Think Right: Learning to Mitigate Under-Over Thinking via Adaptive, Attentive Compression
-
ArXiv URL: http://arxiv.org/abs/2510.01581v1
-
作者: Akshay Nambi; Archiki Prasad; Elias Stengel-Eskin; Mohit Bansal; Justin Chih-Yao Chen; Joykirat Singh
-
发布机构: Microsoft Research; The University of Texas at Austin; University of North Carolina at Chapel Hill
TL;DR
本文提出了一种名为 TRAC 的在线强化学习后训练方法,利用模型自身的自注意力机制来识别并压缩冗余的推理步骤,并根据动态评估的任务难度自适应地调整压缩程度,从而有效缓解大模型在简单任务上“过度思考”和在困难任务上“思考不足”的问题。
关键定义
- 思考不足-过度问题 (Under-overthinking problem):指模型在面对不同难度的任务时,无法恰当地分配计算资源(即推理长度)的现象。具体表现为在困难问题上因推理过早终止而犯错(思考不足),以及在简单问题上即使已得出正确答案仍继续生成不必要的步骤,导致计算浪费(过度思考)。
- 适应性不足 (Under-adaptivity):导致“思考不足-过度问题”的根本原因,指模型缺乏根据问题难度动态调整其响应长度的能力。
- TRAC (Think Right with Adaptive, aTtentive Compression):本文提出的核心方法,是一种基于强化学习的在线后训练方法。其关键在于“自适应”(Adaptive)地根据任务难度调整策略,以及利用“注意力”(Attentive)分数来指导推理过程的“压缩”(Compression)。
- 基于注意力的压缩 (Attention-based Compression):TRAC的核心机制。通过计算模型内部从特殊结束符(如 \(</think>\))到各个推理步骤的注意力分数,来评估每个步骤的重要性,并据此修剪掉得分较低的冗余步骤。
相关工作
当前先进的“思考”模型通过在线强化学习(RL)等方法,能够在推理时扩展计算量(如增加token数量)来解决数学、编程等领域的复杂问题。然而,这些模型的性能和实用性受限于一个关键瓶颈:它们无法根据任务难度有效调节推理的长度。
这导致了普遍存在的“适应性不足”问题,即模型在困难问题上因推理步骤不足而导致“思考不足”,准确率下降;而在简单问题上则会进行过多不必要的推理,造成“过度思考”,浪费了大量的计算资源和token。
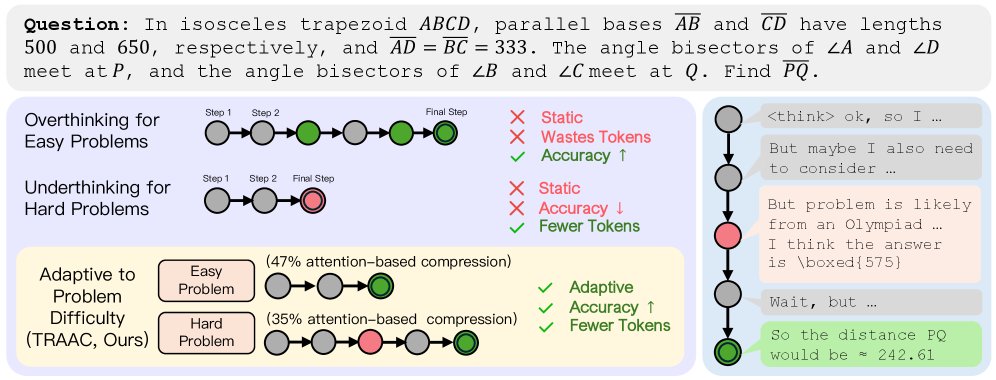
在简单问题上过度思考会浪费token,在困难问题上思考不足则会牺牲准确率。TRAC通过基于注意力的压缩来自适应问题难度,在提升准确率的同时实现了智能的资源分配。
以往工作主要关注解决“过度思考”以提升效率,例如通过监督微调压缩的思维链、在推理时提前停止,或使用带长度惩罚的RL方法。这些方法通常以牺牲模型性能为代价来换取效率。
本文旨在解决上述“思考不足-过度问题”,打破准确率与效率之间的权衡,使模型能够根据问题难度自适应地分配推理预算,从而在困难任务上提升准确率,在简单任务上提高效率。
本文方法
本文提出了 TRAC (Think Right with Adaptive, aTtentive Compression) 方法,旨在缓解模型的适应性不足问题。其核心挑战在于如何高效识别重要性低的token,并使压缩过程能够自适应于任务难度。TRAC通过一个基于注意力的压缩模块来实现这一目标,该模块根据评估出的任务难度来校准压缩程度,从而在保留核心信息的同时修剪不必要的推理步骤。
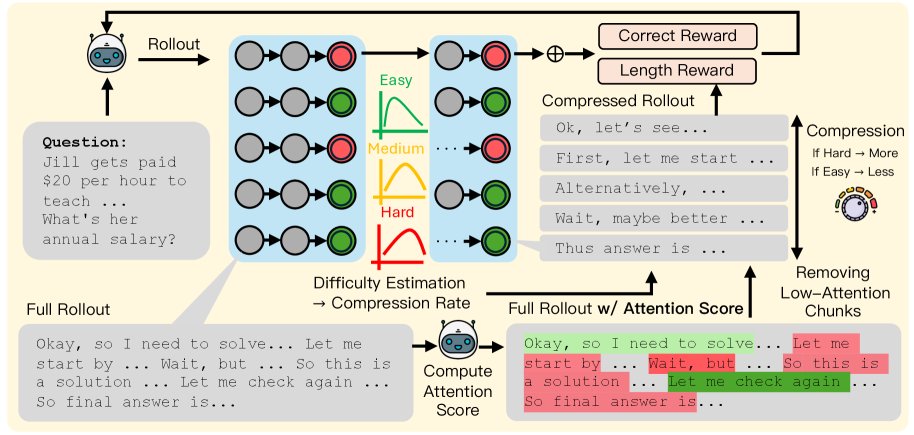
TRAC流程:首先,模型生成N个rollouts,并根据其通过率估计问题难度。接着,将推理过程反馈给模型,计算每个推理token的注意力分数。在注意力压缩步骤中,移除分数较低的步骤,移除程度由问题难度决定(越简单的问题压缩越狠)。最后,使用压缩后的推理轨迹计算正确性和长度奖励,并用这些奖励更新策略。
问题定义
TRAC 基于 GRPO (Group Reward Policy Optimization) 框架,这是一种在线强化学习算法。给定输入问题 $q$,策略模型 $\pi_{\theta}$ 生成一个输出 $y$,包含推理轨迹 $r$ 和最终答案 $a$。一个注意力压缩模块 $\mathcal{C}$ 将原始轨迹 $r$ 压缩为 $r_{\text{comp}}=\mathcal{C}(r)$。在训练中,模型生成 $N$ 个rollouts ${y^{i}}_{i=1}^{N}$,并根据这些rollouts的正确率来估计任务难度。任务难度随后被用于两个方面:(i) 调节应用于推理轨迹 $r$ 的压缩率;(ii) 为每个rollout分配奖励。
自适应注意力压缩模块
该模块的目标是通过评估每个token的注意力分数来识别并移除冗余的推理步骤。
创新点1:基于自注意力的重要性评估 为了计算每个token的注意力分数,本文将推理轨迹 $r$ 输入到初始策略模型中。与依赖外部模型的方法不同,TRAC完全利用模型自身的能力。推理轨迹 $r$ 被特殊控制token(如 \(</think>\))分割成多个推理步骤。基于先前研究发现模型在总结时会关注关键步骤,本文定义了每个token $t_j$ 的重要性分数 $s_j$,即从结束符 \(</think>\) 到该token在所有层和注意力头上的聚合注意力权重:
\[s_{j}=\frac{1}{LH}\sum_{\ell=1}^{L}\sum_{h=1}^{H}\alpha_{\texttt{</think>}\to t_{j}}^{(\ell,h)}\]其中 $L$ 和 $H$ 分别是模型的层数和头数。一个推理步骤的重要性是其包含的所有token重要性分数的平均值。分数较低的步骤被剪枝,从而得到压缩后的推理轨迹 $r_{\text{comp}}$。
创新点2:难度级别校准 (Difficulty-Level Calibration) 为了解决适应性不足问题,剪枝策略会根据任务难度进行调整。具体来说,任务难度是根据rollout期间的通过率来估计的,并分为“简单”、“中等”和“困难”三级。
- 对于简单任务,应用更高的压缩率,鼓励模型更积极地精简其推理过程。
- 对于困难任务,则应用较低的压缩率,允许模型进行更长的推理以探索解决方案。 这种机制使模型能够智能地分配思考资源。
奖励机制
TRAC使用包含三个部分的奖励信号来指导模型生成长度自适应且正确的响应:
- 正确性奖励:给予正确答案非常高的权重,确保模型始终以正确性为首要优化目标。
- 结构奖励:确保生成内容包含如 \(</think>\) 和 \(</answer>\) 等分隔符,保证输出格式的规范性。
- 长度奖励:该奖励同样与任务难度挂钩,旨在惩罚不必要的长推理。为了避免因略微超长而导致奖励急剧下降,本文引入了一个基于Sigmoid函数的平滑奖励机制。对于每个难度级别(简单、中等、困难),模型会维护一个独立的推理长度分布 $\mathcal{L}_{\texttt{d}}$。长度奖励不仅会归一化,还会加上一个平滑奖励项 $\beta$:
其中 $\ell$ 是当前rollout的长度。这个设计防止了训练中的剧烈波动,并鼓励模型根据难度生成适宜长度的推理。只有在答案正确时,才会提供长度奖励。
实验结论
本文在 Qwen3-4B 和 Deepseek-Qwen-7B 两个模型上进行了实验,训练数据为数学推理数据集 DAPO-Math-17k,并在多个数学及非数学(域外)基准上进行评估。
主要结果
TRAC同时提升性能与效率 如下表所示,与基线模型相比,TRAC在显著降低推理长度的同时,也带来了准确率的提升。
- 在Qwen3-4B上,TRAC在AIME, AMC, GPQA-D, BBEH四个基准上平均使绝对准确率提升了8.4%,同时相对减少了36.8%的推理长度。
- 与表现次优的自适应基线 AdaptThink 相比,TRAC 的准确率高出 7.9%,长度减少了 29.4%。
- 这表明TRAC成功打破了效率和性能的权衡,不像其他方法那样为了效率而牺牲准确率。
表1: TRAC与各基线方法的性能对比 Acc. 表示准确率(%),Len. 表示平均响应长度(k)
| 模型/方法 (Qwen3-4B) | AIME | GPQA-D | BBEH | AMC | 平均 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc.↑ | Len.↓ | Acc.↑ | Len.↓ | Acc.↑ | Len.↓ | Acc.↑ | Len.↓ | Acc.↑ | Len.↓ | |
| Base Model | 27.64 | 9.2 | 45.18 | 7.6 | 18.28 | 6.7 | 68.19 | 7.0 | 39.8 | 7.6 |
| TokenSkip | 5.84 | 9.6 | 32.32 | 7.8 | 11.91 | 7.2 | 27.71 | 8.7 | 19.4 | 8.3 |
| L1-Max | 30.11 | 7.1 | 43.23 | 5.8 | 14.91 | 5.0 | 63.61 | 5.8 | 38.0 | 5.9 |
| LC-R1 | 13.48 | 2.6 | 26.67 | 1.5 | 12.35 | 1.9 | 56.38 | 1.7 | 27.2 | 1.9 |
| Adapt Think | 36.63 | 8.4 | 44.04 | 6.7 | 7.87 | 6.2 | 72.77 | 5.8 | 40.3 | 6.8 |
| TRAC (本文) | 45.21 | 6.7 | 49.46 | 4.2 | 25.00 | 4.3 | 73.61 | 4.2 | 48.2 | 4.8 |
| 模型/方法 (Deepseek-Qwen-7B) | ||||||||||
| Base Model | 33.71 | 8.2 | 43.55 | 7.1 | 10.61 | 5.9 | 74.22 | 5.7 | 40.5 | 6.7 |
| TokenSkip | 24.94 | 8.5 | 34.24 | 7.0 | 6.30 | 6.4 | 52.05 | 6.8 | 29.4 | 7.2 |
| L1-Max | 31.01 | 3.1 | 23.54 | 1.9 | 12.91 | 2.1 | 75.90 | 2.2 | 36.0 | 2.3 |
| LC-R1 | 6.07 | 4.0 | 28.78 | 2.5 | 9.09 | 1.7 | 37.35 | 3.5 | 20.3 | 2.9 |
| Adapt Think | 34.87 | 7.1 | 19.29 | 4.8 | 6.17 | 5.2 | 75.66 | 4.1 | 35.0 | 5.3 |
| TRAC (本文) | 38.60 | 7.3 | 47.67 | 6.2 | 11.55 | 5.2 | 77.83 | 4.5 | 43.8 | 5.8 |
TRAC 表现出强大的泛化能力 尽管TRAC仅在数学数据集上训练,但它在多个非数学的域外(OOD)任务上同样展现了性能提升和效率增益。
- 在GPQA-D, BBEH, OverthinkingBench, 和 UnderthinkingBench 等OOD任务上,TRAC在Qwen3-4B上平均准确率提升了3%,长度减少了40%。
- 在专为衡量“思考不足-过度问题”而设计的 OptimalThinkingBench 上,TRAC 的综合F1分数远超基线模型和AdaptThink,表明它能更好地在简单问题上避免过度思考,在复杂问题上避免思考不足。
表2: TRAC在OptimalThinkingBench (OTB)上的性能表现
| 模型/方法 (Qwen3-4B) | OverthinkingBench | UnderthinkingBench | OTB | |||
|---|---|---|---|---|---|---|
| Acc.↑ | Len.↓ | AUC_OAA↑ | Acc.↑ | Len.↓ | F1↑ | |
| Base Model | 90.02 | 1.2 | 80.06 | 34.33 | 7.1 | 48.05 |
| Adapt Think | 68.83 | 8.2 | 63.44 | 18.80 | 6.0 | 29.01 |
| TRAC (本文) | 89.79 | 0.6 | 85.06 | 41.13 | 4.7 | 55.41 |
| 模型/方法 (Deepseek-Qwen-7B) | ||||||
| Base Model | 78.45 | 0.9 | 72.38 | 12.69 | 6.2 | 21.60 |
| Adapt Think | 73.41 | 0.4 | 70.72 | 13.13 | 4.6 | 22.14 |
| TRAC (本文) | 81.81 | 1.0 | 72.89 | 23.95 | 5.9 | 34.15 |
消融与分析
消融实验证明了TRAC中各个组件的必要性。如下表所示,逐步加入“正确性奖励(CR)”、“长度奖励(LR)”、“压缩模块”和“难度校准(TRAC)”后,模型性能稳步提升。
- 移除难度校准模块会导致Qwen3-4B在四个数据集上的平均性能下降3.4%,效率降低23.8%。
- 在OptimalThinkingBench上,同时移除难度校准和注意力压缩模块会导致F1分数大幅下降。
这些结果凸显了任务难度校准与注意力压缩相结合对于在不同任务上实现高性能和高效率至关重要。
表3: TRAC(Qwen3-4B)在四个数据集上的消融实验结果
| 方法 | AIME Acc.↑ | GPQA-D Acc.↑ | BBEH Acc.↑ | AMC Acc.↑ | 平均Acc.↑ | 平均Len.↓ |
|---|---|---|---|---|---|---|
| Base Model | 27.64 | 45.18 | 18.28 | 68.19 | 39.8 | 7.6 |
| + CR | 40.54 | 45.18 | 21.05 | 73.07 | 44.9 | 7.5 |
| + LR | 40.34 | 46.12 | 22.81 | 73.34 | 45.6 | 3.5 |
| + Compression | 43.13 | 49.32 | 22.81 | 73.19 | 47.1 | 6.3 |
| TRAC (本文) | 45.21 | 49.46 | 25.00 | 73.61 | 48.2 | 4.8 |
表4: TRAC(Qwen3-4B)在OptimalThinkingBench上的消融实验结果
| 方法 | OverthinkingBench | UnderthinkingBench | OTB | |||
|---|---|---|---|---|---|---|
| Acc.↑ | Len.↓ | AUC_OAA↑ | Acc.↑ | Len.↓ | F1↑ | |
| Base Model | 90.02 | 1.2 | 80.06 | 34.33 | 7.1 | 48.1 |
| + CR | 90.02 | 0.9 | 78.86 | 37.06 | 5.7 | 50.4 |
| + LR | 87.22 | 0.4 | 75.86 | 29.62 | 2.3 | 42.6 |
| + Compression | 90.12 | 0.9 | 80.41 | 36.51 | 6.0 | 50.2 |
| TRAC (本文) | 89.79 | 0.6 | 85.06 | 41.13 | 4.7 | 55.4 |
最终结论是,TRAC通过其新颖的自适应注意力压缩机制,成功地教会了模型根据任务难度动态调整其推理预算,从而在各种任务上有效缓解了“思考不足-过度问题”,并实现了准确率和效率的双重提升。