The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
-
ArXiv URL: http://arxiv.org/abs/2306.01116v1
-
作者: Julien Launay; Hamza Alobeidli; B. Pannier; Alessandro Cappelli; Daniel Hesslow; Guilherme Penedo; Ebtesam Almazrouei; Quentin Malartic; Ruxandra-Aimée Cojocaru
-
发布机构: LightOn; Technology Innovation Institute; École normale supérieure
TL;DR
本文提出了一种仅使用网页数据,通过大规模精细过滤和严格去重,就能训练出顶尖大语言模型(LLM)的方法,并发布了由此产生的5万亿token数据集RefinedWeb,挑战了LLM预训练必须混合“高质量”精选语料库的传统认知。
关键定义
本文提出或使用的核心概念包括:
- RefinedWeb: 本文构建并发布的大规模、高质量、仅包含网页内容的英语预训练数据集。完整版含有5万亿token,其中6000亿token已公开。其核心特点是完全来源于CommonCrawl,但经过了极其严格的过滤和去重处理。
- MDR (MacroData Refinement): 本文设计的用于处理海量(万亿token级别)网页数据的数据处理流水线。该流水线遵循“规模优先、严格去重、中性过滤”的设计原则,整合了文档准备、多阶段过滤和多策略去重等一系列步骤,旨在将原始的CommonCrawl数据提炼成高质量的训练语料。
相关工作
当前,顶尖的大语言模型(LLMs)通常在一个混合数据集上进行预训练,这个混合数据集包含大规模的网页爬取数据(如C4、OSCAR)和所谓的“高质量”精选语料库(如The Pile,包含书籍、技术论文、社交媒体对话等)。普遍的观点认为,这种数据混合对于模型获得强大的零样本(Zero-shot)泛化能力至关重要。
然而,随着模型规模的增长,遵循新的缩放定律(Scaling Laws),所需的数据量也飙升至数万亿token的级别。这带来了两个关键问题:
- 可扩展性瓶颈:人工策划和整理高质量语料库的过程劳动密集,难以扩展到万亿token的规模,可能很快会面临高质量数据枯竭的问题。
- 网页数据质量:尽管网页数据量巨大,但其原始质量被认为远低于精选语料,直接使用效果不佳。
本文旨在解决的核心问题是:能否仅通过改进对海量网页数据的处理方式,来获得一个质量足够高、规模足够大的数据集,从而训练出性能与使用精选语料库训练的模型相媲美甚至超越的LLM?
本文方法
本文提出了一个名为MDR (MacroData Refinement)的数据处理流水线,用以从CommonCrawl网页数据中生成高质量的RefinedWeb数据集。MDR流水线的设计原则是规模优先 (Scale first)、严格去重 (Strict deduplication) 和 中性过滤 (Neutral filtering),避免使用除语言识别外的机器学习模型进行过滤,以减少引入额外偏见。
MDR流水线包含以下三个主要阶段,如下图所示,原始CommonCrawl数据在经过MDR处理后,近90%的文档被移除:
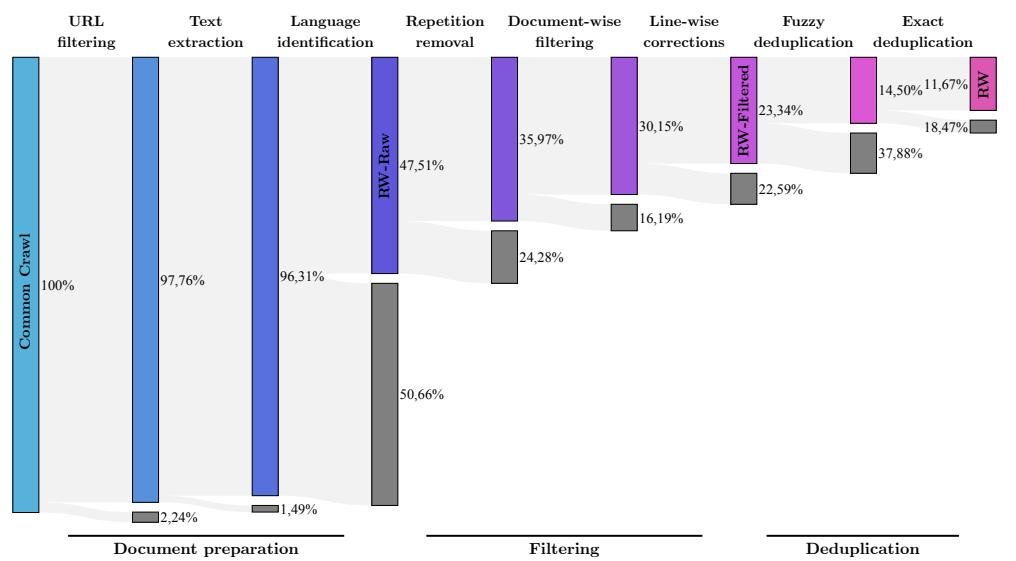
图注:MDR流水线的连续阶段移除了近90%的CommonCrawl原始文档。其中,过滤和去重步骤各自将数据量减半。
MDR流水线的详细步骤概括在下表中:
| 阶段 | 步骤 | 详情 |
|---|---|---|
| 文档准备 | URL过滤 | 聚合了460万个域名的黑名单、基于关键词的URL评分系统,并屏蔽了维基百科等常见高质量来源以备将来混合使用。 |
| 文本提取 | 使用\(trafilatura\)库从原始HTML中提取主要内容,去除导航、广告等无关文本。 | |
| 语言识别 | 使用\(fastText\)分类器识别文档语言,本文仅保留英语文档。 | |
| 过滤 | 文档级过滤 | 移除文档内部的重复内容(行、段落、n-gram),并根据长度、符号/词语比例等启发式规则过滤掉低质量或机器生成的垃圾文本。 |
| 行级修正 | 移除文档中残留的无用行(如“点赞数”、“导航按钮”),若修正内容超过文档的5%,则丢弃整个文档。 | |
| 去重 | 模糊去重 | 使用\(MinHash\)算法识别并移除内容高度相似的文档(如许可证模板、SEO填充文本)。 |
| 精确去重 | 使用后缀数组 (Suffix Array) 移除数据集中所有长度超过50个token的完全相同的子字符串。 | |
| URL去重 | 移除在不同CommonCrawl转储批次中被重复爬取的相同URL。 |
- 创新点
- 大规模和纯粹性:MDR是为处理数万亿token级的网页数据而设计的,最终产出的RefinedWeb数据集规模空前(5万亿token),且完全来源于网页数据,证明了单一来源数据的潜力。
- 严格的多级去重策略:与以往工作相比,本文采用了更为严格和全面的去重方法。它结合了文档级别的模糊去重(MinHash)和序列级别的精确子字符串去重,去重率远高于之前的数据集(如The Pile的10% vs. RefinedWeb的~50%),这被证明对提升模型质量和减少记忆至关重要。
- 精细的过滤流程:除了常规的文档级过滤,本文还引入了行级修正,进一步清理文本中夹杂的噪声,提升了语料的纯净度。
实验结论
本文通过一系列实验,验证了仅使用RefinedWeb数据集训练的模型的性能。
- 核心发现:网页数据足以超越精选语料
- 在小规模研究中(1B、3B参数模型),使用RefinedWeb训练的模型在零样本任务上的表现优于使用C4、OSCAR等其他网页数据集,也显著优于使用流行精选语料库The Pile训练的模型。这表明RefinedWeb的过滤和去重步骤对性能提升起到了关键作用。
- 在与SOTA模型的对比中,使用RefinedWeb训练的Falcon模型(1.3B和7.5B参数)的零样本性能匹配甚至超越了在私有精选数据集上训练的GPT-3系列模型,并显著优于所有在The Pile上训练的公开模型。这一结果有力地挑战了“高质量数据必须来自精选语料”的传统观念。
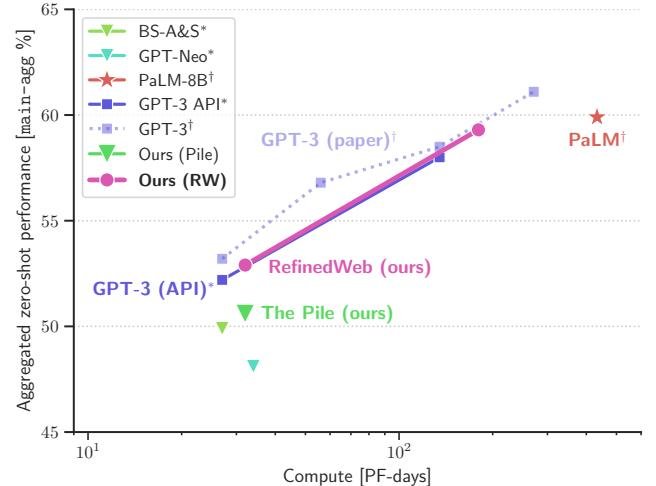
图注:在main-agg任务集上,相同计算预算下,使用RefinedWeb训练的模型(作者方模型)显著优于使用The Pile训练的公开模型(▼),并达到了与GPT-3(■)相当的性能水平。
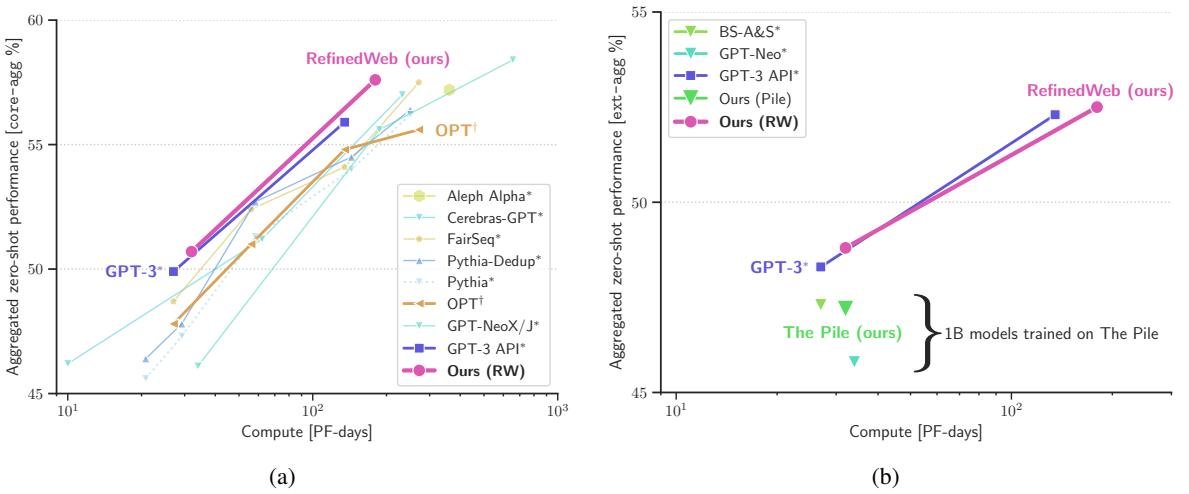
图注:在core-agg(左)和ext-agg(右)任务集上,RefinedWeb训练的模型同样表现出色,超越了其他基于The Pile的公开模型,并与GPT-3性能相当。
- MDR流水线的泛化能力
- 将MDR的过滤和去重步骤分别应用于C4、The Pile等现有数据集,实验发现严格去重能够持续且显著地提升所有数据集上的模型零样本性能。而去重所移除的数据比例与性能提升幅度有较强关联。
- 过滤步骤虽然有效,但其启发式规则可能需要针对不同类型的数据进行调整,才能达到最佳效果。
- 最终结论
- 本文证明了,通过足够严格和精细的过滤与去重流程,仅从网页数据中就可以提炼出比传统精选语料库更高质量的预训练数据。
- 这为解决未来更大规模LLM(如需数万亿token)的训练数据瓶颈问题提供了一条可行且可扩展的路径,降低了对劳动密集型人工策划的依赖。
- 本文发布的6000亿token的RefinedWeb数据集和基于其训练的Falcon模型,为社区提供了一个新的高质量基准。