The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
-
ArXiv URL: http://arxiv.org/abs/2509.02547v1
-
作者: Zaibin Zhang; Zihu Wang; Hongru Wang; Yijiang Li; Hejia Geng; Yang Chen; Heng Zhou; Mengyue Yang; Yifan Zhou; Guibin Zhang; 等23人
-
发布机构: Brown University; Chinese Academy of Sciences; Dalian University of Technology; Fudan University; Imperial College London; National University of Singapore; Shanghai AI Laboratory; The Chinese University of Hong Kong; University College London; University of Bristol; University of California; University of Georgia; University of Illinois Urbana-Champaign; University of Oxford; University of Science and Technology of China
TL;DR
本文提出并形式化了“智能体强化学习(Agentic Reinforcement Learning, Agentic RL)”这一新兴范式,将其定义为将大语言模型(LLM)从被动的序列生成器转变为在复杂动态环境中进行自主决策的智能体,并通过一个围绕智能体核心能力(规划、工具使用、记忆、推理等)的分类体系,系统性地梳理了强化学习在其中发挥的关键作用。
介绍
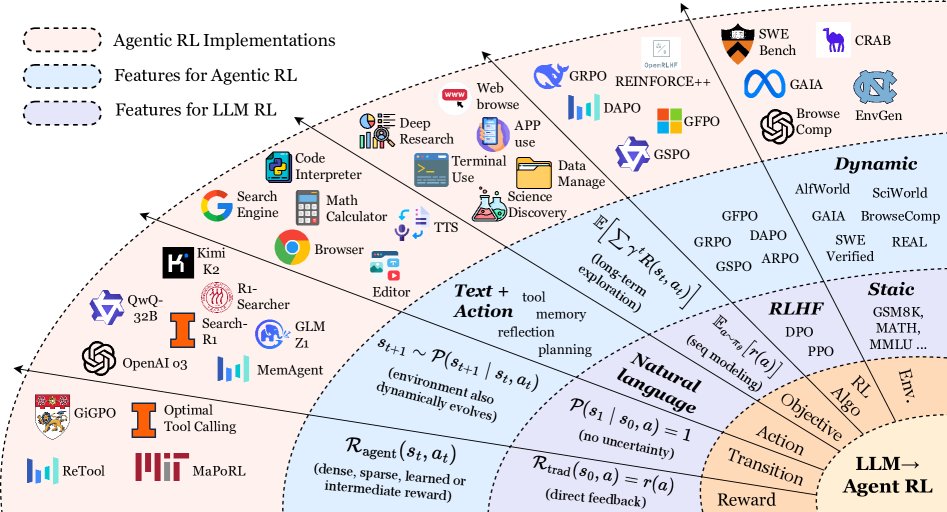
近年来,大语言模型(LLMs)与强化学习(Reinforcement Learning, RL)的融合引发了范式变革。早期方法将LLM视为静态的单轮输出生成器,通过RL进行对齐。然而,这忽略了现实交互中序贯决策的复杂性。新趋势是将LLM看作智能体实体 (agentic entities),即能够在部分可观察的动态环境中感知、推理、规划、使用工具、维护记忆并持续适应的自主决策者。本文将这一新兴范式定义为智能体强化学习 (Agentic RL)。
Agentic RL的核心思想是:智能体强化学习框架LLM不仅是文本的被动发射器,更是嵌入在环境中的主动决策者,它通过强化学习,基于经验不断优化其行为策略。
与此相关的研究主要分为两大主流:
- LLM智能体 (LLM Agents):研究将LLM作为自主决策核心,探索其推理、规划、行动、交互和协作的能力。现有综述关注其架构、协作机制、演化路径以及工具使用等方面。
- 用于LLM的强化学习 (RL for LLMs):研究如何应用RL算法(如PPO、Q-learning)来提升LLM的指令遵循、伦理对齐和代码生成等能力。最著名的应用是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)及其变体。
尽管已有大量工作,但目前仍缺乏一个统一的理论框架来整合Agentic RL的概念。本文旨在填补这一空白,通过马尔可夫决策过程(Markov Decision Process, MDP)和部分可观马尔可夫决策过程(partially observable Markov decision process, POMDP)对Agentic RL进行形式化定义,并提出一个以能力为中心的分类体系,最后系统性地整理了相关的任务、环境和框架,为该领域的未来发展指明方向。
本文结构
本文结构如下:第二部分通过MDP/POMDP的视角形式化了从传统LLM RL到Agentic RL的范式转变。第三部分从模型能力视角审视Agentic RL,对规划、推理、工具使用等关键模块进行分类。第四部分探讨其在搜索、代码生成、多智能体系统等领域的应用。第五部分整合了相关的开源环境和框架。第六部分讨论了开放挑战和未来方向,最后进行总结。

预备知识:从 LLM RL 到 Agentic RL
LLM的训练始于行为克隆(Behavior Cloning),即在静态文本数据上进行最大似然估计(MLE)。随后的后训练(post-training)阶段通过监督微调(SFT)和强化微调(RFT)来提升模型能力并与人类偏好对齐。
早期的RFT(本文称之为基于偏好的RFT,Preference-Based RFT, PBRFT)主要目标是在固定的偏好数据集上优化模型。随着具备推理和工具使用能力的LLM(如OpenAI o1, o3, DeepSeek-R1)的出现,研究焦点开始从PBRFT转向为特定任务和动态环境量身定制的Agentic RL。
本节将形式化地描述从PBRFT到Agentic RL的范式转变。
马尔可夫决策过程
RL微调过程可以形式化为一个七元组 \(\langle\mathcal{S},\mathcal{O},\mathcal{A},\mathcal{P},\mathcal{R},T,\gamma\rangle\) ,其中 \(\mathcal{S}\) 是状态空间,\(\mathcal{O}\) 是观测空间,\(\mathcal{A}\) 是动作空间,\(\mathcal{P}\) 是状态转移概率,\(\mathcal{R}\) 是奖励函数,\(T\) 是任务 horizon,\(\gamma\) 是折扣因子。
PBRFT PBRFT的RL训练过程是一个退化的MDP,其元组为:
\[\langle\mathcal{S}_{\text{trad}},\mathcal{A}_{\text{trad}},\mathcal{P}_{\text{trad}},\mathcal{R}_{\text{trad}},T=1\rangle.\]Agentic RL Agentic RL的RL训练过程被建模为一个POMDP:
\[\langle\mathcal{S}_{\text{agent}},\mathcal{A}_{\text{agent}},\mathcal{P}_{\text{agent}},\mathcal{R}_{\text{agent}},\gamma,\mathcal{O}\rangle,\]其中智能体根据当前状态 \(s_{t}\in\mathcal{S}_{\text{agent}}\) 接收到观测 \(o_{t}=O(s_{t})\)。
PBRFT与Agentic RL的核心区别总结如下表。简言之,PBRFT在完全观测的固定数据集上优化单轮的句子输出,而Agentic RL在部分可观测的可变环境中优化多轮的语义级行为。
PBRFT与Agentic RL的形式化对比
| PBRFT | Agentic RL | |
|---|---|---|
| MDP 类型 | 单步退化MDP | 时序扩展POMDP |
| 状态空间 \(\mathcal{S}\) | ${s_0}$ (单个prompt) | 动态演化的世界状态 |
| 动作空间 \(\mathcal{A}\) | 仅文本生成 \(\mathcal{A}_{\text{text}}\) | 文本生成 \(\mathcal{A}_{\text{text}}\) 和结构化动作 \(\mathcal{A}_{\text{action}}\) |
| 转移概率 \(\mathcal{P}\) | 确定性(无环境变化) | 随机性(环境随动作变化) |
| 奖励函数 \(\mathcal{R}\) | \(r(a)\) (基于最终回复的标量奖励) | \(R(s_t, a_t)\) (包含中间步骤和最终任务的奖励) |
| 学习目标 \(J(\theta)\) | \(\mathbb{E}_{a\sim\pi_{\theta}}[r(a)]\) (最大化单步期望奖励) | \(\mathbb{E}_{\tau\sim\pi_{\theta}}\left[\sum_{t=0}^{T-1}\gamma^{t}R(s_t, a_t)\right]\) (最大化累计折扣奖励) |
环境状态
- PBRFT: 环境状态是静态的,每个回合从一个prompt \(s_0\) 开始,生成一个回复后立即结束。其MDP是单步的($T=1$),状态空间只有一个元素:\(\mathcal{S}_{\text{trad}}=\{\text{prompt}\}\)。
- Agentic RL: LLM智能体在多时间步内与环境交互。状态 \(s_t\) 会随智能体的动作 \(a_t\) 而演化:\(s_{t+1}\sim P(s_{t+1}\mid s_{t},a_{t})\)。交互是动态且时序扩展的。
动作空间
在Agentic RL中,动作空间 \(\mathcal{A}_{\text{agent}}=\mathcal{A}_{\text{text}}\cup\mathcal{A}_{\text{action}}\) 分为两部分:
- \(\mathcal{A}_{\text{text}}\):自回归解码生成自由形式的自然语言。
- \(\mathcal{A}_{\text{action}}\):通过特殊token(如\(<tool_code>\)和\(</tool_code>\))界定的结构化、非语言动作,用于调用外部工具或与环境交互。
这两类动作在语义和功能上完全不同:\(\mathcal{A}_{\text{text}}\) 用于交流,不直接改变外部状态;\(\mathcal{A}_{\text{action}}\) 用于执行命令,获取信息或改变环境状态。
转移动态
- PBRFT: 转移是确定性的,\(\mathcal{P}(s_{1}\mid s_{0},a)=1\),没有不确定性。
- Agentic RL: 环境在不确定性下演化,\(s_{t+1}\sim \mathcal{P}(s_{t+1}\mid s_{t},a_{t})\)。智能体通过一系列动作与环境进行交互,迭代地结合通信、信息获取和环境操纵。
奖励函数
- PBRFT: 奖励函数 \(\mathcal{R}_{\text{trad}}(s_{0},a)=r(a)\) 是一个标量分数,由一个基于规则的验证器或一个参数化的奖励模型提供,没有中间反馈。
- Agentic RL: 奖励函数是基于下游任务的,可以是稀疏的、稠密的或学习的:
学习目标
- PBRFT: 优化目标是最大化单轮回复的奖励:\(J_{\text{trad}}(\theta)=\mathbb{E}_{a\sim\pi_{\theta}}\bigl{[}r(a)\bigr{]}\)。
- Agentic RL: 优化目标是最大化累计折扣奖励:\(J_{\text{agent}}(\theta)=\mathbb{E}_{\tau\sim\pi_{\theta}}\left[\,\sum_{t=0}^{T-1}\gamma^{t}R_{\text{agent}}(s_{t},a_{t})\right]\)。
RL算法
主流的RL算法包括REINFORCE、PPO、DPO和GRPO等,它们在PBRFT和Agentic RL中都扮演着关键角色。
- REINFORCE: 基础的策略梯度算法,通过增加高回报动作的概率来优化策略。
- 近端策略优化 (Proximal Policy Optimization, PPO): 因其稳定性和可靠性成为LLM对齐的主流算法。它通过裁剪目标函数来限制策略更新步长,防止破坏性的策略变化。其缺点是需要一个与策略网络同样大小的critic网络,增加了训练参数。
- 直接偏好优化 (Direct Preference Optimization, DPO): 一种开创性的方法,它完全绕过了独立的奖励模型,将问题重构为对人类偏好数据的似然优化目标。虽然DPO消除了critic,但其性能高度依赖于静态偏好数据集的质量和覆盖范围。
- 组相对策略优化 (Group Relative Policy Optimization, GRPO): 为解决PPO critic网络庞大的问题而提出。它对一组回复进行操作,利用组内相对奖励来计算优势函数,从而消除了对绝对值critic的需求。这种方法样本效率高,计算开销小。
下表总结了这些算法家族中的流行变体。
| 家族 | 方法 | 主要贡献 | 需要Critic | 需要奖励模型 | 数据类型 |
|---|---|---|---|---|---|
| PPO | PPO [12] | 稳定、可靠的策略更新,通过剪裁目标函数 | 是 | 是 | 提示-回复 |
| PPO-max [37] | 将PPO应用于上下文学习(ICL) | 否 | 是 | 提示-回复 | |
| DPPO [38] | 将PPO扩展到分布式环境,以实现可扩展性 | 是 | 是 | 提示-回复 | |
| IPO-PPO [39] | 将IPO与PPO结合,以防止过拟合 | 是 | 是 | 提示-回复 | |
| G-PPO [40] | 在PPO中引入组蒸馏,以提高稳定性 | 是 | 是 | 提示-回复 | |
| DPO | DPO [29] | 将RLHF重新表述为二元分类,消除了奖励模型 | 否 | 否 | 偏好对 |
| \(\beta\)-DPO [41] | 允许灵活的\(\beta\),以实现更优的策略 | 否 | 否 | 偏好对 | |
| rDPO [42] | 利用合成数据和多目标优化扩展DPO | 否 | 否 | 偏好对 | |
| IPO [35] | 通过正则化防止过拟合,提高鲁棒性 | 否 | 否 | 偏好对 | |
| KTO [36] | 从二进制信号(可取/不可取)中学习,而非成对比较 | 否 | 否 | 偏好对 | |
| vDPO [43] | 将DPO扩展到多模态设置 | 否 | 否 | 偏好对 | |
| SLiC [44] | 直接从未标记数据中学习,无需成对偏好 | 否 | 否 | 偏好对 | |
| OPO [45] | 将DPO扩展到离线RL,以实现更有效的策略改进 | 否 | 否 | 提示-回复 | |
| GRPO | GRPO [31] | 用组相对奖励替代绝对值critic | 否 | 是 | 提示-回复 |
| PRO [46] | 提出了一种新颖的策略优化方法,拒绝低奖励的输出 | 否 | 是 | 提示-回复 | |
| ARO [47] | 通过在序列级别聚合奖励来提高在线RL的效率 | 否 | 是 | 提示-回复 | |
| RRHF [48] | 利用排名响应来对齐LLM,平衡了SFT和RL | 否 | 是 | 提示-回复 | |
| Grok [49] | 通过自我反思和与工具的交互进行学习 | 否 | 是 | 提示-回复 | |
| RSO [50] | 在线微调方法,利用排名响应,无需critic | 否 | 是 | 提示-回复 | |
| SOTO [51] | 一种新颖的在线微调方法,无需critic | 否 | 是 | 提示-回复 | |
| CPO [52] | 在线微调方法,无需critic | 否 | 是 | 提示-回复 | |
| RO/RAO/RPO [53] | 通过在token和序列级别聚合奖励来增强在线RL | 否 | 是 | 提示-回复 | |
| BPO/SteerLM [54] | 通过结合强化学习和监督微调来对齐LLM | 否 | 是 | 偏好对 | |
| ReMax [55] | 通过将奖励最大化纳入解码过程来增强LLM | 否 | 是 | 提示-回复 | |
| APPO/APRL [56] | 自适应策略优化,无需critic | 否 | 是 | 提示-回复 | |
| SPO [57] | 通过自我博弈进行策略改进,无需critic | 否 | 是 | 提示-回复 | |
| GDC/GDP [58] | 通过在组响应上应用一致性来增强策略 | 否 | 否 | 偏好对 | |
| TRL [59] | 在线微调方法,无需critic | 否 | 是 | 提示-回复 | |
| SRPO [60] | 通过自我奖励来增强稀疏奖励环境中的策略 | 否 | 是 | 提示-回复 | |
| PaLM-RL [61] | 通过结合PPO和DPO来对齐LLM | 是 | 是 | 偏好对 | |
| ReST [62] | 一种在线微调方法,无需critic | 否 | 是 | 提示-回复 | |
| SPIN [63] | 通过自我博弈进行策略改进,无需人工注释 | 否 | 否 | 提示-回复 |
分类体系:模型能力视角
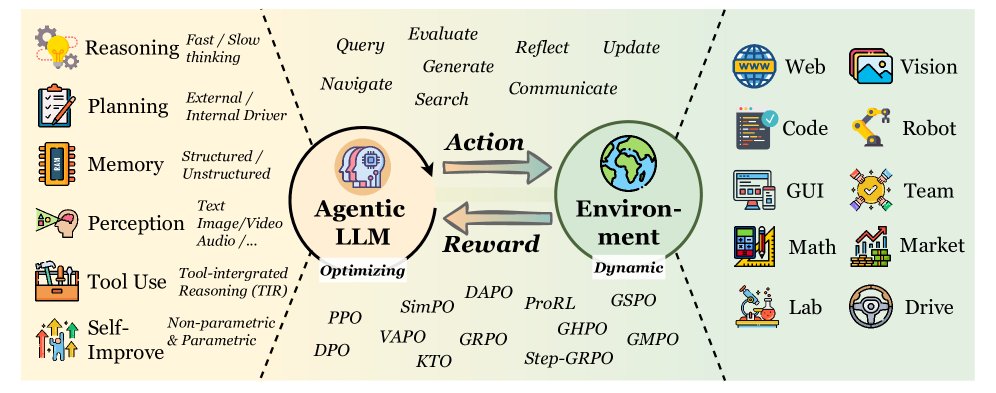
本节将Agentic RL概念化为对一个自主智能体的原则性训练,该智能体由规划、工具使用、记忆、自省、推理、感知等一系列关键能力/模块组成。传统上,一个智能体包含一个LLM核心,并配合规划、推理、工具调用、记忆和反思等机制。
Agentic RL将这些组件视为可共同优化的相互依赖的策略:用于规划的RL学习多步决策轨迹;用于记忆的RL塑造检索和编码动态;用于工具使用的RL优化调用时机和保真度;用于反思的RL驱动内部自我监督和自我完善。
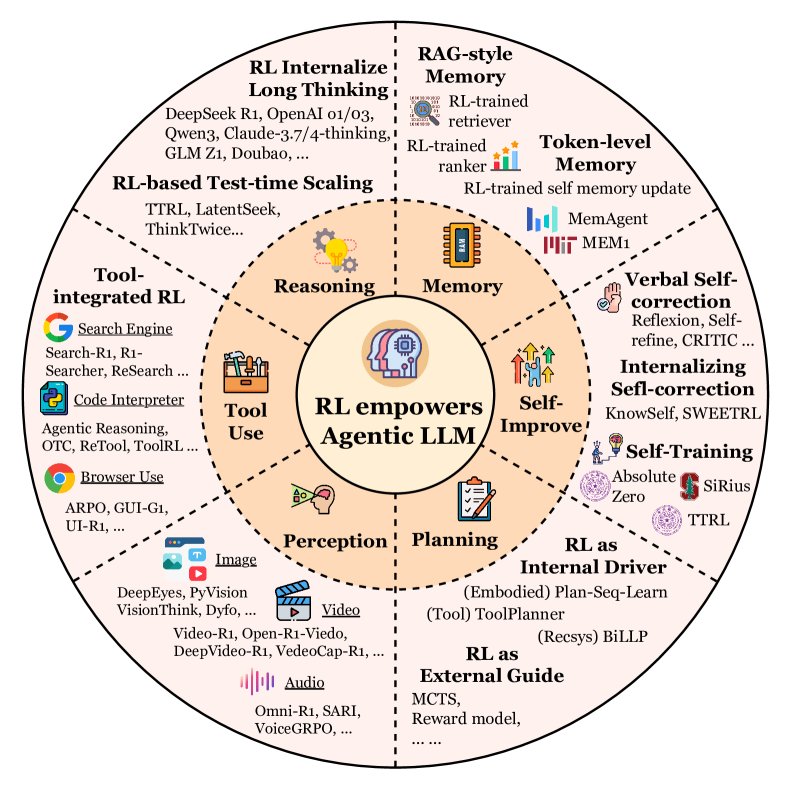
规划
规划是为实现目标而深思熟虑一系列行动的能力,是AI的基石。早期的工作通过提示工程(如ReAct)利用LLM的固有能力,但缺乏从经验中适应的机制。RL的出现填补了这一空白,使智能体能通过环境反馈来优化其规划策略。目前,RL与智能体规划的集成主要体现为两种范式:
RL作为规划的外部向导
在这种范式中,RL作为规划过程的外部指导。LLM的主要角色是在一个结构化的搜索框架(如蒙特卡洛树搜索 MCTS)内生成候选动作。RL并不直接微调LLM,而是用来训练一个辅助的奖励或启发式函数,该函数用于评估不同规划轨迹的质量,从而引导搜索。代表性工作如RAP和LATS,它们利用一个由RL辅助的模型来评估LLM生成的步骤,将搜索引向更有希望的解决方案。在这里,LLM是知识丰富的动作提议者,而RL提供高效探索所需的自适应评估反馈。
RL作为规划的内部驱动力
第二种更集成化的范式将RL定位为智能体核心规划能力的内部驱动力。这种方法直接将LLM视为策略模型,并通过与环境的直接交互来优化其规划行为。RL的反馈不再是指导外部搜索算法,而是直接用于优化LLM生成规划的内部策略。这可以通过基于RLHF的方法实现,例如在成功与失败的轨迹上使用DPO(如ETO),或通过终身学习框架实现。例如,VOYAGER通过与环境的交互迭代地构建和完善技能库。这种范式将LLM从静态生成器转变为一个持续进化的自适应策略,增强其在动态环境中的鲁棒性和自主性。例如,AdaPlan及其PilotRL框架,在文本游戏环境中利用全局规划指导和渐进式RL来增强LLM智能体的长时规划和执行协调能力。
展望:深思熟虑与直觉的综合
智能体规划的未来在于综合这两种范式,超越“深思熟虑”(如基于搜索的规划)与“直觉”(如端到端策略)之间的二元对立。未来的高级智能体可能会将快速、直觉式的决策与需要时进行的、更慢、更深思熟虑的规划相结合。RL将是实现这种动态平衡的关键,它能够学习何时依赖LLM的内在规划能力,何时启动更耗费计算的显式搜索过程,从而实现既高效又最优的决策。