Thinking Augmented Pre-training
-
ArXiv URL: http://arxiv.org/abs/2509.20186v2
-
作者: Furu Wei; Li Dong; Shaohan Huang; Liang Wang; Nan Yang
-
发布机构: Microsoft Research
TL;DR
本文提出了一种名为“思维增强预训练”(Thinking Augmented Pre-training, TPT)的简单且可扩展的方法,通过使用现有LLM为预训练数据自动生成“思维轨迹”(thinking trajectories),从而显著提升了语言模型训练的数据效率和推理能力。
<img src=”/images/2509.20186v1/x2.jpg” alt=”一个思维增强数据样本的图示。红色的token “890”既正确又有价值,但直接学习起来很困难。” style=”width:85%; max-width:450px; margin:auto; display:block;”>
关键定义
本文主要提出了以下核心概念:
- 思维增强预训练 (Thinking Augmented Pre-training, TPT): 一种数据工程方法。其核心思想是,利用一个现成的(off-the-shelf)大语言模型为一个预训练数据集中的每个文档自动生成一段解释性的“思维轨迹”文本。然后,将原始文档与生成的思维轨迹拼接起来,形成一个增强的数据样本,用于训练目标LLM。
- 思维轨迹 (thinking trajectory): 针对一段给定的文本,由一个“教师”LLM生成的、模拟专家深入思考过程的文本内容。它通过分步推理和内容分解,将原始文本中一些难以直接通过下一个Token预测来学习的复杂信息(例如一个需要多步计算才能得出的数字)变得更加详细、可解释和易于学习。
相关工作
当前,大语言模型(LLM)的性能提升主要依赖于“规模法则”(scaling law),即不断增加模型参数和训练数据量。然而,高质量的人类原创数据资源已接近枯竭,这使得如何最大化地利用现有数据,即提升数据效率,成为研究的核心瓶颈。
现有数据工程方法主要关注数据清洗、过滤和去重等方面。一些研究尝试通过数据选择来优先训练“有价值”的Token,但面临一个关键问题:某些最有价值的Token,如复杂推理任务的最终答案,其背后涉及深度的、多步骤的思考过程,模型在有限的容量下很难通过简单的下一个Token预测来真正“学会”它,而不仅仅是死记硬背。
本文旨在解决这一具体问题:如何让模型更有效地学习这些高价值但难以直接掌握的知识,从而提升训练数据的利用效率和模型的最终性能,尤其是在推理能力方面。
本文方法
本文提出的TPT方法流程简单,可应用于任何文本数据和不同的训练阶段(如从零预训练、持续训练等)。
具体步骤如下:
- 数据增强: 给定一个来自预训练数据集的文档 $d$。
- 思维生成: 使用一个现成的LLM(教师模型)和一个指定的提示(prompt),为该文档 $d$ 生成一个思维轨迹 $t$。该轨迹旨在模拟专家分析该文档时的思考过程。
- 样本构建: 将原始文档 $d$ 和生成的思维轨迹 $t$ 沿序列维度拼接起来,形成一个新的、增强后的训练样本 $x=[d;t]$。
- 模型训练: 在这个增强的数据集上,使用标准的下一个Token预测损失函数来训练目标LLM。其目标函数为:
其中 $N$ 是增强样本 $x$ 的总Token数。
创新点
- 分解复杂性以提升可学习性: TPT的核心创新在于,它没有直接让模型去预测那些背后逻辑复杂的“答案”Token,而是通过思维轨迹将这些复杂信息的推理过程分解成一系列更小、更简单的步骤。这使得模型能够循序渐进地学习,从而真正理解知识,而不是机械记忆。
- 隐式的动态数据加权: TPT通过思维轨迹的长度,自然地为不同数据分配了不同的训练计算量。分析表明,数学、物理等推理密集型领域的文本,以及难度更高的内容,会自然生成更长的思维轨迹。这意味着模型会花费更多的计算资源在这些高价值的数据上,从而实现了一种无需手动设计规则的、隐式的动态数据上采样和加权。
优点
- 简单且可扩展: 该方法不依赖于复杂的技术,如在线强化学习(online rollouts),并且在文档级别操作,使其能够轻松地扩展到万亿级别的训练数据。
- 通用性强: TPT可以应用于任何文本数据,无论是从零开始的预训练,还是在现有模型基础上的持续训练(mid-training),都能带来显著效果。
- 提升数据质量: 对于充满噪声的网络爬取数据,TPT通过生成结构化、解释性的思维轨迹,能将其转化为一种对LLM更“友好”、更易于学习的格式,起到了改善数据质量的作用。
实验结论
本文通过在高达100B Token的多种训练配置下进行实验,全面验证了TPT方法的有效性。
从零预训练
数据充足情况
在此设置下,训练两个8B参数模型各100B Token,一个使用原始数据(vanilla),一个使用TPT增强数据。
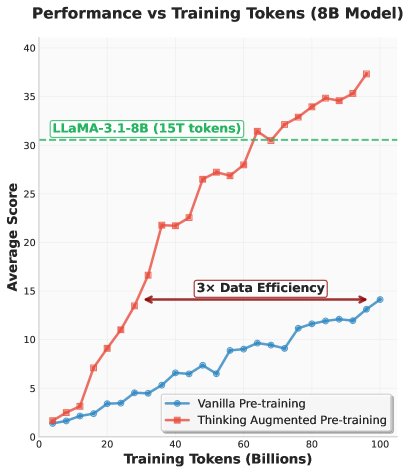
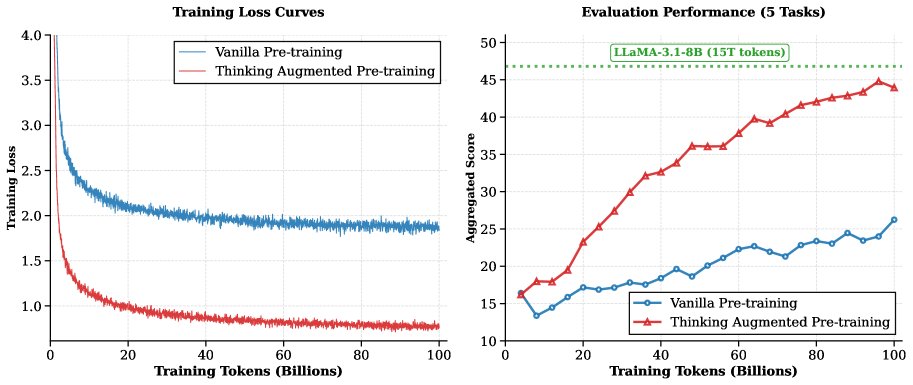
- 数据效率: 如图所示,TPT模型的训练损失显著低于基线模型,表明增强后的数据对模型更“可学习”。在下游任务上,TPT模型在训练了20B Token后开始超越基线,并且差距持续扩大。最终,TPT-8B模型(训练100B Token)的性能达到了与训练了15T Token的LLaMA-3.1-8B相当的水平,数据效率提升了约3倍。
- 性能提升: TPT在推理任务上提升尤为显著。与基线相比,TPT-8B在GSM8k上的准确率从19.2%提升至50.1%,在MATH上从9.1%提升至21.8%。
| 模型 | MMLU | MMLU_Pro | BoolQ | GSM8k | MATH | 平均分 |
|---|---|---|---|---|---|---|
| Vanilla-8B | 73.1 | 62.0 | 83.1 | 19.2 | 9.1 | 49.3 |
| TPT-8B | 74.1 | 65.1 | 83.8 | 50.1 | 21.8 | 59.0 |
| LLaMA-3.1-8B-Base | 74.4 | 69.8 | 85.3 | 55.4 | 24.2 | 61.8 |
经过监督微调(SFT)后,TPT模型在更难的推理基准(如AIME24)上表现出色,全面超越了基线模型和LLaMA-3.1-8B-Instruct,证明了TPT为模型奠定了更强的推理基础。
| 模型 | AIME24 | AIME25 | HMMT | LCB | GPQA-D | 平均分 |
|---|---|---|---|---|---|---|
| Vanilla-8B | 1.8 | 1.9 | 1.5 | 16.9 | 19.5 | 8.3 |
| TPT-8B | 15.1 | 13.5 | 10.5 | 23.5 | 24.1 | 17.3 |
| LLaMA-3.1-8B-Instruct | 15.0 | 12.0 | 8.2 | 22.0 | 22.1 | 15.9 |
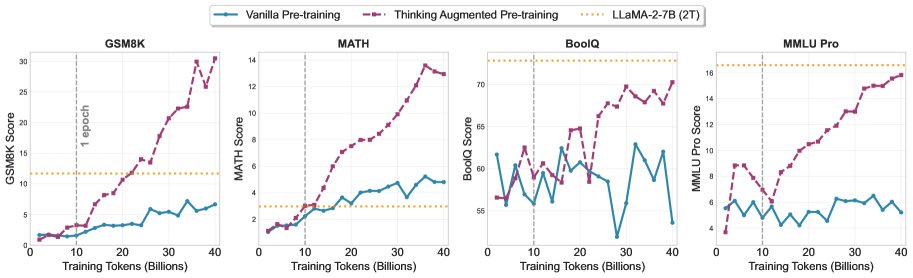
数据受限情况
模拟高质量数据耗尽的场景,将原始文档Token限制在10B,总训练预算为40B Token。
- 挖掘数据潜力: 如图所示,当普通训练因重复数据而性能趋于饱和时,TPT模型依然能持续提升性能,尤其是在数学推理任务上。这表明TPT能从同样的数据中挖掘出更多的价值。
思维增强持续训练 (Mid-training)
将TPT应用于Qwen2.5和LLaMA-3等系列的开源模型上进行持续训练。
- 普适性和可扩展性: TPT为所有尺寸(1.5B到7B)和模型家族都带来了显著的性能提升。
- 对推理能力弱的模型提升更明显: LLaMA-3系列模型在经过TPT持续训练后,性能提升幅度远超Qwen2.5系列。例如,3B的LLaMA模型在AIME24上的准确率从5.8%跃升至18.6%(增长3倍)。这可能是因为LLaMA系列的原始预训练数据中推理密集型内容较少,TPT有效弥补了这一短板。
| 模型系列 | 模型 | MMLU_Pro | MATH-500 | GSM8k | LCB v4_v5 | AIME24 | AIME25 | HMMT | GPQA-D | JEEBench |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen | OpenR1-1.5B* | 44.8 | 18.2 | 53.0 | 2.5 | 10.3 | 9.0 | 5.8 | 19.1 | 42.1 |
| TPT-1.5B | 52.3 | 18.8 | 57.1 | 3.8 | 11.4 | 10.3 | 6.7 | 20.1 | 42.4 | |
| DS-Distill-Qwen-7B† | 59.8 | 32.2 | 75.3 | 25.4 | 19.7 | 18.0 | 11.2 | 27.8 | 49.3 | |
| LLaMA-3 | OpenR1-3B* | 35.6 | 13.0 | 38.3 | 2.9 | 5.8 | 3.5 | 4.8 | 18.5 | 39.0 |
| TPT-3B | 52.2 | 23.6 | 60.9 | 14.2 | 18.6 | 15.4 | 11.4 | 25.6 | 44.9 | |
| OpenR1-7B* | 47.7 | 20.3 | 51.9 | 18.0 | 12.8 | 10.2 | 9.3 | 24.5 | 45.4 | |
| TPT-7B | 56.8 | 27.6 | 66.6 | 24.0 | 22.8 | 18.2 | 13.5 | 28.3 | 48.3 |
思维模式分析
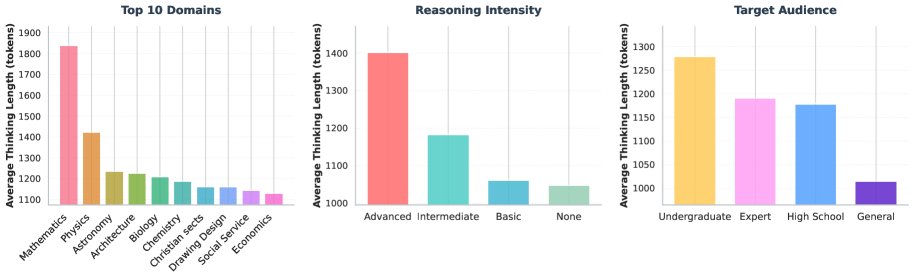
对生成的思维轨迹进行分析发现:
- 领域相关性: 数学和物理等需要深度推理的领域,生成的思维轨迹明显更长。
- 难度相关性: 原始文本的推理强度越高,思维轨迹也越长。
- 结论: 这些观察结果经验性地证明了TPT能够自动地为高价值、高难度的内容分配更多的训练资源,实现了隐式的数据加权。
消融研究与总结
- 思维生成策略: 探索了其他思维生成方法,如“反向思考”模型,发现尽管有微小提升,但默认方法的简单性和有效性综合更优。一个有趣的发现是,使用更小的1.5B模型生成思维轨迹,其效果反而优于7B模型,这表明生成轨迹的模型与被训练模型之间的关系值得进一步探究。
- 持续训练的重要性: 如果没有经过TPT持续训练,仅靠SFT很难让模型学会复杂的推理。经过TPT持续训练的模型在SFT阶段拥有更高的起点,并且在整个SFT过程中持续保持优势。
- 最终结论: TPT是一种简单、可扩展且高效的数据增强方法。实验证明,它通过为现有数据生成思维轨迹,能显著提高LLM训练的数据效率和最终性能,尤其是在数学、编码和通用推理等任务上,其效果在不同模型尺寸和训练设置下都得到了验证。