The Llama 3 Herd of Models
-
ArXiv URL: http://arxiv.org/abs/2407.21783v3
-
作者: Natascha Parks; Corinne Wong; Brian Gamido; Jeff Marcus; Bo Wu; Filip Radenovic; Sa-hana Chennabasappa; Feng Tian; Raghu Nayani; Aur’elien Rodriguez; 等489人
-
发布机构: Meta
TL;DR
本文介绍了 Llama 3 模型家族,其中旗舰模型是一个拥有 405B 参数的密集型 Transformer,通过在 15T 多语言 token 上进行大规模预训练,并采用稳定可扩展的架构和训练方法,使其在多项基准测试中达到了与 GPT-4 等顶级模型相当的性能水平。
关键定义
本文主要基于现有概念进行构建和扩展,并引入了以下关键实践:
- Llama 3 模型家族 (Llama 3 Herd of Models):一个包含 8B、70B 和 405B 三种参数规模的系列模型。该系列模型原生支持多语言、代码、推理和工具使用能力,其中 405B 的预训练和指令微调版本被公开发布。
- 组合式多模态方法 (Compositional Approach for Multimodality):一种将图像、视频、语音能力集成到 Llama 3 中的方法。该方法首先独立预训练各模态的编码器(Encoder),然后通过训练一个轻量级的适配器(Adapter)将编码器与预训练的语言模型连接起来,整个过程中语言模型的参数保持不变。
- 4D 并行 (4D Parallelism):一种为训练超大规模模型而设计的并行策略组合,它整合了张量并行 (Tensor Parallelism, TP)、流水线并行 (Pipeline Parallelism, PP)、上下文并行 (Context Parallelism, CP) 和数据并行 (Data Parallelism, DP),以高效地将计算和内存负载分布到数万个 GPU 上。
- 数据退火 (Data Annealing):在预训练后期,使用少量高质量的特定领域(如代码和数学)数据继续训练模型的一种策略。本文发现这种方法能显著提升模型在相应领域的性能,尤其对小模型效果明显。
相关工作
当前,基础模型(Foundation Models)是现代人工智能系统的核心。其发展依赖于三大关键杠杆:数据、规模和复杂性管理。尽管业界已有多款强大的模型,但仍存在以下挑战:
- 数据瓶颈:现有模型的训练数据在数量和质量上仍有提升空间。如何构建更大规模、更高质量、更多样化的多语言、代码、推理数据集是提升模型能力的关键。
- 规模扩展的挑战:训练更大规模的模型(如千亿乃至万亿参数级别)需要庞大的计算资源和先进的工程技术,对训练稳定性、效率和可靠性提出了极高要求。
- 训练方法的复杂性:一些先进的训练算法,如复杂的强化学习方法,虽然可能带来性能提升,但往往难以扩展且训练过程不稳定,增加了开发和迭代的难度。
本文旨在解决这些问题,目标是通过系统性地优化数据处理、极致地扩大模型和训练规模,并坚持使用简单、稳定、可扩展的架构和训练策略,来开发出一款性能顶尖且公开发布的基础模型。
本文方法
整体架构与训练流程
Llama 3 的开发遵循一个两阶段流程,并探索了多模态扩展路径。

Figure 1: Llama 3 总体架构与训练流程图解
- 语言模型预训练 (Language Model Pre-training):在大约 15.6T 多语言文本 token 上训练一个大型语言模型进行下一词元预测(next-token prediction)。此阶段赋予模型语言理解和世界知识。初始预训练使用 8K 上下文窗口,之后通过继续预训练将窗口扩展到 128K。
- 语言模型后训练 (Language Model Post-training):通过监督微调 (Supervised Finetuning, SFT)、拒绝采样 (Rejection Sampling, RS) 和直接偏好优化 (Direct Preference Optimization, DPO) 等技术,将预训练模型与人类偏好对齐,使其能够遵循指令。此阶段也用于集成工具使用等新能力,并实施安全缓解措施。
此外,本文还尝试了组合式多模态扩展,通过训练独立的图像和语音编码器,并使用适配器将其与语言模型连接,以赋予模型处理图像、视频和语音的能力。
预训练
预训练是 Llama 3 取得卓越性能的基石,涉及数据、架构、扩展法则和基础设施四个方面。
预训练数据
本文构建了一个包含约 15T token 的大规模、高质量预训练数据集,数据截止到 2023 年底。
- 数据处理流程:
- 数据源与清洗:主要数据来自网络,通过自研解析器提取高质量文本,并特别处理了数学和代码内容。移除了含有大量个人可识别信息 (Personally Identifiable Information, PII) 和不安全内容的域名。
- 去重:在 URL、文档 (MinHash) 和行级别进行了三轮严格去重。
- 过滤:使用启发式规则(如 n-gram 重复率、脏词计数)和基于模型的质量分类器(使用 Llama 2 标注数据训练的 DistilRoberta 分类器)来移除低质量和异常文档。
- 特定领域数据:构建了专门的流水线来提取与代码和数学相关的网页,并使用特定领域的分类器进行筛选。
- 多语言数据:使用 fasttext 进行语言识别,并在各语言内部进行去重和质量过滤。
-
数据混合比例:通过知识分类和扩展法则实验,最终确定了数据配比:约 50% 通用知识、25% 数学与推理、17% 代码和 8% 多语言数据。
- 数据退火:在预训练后期,使用少量高质量的代码和数学数据进行“退火”训练,发现此举能显著提升 8B 模型在 GSM8k 和 MATH 等基准上的性能。但对 405B 模型效果不明显,表明大模型本身已具备强大的上下文学习能力。
模型架构
Llama 3 采用了标准的密集型 Transformer 架构,其性能提升主要源于数据和规模,而非架构的根本性创新。相较于 Llama 2,主要有以下几点微调:
- 分组查询注意力 (Grouped Query Attention, GQA):使用 8 个键值头 (key-value heads) 的 GQA 来提升推理速度并减少解码时的缓存占用。
- 注意力掩码 (Attention Mask):在序列内使用注意力掩码阻止不同文档间的相互关注,这在长序列继续预训练中尤为重要。
- 词汇表 (Vocabulary):扩展至 128K token,结合了 \(tiktoken\) 的 100K token 和额外的 28K 多语言 token,提高了数据压缩率和多语言性能。
- RoPE 基频:将 RoPE 的基频参数 \(θ\) 提升至 500,000,以更好地支持长上下文。
| 8B | 70B | 405B | |
|---|---|---|---|
| 层数 | 32 | 80 | 126 |
| 模型维度 | 4,096 | 8,192 | 16,384 |
| FFN 维度 | 14,336 | 28,672 | 53,248 |
| 注意力头数 | 32 | 64 | 128 |
| 键/值头数 | 8 | 8 | 8 |
| 峰值学习率 | 3 × 10⁻⁴ | 1.5 × 10⁻⁴ | 8 × 10⁻⁵ |
| 激活函数 | SwiGLU | ||
| 词汇表大小 | 128,000 | ||
| 位置嵌入 | RoPE (θ = 500,000) |
Table 3: Llama 3 关键超参数概览
扩展法则 (Scaling Laws)
为了在给定的计算预算下确定最优模型尺寸并预测其性能,本文采用了一种两阶段的扩展法则制定方法:
-
建立损失与计算量的关系:通过在不同计算预算(6 × 10¹⁸ 至 10²² FLOPs)下训练一系列小模型,绘制出 IsoFLOPs 曲线,找到每个计算量下的“计算最优”模型尺寸,并拟合出最优训练 token 数与计算预算的幂律关系:
\[N^*(C) = AC^{\alpha}\]最终推断出在 3.8 × 10²⁵ FLOPs 预算下,最优模型约为 402B 参数,训练于 16.55T token。基于此,最终选择了 405B 参数的模型。
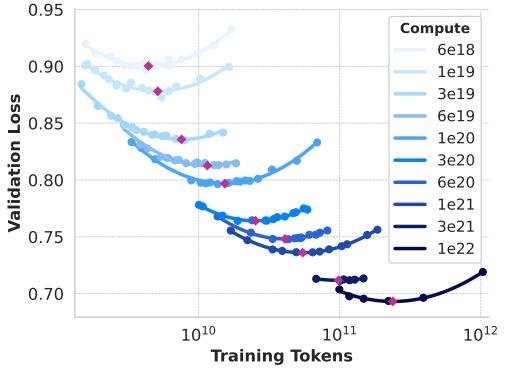 Figure 2: 不同计算量下的 IsoFLOPs 曲线
Figure 2: 不同计算量下的 IsoFLOPs 曲线
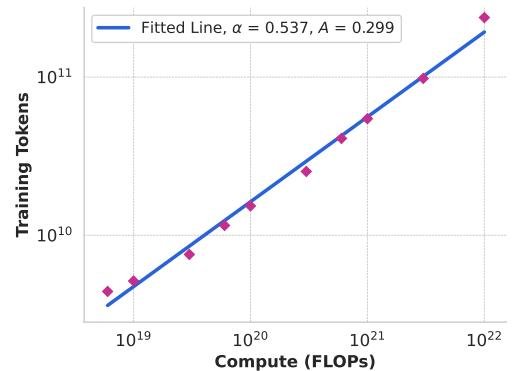 Figure 3: 计算最优模型的训练 token 数与预训练计算预算的关系
Figure 3: 计算最优模型的训练 token 数与预训练计算预算的关系
- 预测下游任务性能:首先将下游任务的负对数似然与训练 FLOPs 相关联,然后利用 Llama 2 等旧模型的数据,建立负对数似然与任务准确率之间的 S 型关系。这种方法能够跨越四个数量级准确预测最终旗舰模型在 ARC Challenge 等基准上的性能。
 Figure 4: ARC Challenge 性能的扩展法则预测
Figure 4: ARC Challenge 性能的扩展法则预测
基础设施与训练效率
Llama 3 405B 的训练在一系列专为大规模 AI 设计的生产级基础设施上完成,并实现了多项效率优化。
- 训练基础设施:
- 计算:在多达 16,000 个 H100 GPU 上进行训练,这些 GPU 部署在 Meta 的 Grand Teton AI 服务器平台上。
- 存储:使用 Tectonic 分布式文件系统,提供高达 7 TB/s 的峰值吞吐能力,以支持高频的模型检查点写入。
- 网络:使用了基于 RoCE (RDMA over Converged Ethernet) 的三层 Clos 网络架构,连接 24K 个 GPU。通过增强型 ECMP (E-ECMP) 和深缓冲交换机等技术优化负载均衡和拥塞控制。
- 模型扩展的并行策略:
- 4D 并行:采用 [TP, CP, PP, DP] 的顺序组合,将网络带宽需求最高的 TP 限制在服务器内部,而将容忍更高延迟的 DP 部署在外部。
 Figure 5: 4D 并行策略示意图
Figure 5: 4D 并行策略示意图 - 流水线并行优化:改进了调度机制,使其可以灵活地设置微批次数量,解决了内存和计算不平衡问题,并减少了流水线气泡,实现了在 8K 序列长度下无需激活检查点即可训练。
 Figure 6: Llama 3 中流水线并行的图解
Figure 6: Llama 3 中流水线并行的图解 - 上下文并行:采用基于 \(all-gather\) 的方法实现上下文并行,虽然会暴露通信延迟,但由于 GQA 使得 K/V 张量远小于 Q 张量,该开销可忽略不计,且实现更灵活。
- 4D 并行:采用 [TP, CP, PP, DP] 的顺序组合,将网络带宽需求最高的 TP 限制在服务器内部,而将容忍更高延迟的 DP 部署在外部。
通过这些优化,405B 模型在 16K GPU 上的训练实现了 38-41% 的模型 FLOPs 利用率 (Model FLOPs Utilization, MFU)。
| GPUs | TP | CP | PP | DP | 序列长度 | 每DP批大小 | 每批Token | TFLOPs/GPU | BF16 MFU | | — | — | — | — | — | — | — | — | — | — | | 8,192 | 8 | 1 | 16 | 64 | 8,192 | 32 | 16M | 430 | 43% | | 16,384 | 8 | 1 | 16 | 128 | 8,192 | 16 | 16M | 400 | 41% | | 16,384 | 8 | 16 | 16 | 8 | 131,072 | 16 | 16M | 380 | 38% | Table 4: Llama 3 405B 预训练各阶段的扩展配置和 MFU
- 可靠性与运维挑战: 在对 16K GPU 进行训练的复杂环境中,通过自动化运维和快速诊断工具(如 PyTorch 的 NCCL flight recorder),本文实现了超过 90% 的有效训练时间。在 54 天的快照期间,GPU 问题是导致意外中断最主要的原因,占所有意外中断的 58.7%。
| 组件 | 类别 | 中断次数 | 中断百分比 | | — | — | — | — | | 故障 GPU | GPU | 148 | 30.1% | | GPU HBM3 内存 | GPU | 72 | 17.2% | | 软件 Bug | 依赖项 | 54 | 12.9% | | 网络交换机/线缆 | 网络 | 35 | 8.4% | | 主机维护 | 非计划维护 | 32 | 7.6% | | GPU SRAM 内存 | GPU | 19 | 4.5% | | GPU 系统处理器 | GPU | 17 | 4.1% | | … | … | … | … | Table 5: Llama 3 405B 预训练 54 天期间意外中断的根本原因分类
实验结论
本文对 Llama 3 模型家族进行了广泛的评估,实验结果表明其强大的性能。
- 关键实验结果:
- 与顶级模型对比:Llama 3.1 405B 在多个关键基准测试中表现出色,与 GPT-4 和 Claude 3.5 Sonnet 等领先的闭源模型性能相当,甚至在某些任务(如 MGSM,多语言数学推理)上取得最佳成绩。
- 同尺寸模型对比:Llama 3.1 8B 和 70B 模型在其各自的尺寸级别中是表现最好的,显著优于 Gemma、Mistral 等同类开源模型。
- 多能力验证:模型在通用知识 (MMLU)、代码生成 (HumanEval)、数学推理 (GSM8K, MATH)、长上下文处理 (InfiniteBench) 和工具使用 (BFCL) 等方面均展示了顶尖或接近顶尖的水平。
| 类别 | 基准测试 | Llama 3 405B | Nemotron 4 340B | GPT-4 (0125) | GPT-4o | Claude 3.5 Sonnet | | — | — | — | — | — | — | — | | 通用 | MMLU (5-shot) | 87.3 | 82.6 | 85.1 | 89.1 | 89.9 | | | IFEval | 88.6 | 85.1 | 84.3 | 85.6 | 88.0 | | 代码 | HumanEval (0-shot) | 89.0 | 73.2 | 86.6 | 90.2 | 92.0 | | 数学 | GSM8K (8-shot, CoT) | 96.8 | 92.3♢ | 94.2 | 96.1 | 96.4♢ | | | MATH (0-shot, CoT) | 73.8 | 41.1 | 64.5 | 76.6 | 71.1 | | 推理 | GPQA (0-shot, CoT) | 51.1 | – | 41.4 | 53.6 | 59.4 | | 工具使用 | BFCL | 88.5 | 86.5 | 88.3 | 80.5 | 90.2 | | 长上下文 | InfiniteBench/En.MC | 83.4 | – | 72.1 | 82.5 | – | | 多语言 | MGSM (0-shot, CoT) | 91.6 | – | 85.9 | 90.5 | 91.6 | Table 2 (节选): Llama 3 405B 与顶级模型在关键基准上的性能对比
-
验证的优势: 实验结果有力地证明了本文所采取策略的有效性:通过大规模、高质量的数据,巨大的模型规模,以及简单、稳定的架构和训练方法,可以开发出世界一流的基础模型。 准确的扩展法则预测,以及在极大规模下保持高训练效率的工程实践,是本次成功的关键技术保障。
-
最终结论: Llama 3 系列模型,特别是公开发布的 405B 版本,为开源社区树立了新的性能标杆。它证明了通过在数据、规模和工程复杂性管理上进行系统性投入,开源模型完全有能力达到与最顶尖的闭源模型相媲美的水平。本文希望 Llama 3 的开放能激发社区的创新浪潮,并加速通往负责任的通用人工智能(AGI)之路。