基于Ray框架构建,系统可从单节点无缝扩展至大型多节点集群,支持数千个进化过程的并发执行。
- 异步执行: 程序生成和程序评估这两大核心任务在独立的、并行的工作池中异步执行。这种分离设计确保了计算密集的任务不会相互阻塞,显著提高了系统吞吐量和整体进化效率。
人机交互反馈模块
这是一个可选模块,旨在将领域专家的知识灵活地融入自主进化过程中。它提供了一个可视化界面,允许专家实时监控进化指标(如适应度变化、种群多样性),并通过自然语言指令或代码级干预来引导进化方向。此外,该模块还支持构建专家知识库,利用RAG技术在优化遇到瓶颈时自动检索相关知识,为变异和交叉操作提供信息,增强搜索的合理性。
实验结论
本文通过在机器学习、组合优化和GPU内核生成三个不同领域的权威基准测试上进行实验,验证了FM Agent的有效性和泛化能力。所有实验均由LLM自主完成,无人工干预。
机器学习 (MLE-Bench)
MLE-Bench是一个基于Kaggle竞赛的复杂真实世界机器学习任务基准。
| 指标 | InternAgent | Auto-Agent | ML-Master | Human | FM Agent(本文) |
|---|---|---|---|---|---|
| 有效提交率 | 98.67% | 93.33% | 85.33% | - | 98.67% |
| 超过中位数人类 | 48.44% | 40.00% | 44.90% | 50.00% | 65.33% |
| 获得任何奖牌 | 20.31% | 22.86% | 23.44% | 22.00% | 29.33% |
| 获得金牌 | 4.69% | 2.86% | 6.25% | 4.00% | 8.00% |
- 鲁棒性: FM Agent在98.67%的任务中实现了有效提交,展现了极高的可靠性。
- 优越性能: 在65.33%的任务中,其表现超过了一半以上的人类提交者,显著优于其他智能体。
- 顶尖表现: FM Agent获得了最高的奖牌率(29.33%)和金牌率(8.00%),尤其在中等和高复杂度任务上表现突出,表明其在复杂场景中具有超越大多数人类研究员的潜力。
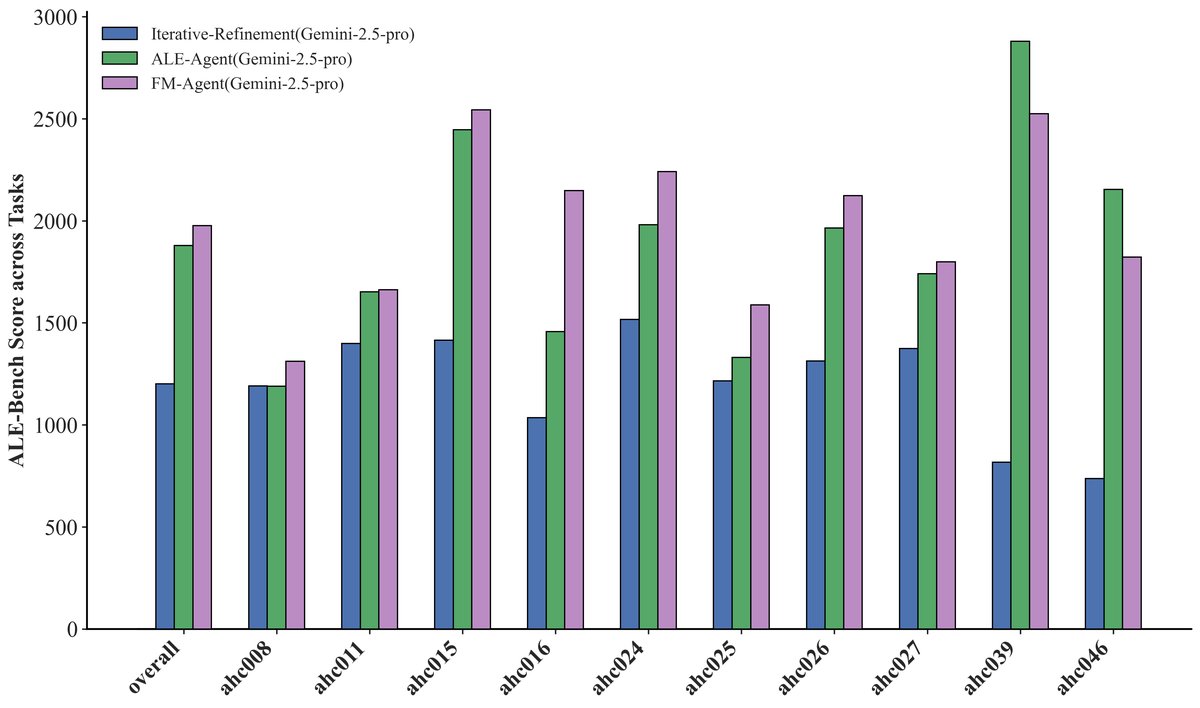
组合优化 (ALE-Bench)
ALE-Bench是一个由计算上难以解决的算法竞赛问题组成的目标驱动算法基准。
| 方法 | 平均分 | ≥400 | ≥1600 | ≥2000 (Yellow) |
|---|---|---|---|---|
| Self-Refine (基线) | 1201.3 | 100.0% | 30.0% | 10.0% |
| ALE-Agent (SOTA) | 1879.3 | 100.0% | 70.0% | 30.0% |
| FM Agent(本文) | 1976.8 | 100.0% | 80.0% | 40.0% |
- 新SOTA: FM Agent取得了1976.8的平均分,创造了新的SOTA记录,比专门设计的ALE-Agent高出5.2%。
- 高水平可靠性: 在高难度阈值(≥2000分,专家“Yellow”级别)上,FM Agent在40%的任务中达标,显著优于ALE-Agent的30%。
- 深度推理能力: 在需要更复杂和创新解决方案的长时程竞赛 (long contests) 中,FM Agent表现尤为出色,表明其进化方法在需要深度推理和优化的复杂问题上特别有效。
GPU内核生成 (KernelBench)
KernelBench旨在评估LLM生成高效GPU内核的能力。实验在最困难的Level 3上进行,并采用了更严格的数值精度要求。
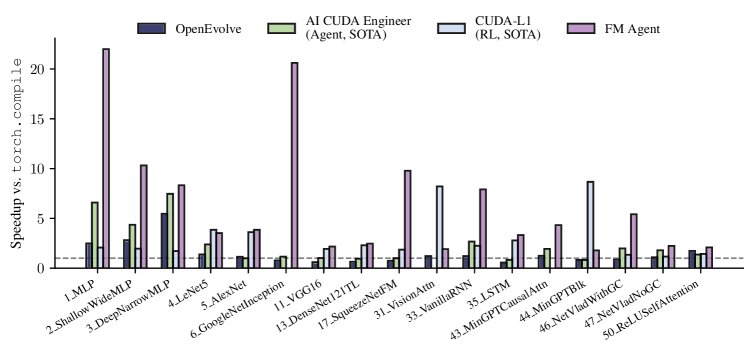
与之前的SOTA方法(如基于智能体的AI CUDA Engineer和基于强化学习的CUDA-L1)相比,FM Agent在保持高数值精度($10^{-5}$)的同时,在多个内核上取得了对cuBLAS基线的2倍到9倍不等的SOTA加速比,始终优于之前的最佳结果。
最终结论:实验结果有力地证明,FM Agent是一个鲁棒且通用的问题解决框架。它能够自主地在机器学习、组合优化和系统优化等多个复杂领域中发现最先进的解决方案,验证了其结合LLM推理和大规模进化搜索的架构设计的优越性。