The Prompt Engineering Report Distilled: Quick Start Guide for Life Sciences
-
ArXiv URL: http://arxiv.org/abs/2509.11295v1
-
作者: Steven A Niederer
-
发布机构: Imperial College London; The Alan Turing Institute
TL;DR
本文为生命科学领域的研究人员提炼了一份提示工程(Prompt Engineering)快速入门指南,重点介绍了六种核心技术(零样本、少样本、思维生成、集成、自我批评和分解),并提供了具体的用例、最佳实践和常见陷阱,旨在帮助研究人员从机会主义的提问方式转变为系统、高效的实践。
关键定义
本文沿用了提示工程领域的一些关键定义,并对特定术语进行了操作性区分:
- 大型语言模型 (Large Language Models, LLMs):指代基于 Transformer 架构、在海量文本语料库上训练的神经网络,如 GPT-4、Claude、Gemini。
- 智能体 (Agents):指增强了工具使用能力、记忆系统和自主任务执行框架(如 OpenAI 的 Deep Research、Anthropic 的 Claude Code)的 LLM。
- 零样本提示 (Zero-shot Prompting):用户只向 LLM 提供请求或问题,不提供任何期望输出的范例。这依赖于模型在预训练数据中已见过类似任务。
- 少样本提示 (Few-shot Prompting):用户向 LLM 提供少量(通常为2-10个)示例,展示任务所需的输入-输出结构,利用模型的上下文学习能力来推断任务模式。
- 思维链 (Chain-of-thought, CoT):一种提示技术,引导 LLM 在给出最终答案前,通过一系列中间推理步骤来解决复杂问题,模拟序贯思考过程。
引言
尽管像 ChatGPT-5 Pro 和 Claude Opus 4.1 这样的旗舰大语言模型(LLMs)开箱即用,表现出色,但对于学术或专业领域的复杂任务(如文献提取、编码、数据分析),简单模糊的提示(例如“让这段话听起来更专业”)往往效果不佳。提示工程(Prompt Engineering),即通过各种条件精心设计和开发提示的过程,对于生成高质量、可靠的回答至关重要。
目前,LLM 在科研领域的应用激增,从心血管疾病研究、蛋白质相互作用预测到化学合成辅助等。然而,大多数非AI专家仍采用机会主义而非系统性的方式进行提示。本综述旨在为生命科学研究者提炼提示工程的核心技术,将《The Prompt Report》中概述的58种技术精简为六大核心类别:零样本(zero-shot)、少样本(few-shot)、思维生成(thought generation)、集成(ensembling)、自我批评(self-criticism)和分解(decomposition),并结合具体用例进行阐述。本文的目标是提供可操作的指导,帮助研究人员从临时的提问方式过渡到一种高效、低摩擦的系统性实践。
提示与提示工程
本文专注于基于文本的提示技术。根据《The Prompt Report》,提示技术可分为58种,归属于6个主要类别。本节将重点讨论这些类别,并结合研究领域的特定用例进行介绍。
Zero-shot
零样本(Zero-shot)提示指的是用户不提供任何范例,直接向LLM提出问题。其效果依赖于模型预训练数据中是否包含相似内容。构建零样本提示的最佳方式是明确给出请求以及规则(能做什么和不能做什么)。
图1. Zero-shot 提示示例。 这是大多数学者使用聊天机器人的方式。虽然有效,但这两种提示触及了使用聊天机器人的两个关键失败点:1) 从 LLM 获取知识;2) 从学术来源中总结密集、细微的信息。
在学术工作中,利用零样本提示生成文章摘要非常普遍,但这存在风险。最新研究表明,LLM生成的摘要往往缺乏细微之处,且比人类作者的摘要更容易出现过度概括。
为了提升零样本提示的质量,本文基于 Peters 和 Chin-Yee (2025) 的研究,对摘要生成任务的提示提出了改进建议。核心改进点包括:
- 增加领域特异性:明确告知模型文本所属的领域。
- 提供质量范例:给出高质量和低质量的摘要范例作为参考。
- 避免负面指令:用具体的正面指导(如如何核实信息)替代模糊的负面指令(如“不要引入不准确之处”)。
- 注意技术限制:处理长文本时,需注意 token 消耗,建议一次对话只处理一篇文章以保持准确性。
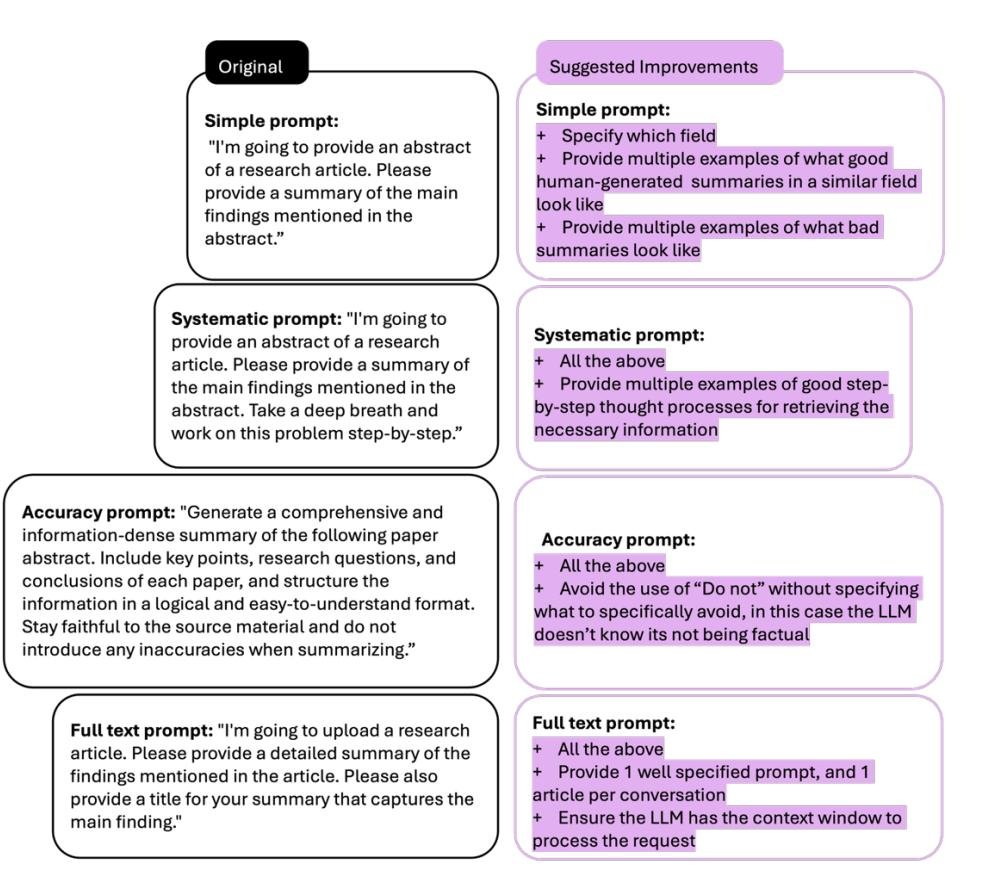
图2. 一个 zero-shot 提示案例研究。 左侧为 Peters 和 Chin-Yee (2025) 的原始提示,右侧为建议的改进。每项改进(+)代表一个可能改善结果的具体增强:增加领域特异性、融入质量范例、澄清指令以避免模糊性,以及解决技术限制。
上下文窗口与Token消耗
上下文窗口(Context Window)指 LLM 一次能处理(记忆)的 token 数量。一个 token 大约等于0.5个单词。超出上下文窗口会导致性能严重下降和幻觉。不同模型的免费版本上下文窗口大小差异巨大:ChatGPT 约为8k token,Gemini 为32k,而 Claude 则达到200k。一个典型的研究论文约占4k token。这意味着在处理多文档任务(如文献综述)时,Claude 的容量远超其他两者,这对任务的连贯性和全面性有深远影响。
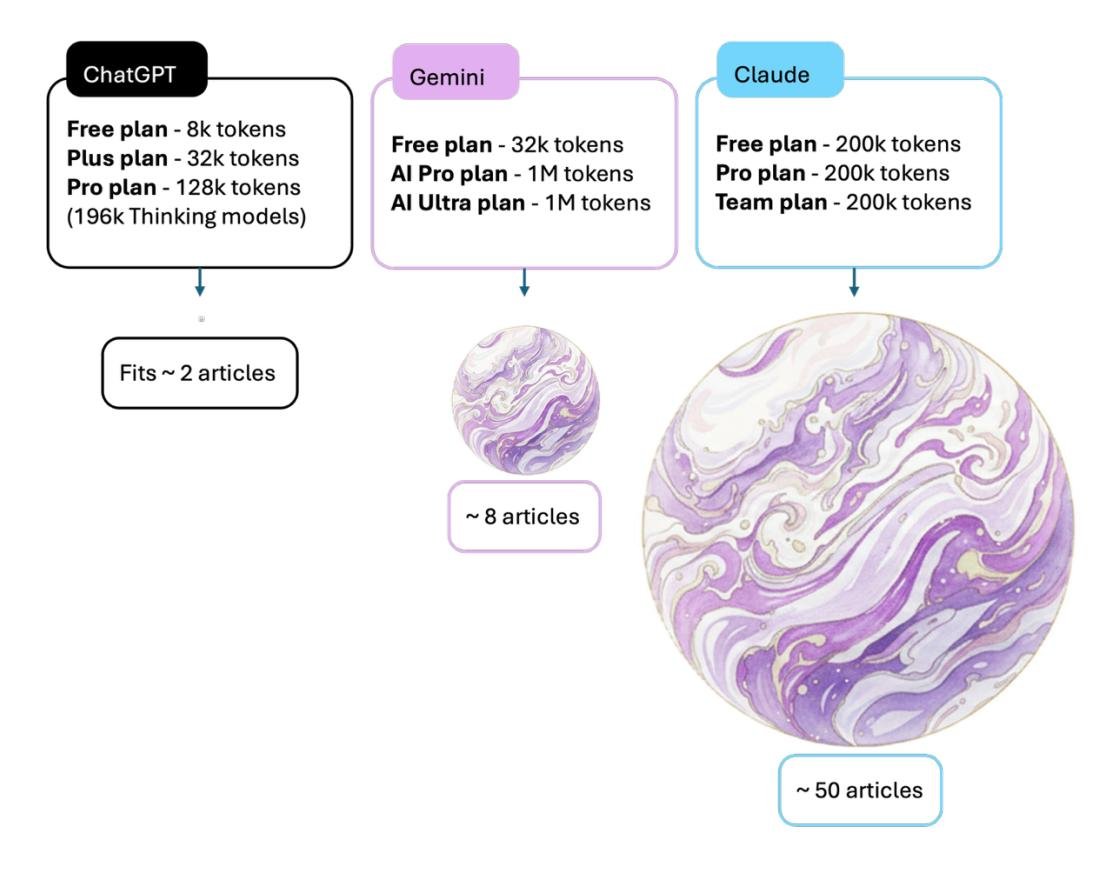
图3. 免费版 LLM 产品上下文窗口容量的比较可视化。 图中展示了 ChatGPT (8k tokens)、Gemini (32k tokens) 和 Claude (200k tokens) 的 token 限制及其订阅级别,球体大小与其上下文窗口容量成正比。该可视化将这些 token 限制转化为实际研究背景,显示免费版分别可容纳约2篇文章(ChatGPT)、8篇文章(Gemini)和50篇文章(Claude)。
角色设定
为 LLM 分配一个角色或“人格”(Persona),如“扮演一名临床医生”,是一种非常流行的技术。然而,这种角色是基于训练数据中统计模式的抽象,容易放大其中潜在的偏见和刻板印象。对于一个模糊的角色提示(如“临床医生的角色”),模型在多次独立对话中会产生不同但主题一致的响应,这反映了其输出的不稳定性和对训练数据中多种原型综合的结果。
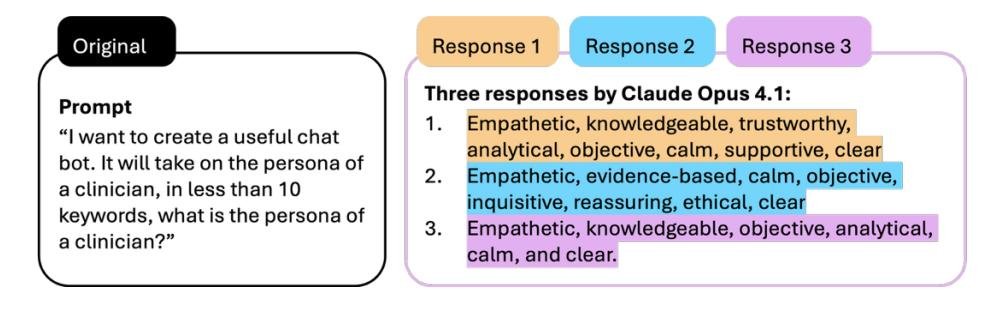
图4. LLM 角色解读在独立对话中的可变性。 相同的提示要求 Claude Opus 4.1 在10个关键词内描述“临床医生的角色”,在三个独立的对话线程中提交。尽管输入相同,模型产生了三组不同的属性,显示了语义重叠和显著的特征差异。
在实际应用中,角色设定可以非常复杂。例如,在一个化学应用案例中,研究者构建了一个AI团队,包含项目经理、文献综述专家、化学合成顾问等多个不同角色,每个角色都有明确的职责。另一种方法是让LLM扮演一个简单的“化学助手”,并提供清晰的输出格式示例。
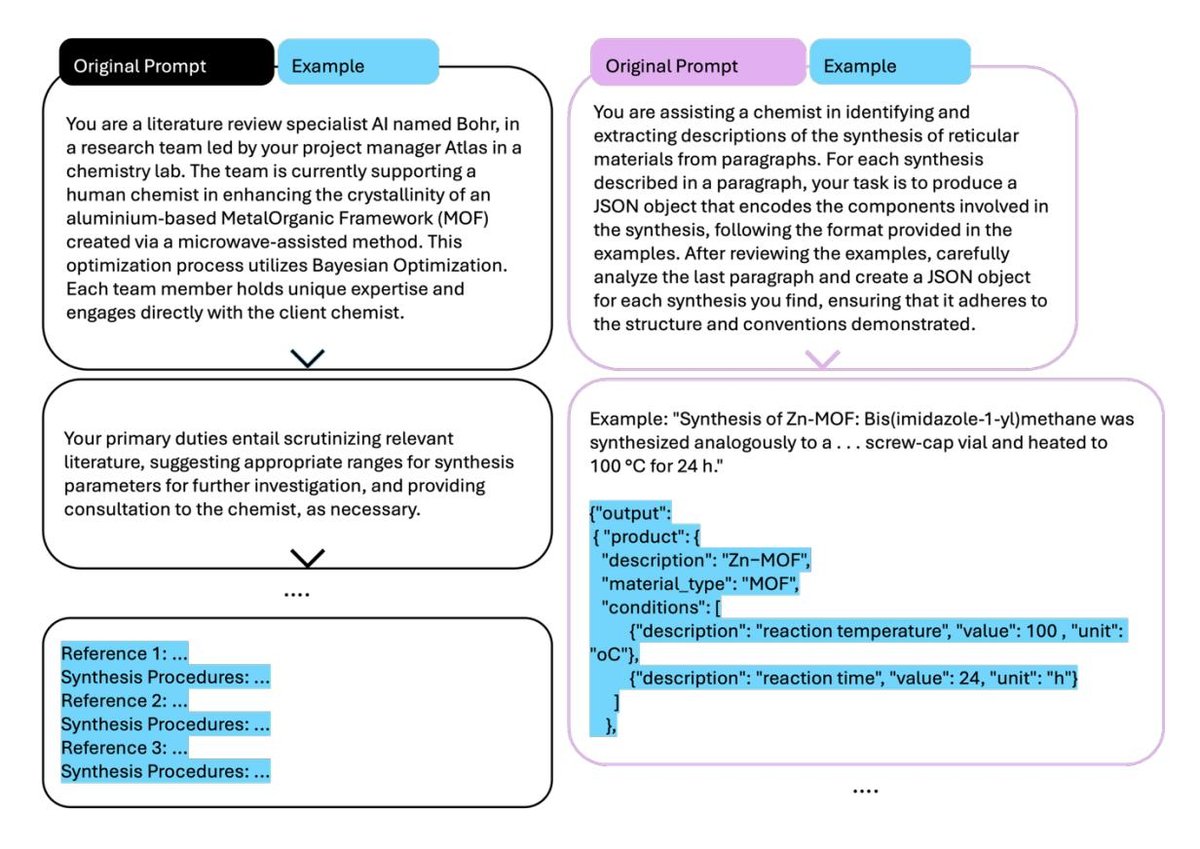
图5. 文献中角色与助手提示的示例。 左图:一个名为 Bohr 的文献综述专家角色,作为AI团队的一部分。右图:一个化学助手提示,用于从用户提供的信息中提取合成参数。
目前研究表明,在数学等客观任务中,为LLM分配专家角色带来的性能提升很小且不可靠,甚至可能导致不可预测的行为。
风格指导
LLM 在辅助学术写作、编辑和翻译方面已被广泛采用。约13.5%的PubMed摘要在2024年可能使用了LLM。尽管存在偏见和捏造引用等风险,但随着模型能力的提升,其可靠性正在增强。
为了有效地利用 LLM 进行文本编辑,本文提出了一个结构化框架:
- 明确任务:告知 LLM 这是文章的哪个部分(如引言)。
- 要求解释:让 LLM 解释其修改建议的理由。
- 引用原文:要求 LLM 引用被修改的原始文本,以核对并减少幻觉。
- 提供范例:给出符合期望的语法、风格和词汇选择的范例。
- 设定约束:明确要求保留领域特定的术语,不进行过度简化。

图6. 利用 LLM 进行文本编辑的推荐方法。 该框架展示了针对不同编辑任务(语法修正、风格改进、词汇优化)的提示工程策略,通过示例展示原文、建议修订和理由,以保持编辑过程的透明度。
Few-shot
少样本(Few-shot)提示通过提供少量(2-10个)输入-输出范例,利用模型的上下文学习能力来完成任务。相比零样本,2-3个示例就能显著提高任务理解能力。其核心是提供一个任务说明,并附上代表性的输入-输出对。
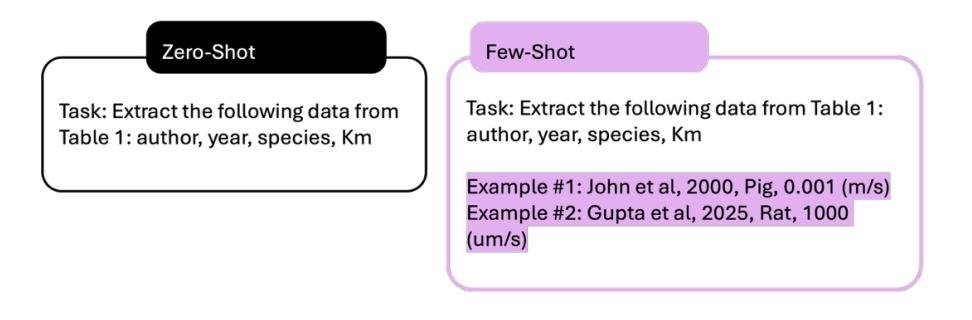
图7. 结构化数据提取的 zero-shot 和 few-shot 提示策略比较。 左侧的 zero-shot 提示只提供任务指令,没有示例。右侧的 few-shot 提示则为同一任务增补了示范性示例,展示了预期的输出格式和数据转换。
输出的质量和可重复性取决于以下几个因素:
-
范例数量:通常范例越多越好,甚至有研究表明使用上千个范例(多样本)能带来巨大性能提升。
-
范例顺序:LLM对提示中信息的顺序很敏感。将任务指令放在提示的开头,而不是末尾,可以利用模型的注意力偏向,提升其对任务的遵循度。
| 任务在提示末尾 | 新的任务位置 |
|---|---|
| 查看表1,它将包含以下内容: 特征:作者、年份、物种、Km 示例: 示例 #1:John 等,2000,猪,0.001 (m/s) 示例 #2:Gupta 等,2025,大鼠,1000 (um/s) 任务:从此表中提取特征,并遵循所提供的示例 | 任务:从此表中提取特征,并遵循所提供的示例 查看表1,它将包含以下内容: 特征:作者、年份、物种、Km 示例: 示例 #1:John 等,2000,猪,0.001 (m/s) 示例 #2:Gupta 等,2025,大鼠,1000 (um/s) |
图8. 结构化数据提取中提高任务依从性的提示重排序策略。
- 范例多样性:仅提供格式完美的范例会导致模型在处理现实世界中混乱、不完整的数据时失败。策略性地引入包含缺失字段、不同单位、数值范围和复杂句式等变化的范例,可以显著提高模型的鲁棒性。
| 相同的示例结构 | 方法各异,增加不确定性,单位多样 |
|---|---|
| 从这些方法部分提取化合物处理细节: 示例1:… 输出:… 示例2:… 输出:… | 从这些方法部分提取化合物处理细节: 示例1 (完整, 标准格式): … 输出:… 示例2 (缺失温度, 嵌入式格式): … 输出:… |
| 示例3:… 输出:… | 示例3 (细胞系在末尾, 浓度范围): … 输出:… |
图9. 示例多样性提高提取鲁棒性。 左侧:具有三个结构相同、参数完整的同质化提示。右侧:融入了缺失数据、嵌入信息、浓度范围和单位变化的现实主义变体的多样化方法。
- 领域特异性:令人惊讶的是,对于数据提取任务,提供领域内的范例并非必要。先进的LLM能够依赖结构模板,在不同科学领域间迁移提取模式。例如,一个为细胞生物学设计的提示,可以成功应用于材料科学和分析化学。

图10. 结构化提取提示的跨领域迁移能力。 尽管没有领域相关的示例,模型仍能正确地跨领域映射结构类别,提取温度范围、时间点和测量方法。
建议:
- 当使用大型模型(如GPT-4)时,要特别注意范例的质量,因为模型会忠实地学习范例中的模式,包括错误。
- 对于小型模型,它们更难被范例影响,因为它们严重依赖预训练知识。
- 在提取信息时,重点是提供清晰、格式一致且包含足够多样性的范例。
思维生成
当前最强大的模型能够进行“推理”,即通过一系列中间步骤来解决复杂问题。这种技术被称为思维链(Chain-of-thought, CoT),最简单的调用方式是加上“一步一步思考”(Think step by step)的指令。CoT已被证明能显著提高LLM在数学、编码等任务上的准确性。如下图所示,在处理一个微流体问题时,未使用CoT的非推理模型会混淆物理参数并产生数量级错误,而加入“一步一步思考”的指令后则能产生正确的序贯推理。

图11. 思维链提示在特定条件下可能是有益的。 左图:一个典型的零样本提示通常在逻辑或数学问题上会遇到困难。右图:添加“一步一步思考”指令会产生正确的序贯推理。
关于推理
像ChatGPT-5、Opus 4.1等“推理模型”能够原生进行多轮“思考”。它们会分配一部分上下文窗口用于思考。原则上,思考时间越长,任务完成得越好,但同时也会增加token消耗和幻觉风险。实践发现,强制模型“努力思考”(think hard)比让它自己决定思考时长,结果更具一致性。
然而,将CoT提示与推理模型结合可能会降低性能。最新研究表明,在某些认知心理学任务中,这样做甚至会使准确率下降。因此,CoT的性能取决于具体用例,它在数学推理等场景中表现优越,但在其他场景中可能适得其反。
关于多轮对话
在科学数据挖掘等任务中,多轮对话会严重损害提取的准确性。随着对话轮次增加,模型会逐渐丢失关键信息,最终产生不完整或错误映射的数据。研究表明,所有SOTA模型在多轮对话中都表现出严重的性能下降。一个设计良好、信息明确的单轮提示的性能远高于将同样信息分解到多轮、不明确的提示中。
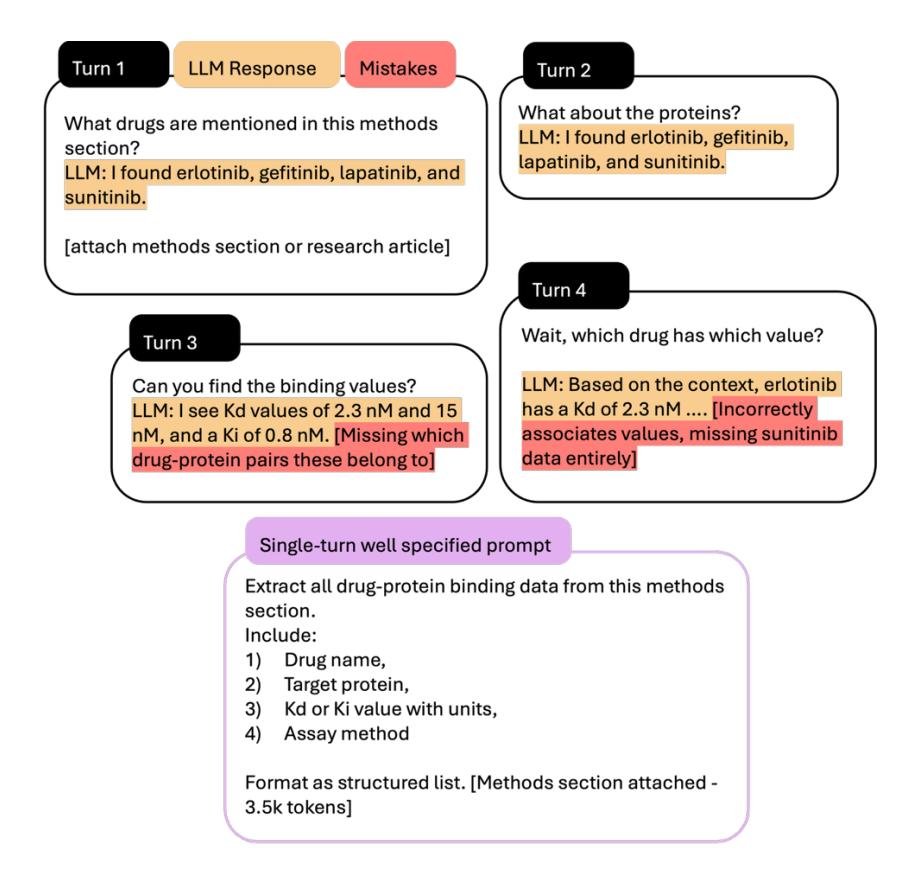
图12. 多轮对话与明确单轮提示在科学数据挖掘中的退化比较。 顶部:四轮对话显示数据完整性逐渐丧失。底部:具有明确指令的单轮提示。
建议:
- 如果一个提示初次失败,可以在新对话中重试一次,因为LLM的输出具有概率性。
- 如果模型在多轮对话中表现不佳,可以要求它“将我给你的所有提示整合成一个单一的、不推断意图的提示”,以此构建一个强大的单轮提示。
- 保持话题单一。不要在一个提示中叠加多个推理步骤,例如同时要求提取数据、进行计算和格式化引用。