Thought Communication in Multiagent Collaboration
-
ArXiv URL: http://arxiv.org/abs/2510.20733v1
-
作者: Lizhu Zhang; Yaqi Xie; Yujia Zheng; Zhuokai Zhao; Mingze Gao; Zijian Li; Kun Zhang
-
发布机构: CMU; MBZUAI; Meta AI
TL;DR
本文提出了一种名为 THOUGHTCOMM 的多智能体协作新范式,它使智能体能通过理论上可识别的、直接的潜在“思想”进行交流,而非传统的自然语言,从而突破语言瓶颈,提升集体智能的协作效率和上限。
关键定义
本文的核心在于对智能体内部“思想”的建模与识别,关键定义如下:
- THOUGHTCOMM: 一种全新的多智能体通信范式,主张智能体之间应直接交换潜在思想 (Latent Thoughts),而非表层的自然语言(token或其嵌入)。这类似于心灵感应,旨在实现更直接、无损的信息传递。
- 潜在思想 (Latent Thoughts): 指驱动智能体推理和决策的、不可观测的潜在变量,记为 $Z_t$。本文假设智能体在通信前的模型状态 $H_t$ 是由这些潜在思想通过一个未知的生成函数 $f$ 产生的,即 $H_t = f(Z_t)$。
- 思想的结构 (Structure of Thoughts): 指潜在思想如何在不同智能体之间分布和共享。本文通过生成函数 $f$ 的雅可比矩阵 $J_f(Z_t)$ 的非零模式来形式化这个结构,它揭示了哪些思想影响了哪些智能体的状态。
- 共享思想与私有思想 (Shared and Private Thoughts): 基于思想的结构,影响多个智能体的思想被称为“共享思想”,而仅影响单个或少数智能体的思想则为“私有思想”。本文的理论证明了这两类思想均是可识别的。
相关工作
当前,基于大语言模型(LLM)的多智能体系统 (Multi-Agent Systems, MAS) 是研究的热点。这些系统通常依赖自然语言作为智能体间的通信媒介,通过交换 token 或其嵌入来协调行动。
然而,这种通信方式存在根本性瓶颈。自然语言本身具有模糊性、低效性和间接性,它只是对智能体内部复杂“思想”的一种有损压缩和不完整反映。这导致了诸如消息含义不明确、智能体间目标不一致等协作失败问题,极大地限制了集体智能的潜力,使其难以达到超越人类的协作水平。
因此,本文旨在解决的核心问题是:如何让智能体超越语言的限制,实现更直接、高效的交流,从而充分发挥多智能体协作的潜力?
本文方法
为了实现超越语言的交流,本文首先从理论上证明了从智能体状态中识别其潜在思想的可行性,然后基于该理论构建了一个名为 \(THOUGHTCOMM\) 的实用框架。
问题设定与思想生成过程
本文将智能体内部思想的产生过程形式化为一个潜在变量模型。假设在通信轮次 $t$,所有智能体的整体模型状态 $H_t$ 是由一组潜在思想 $Z_t$ 通过一个未知的、可逆的生成函数 $f$ 产生的:
\[Z_t \sim P_z, \quad H_t = f(Z_t)\]其中 $Z_t$ 是一个包含多个单一思想的向量,而 $H_t$ 拼接了所有智能体的模型状态 $H_t^{(j)}$。思想的“结构”——即哪个思想影响哪个智能体——由函数 $f$ 的雅可比矩阵 $J_f$ 的稀疏模式决定。
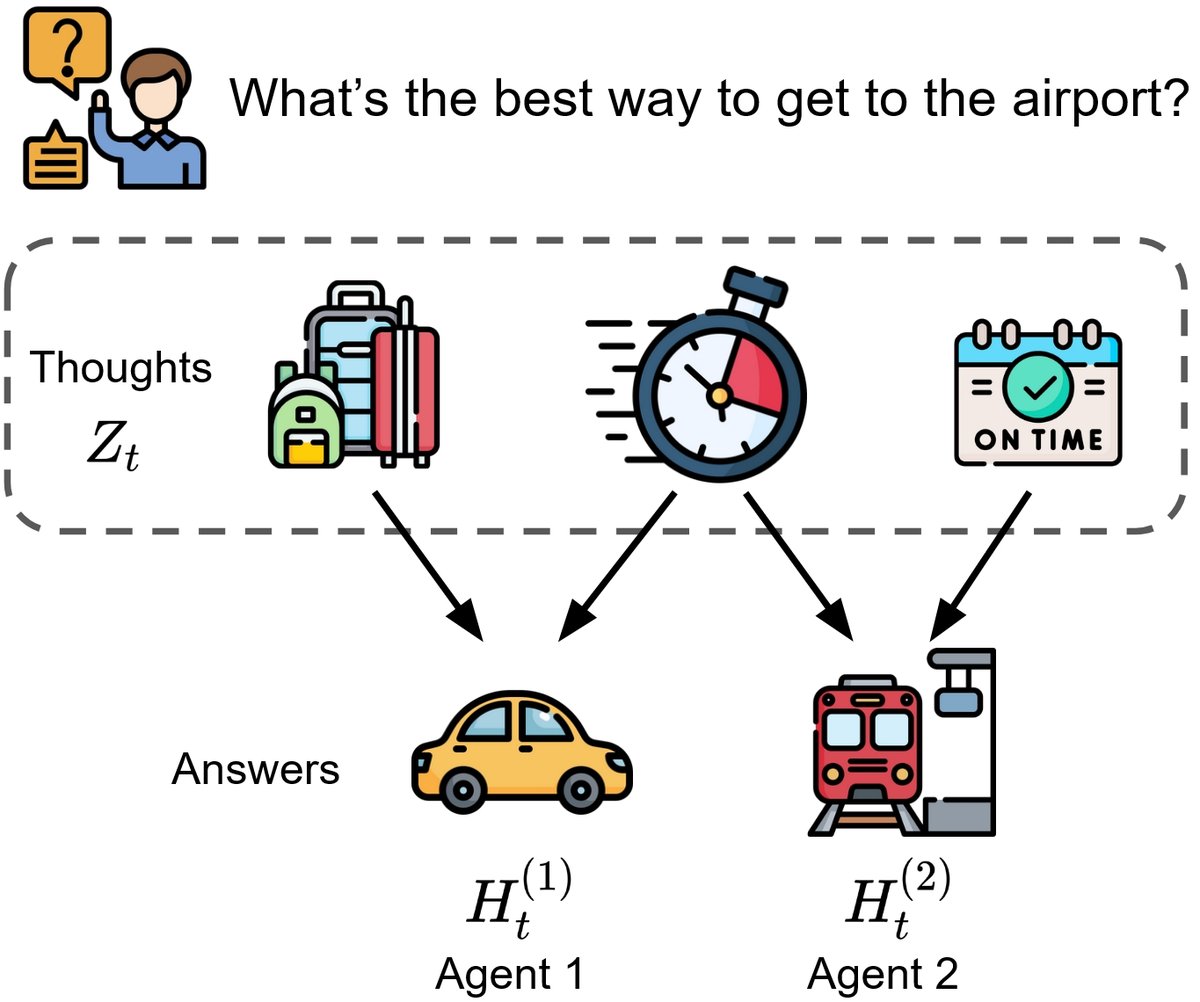
上图描绘了这个过程:针对一个问题,智能体们会激活一系列潜在思想(如“带行李”、“速度”、“准时”)。例如,智能体1受“带行李”和“准时”思想影响,倾向于选择“出租车”;而智能体2受“速度”和“准时”思想影响,选择“地铁”。“准时”就是一个共享思想,“带行李”和“速度”则是各自的私有思想。
可识别性理论:思想恢复的基石
在利用思想进行通信前,必须确保我们能准确地从观测到的智能体状态 $H_t$ 中恢复出真实的潜在思想 $Z_t$。本文提出了一套全新的可识别性理论,证明了在温和的假设下,潜在思想及其结构是可以被识别的。
核心理论贡献
本文的理论创新在于,它不像传统方法那样追求在强假设下完全恢复所有潜在变量,而是采取了一种更实用、鲁棒的策略:通过分析成对的智能体,旨在恢复对通信最有意义的部分信息,即共享思想和私有思想。
-
共享思想的可识别性 (定理 1): 证明了在任意一对智能体之间,它们共同拥有的“共享思想”可以被准确地识别出来,并且与其他所有潜在思想(包括私有思想)是解耦的。这为建立智能体间可靠的共识基础提供了理论保障。
-
私有思想的可识别性 (定理 2): 同样地,证明了任意智能体独有的“私有思想”也是可识别且解耦的。这确保了智能体独特的、有价值的见解(可能来自认知多样性)在通信中不会被忽略或混淆。
-
思想结构的可识别性 (定理 3): 证明了连接思想与智能体的整个依赖结构(即哪个智能体拥有哪些思想)也是可识别的。这意味着我们不仅知道“想了什么”,还能知道“谁在想”以及“谁和谁想的一样”,这对于理解智能体间的对齐与分歧至关重要。
THOUGHTCOMM 框架:思想通信的实践
基于上述理论,本文提出了 \(THOUGHTCOMM\) 框架,一个将思想通信付诸实践的具体流程。
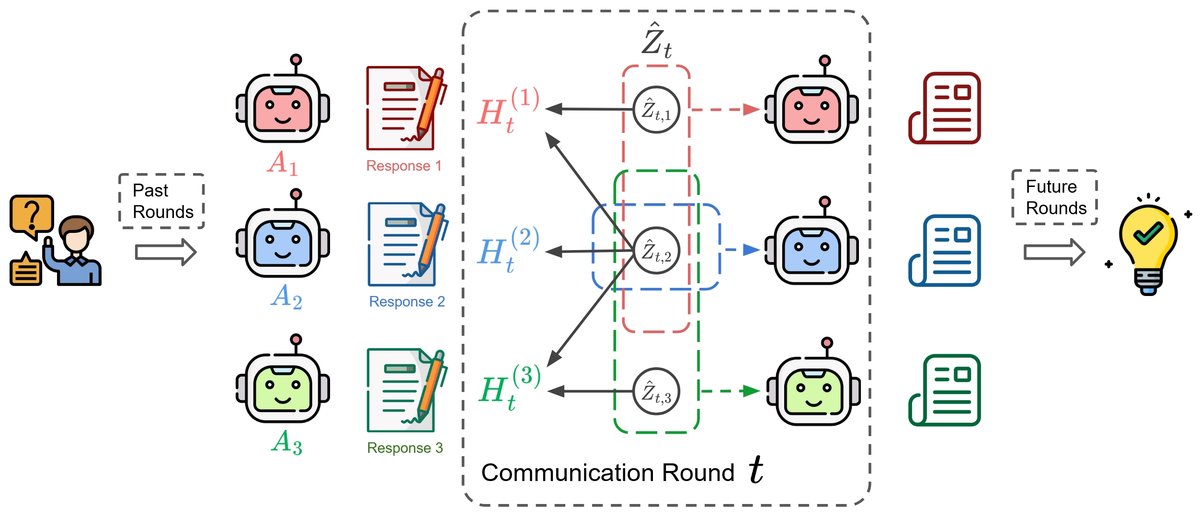
该框架的执行流程如上图所示,主要包括以下几个步骤:
-
揭示潜在思想: 使用一个带有稀疏性正则的自编码器 (Autoencoder) 来学习潜在思想的提取。所有智能体的模型状态 $H_t$ 被拼接并输入编码器 $\hat{f}^{-1}$,得到潜在思想的估计值 $\hat{Z}_t = \hat{f}^{-1}(H_t)$。训练目标是最小化重构误差和雅可比矩阵的L1范数,这种稀疏性约束是满足可识别性理论的关键。
\[\mathcal{L}_{\text{rec}}=\left\ \mid H_{t}-\hat{f}(\hat{Z}_{t})\right\ \mid _{2}^{2}+\left\ \mid J_{\hat{f}}\right\ \mid _{1}\] -
利用思想结构进行路由: 训练完成后,利用学到的雅可比矩阵的结构 $B(J_{\hat{f}})$ 来判断每个潜在思想维度与哪个智能体相关。然后,计算每个思想的“智能体一致性”得分 $\alpha_j$,即共享该思想的智能体数量。
-
个性化思想注入: 根据一致性得分,将与某个智能体相关的思想进行分组和加权,形成该智能体的个性化思想表示 $\tilde{Z}^{(i)}_t$。这样,共享程度高的思想和私有思想可以被区别对待。
-
通过前缀适配进行潜入式引导: 最后,通过一个可学习的适配器函数 $g$,将个性化思想表示 $\tilde{Z}^{(i)}_t$ 转换为一个向量前缀 (prefix) $P^{(i)}_t$。这个前缀被添加到智能体下一次生成任务的输入嵌入中,通过前缀适配 (Prefix Adaptation) 的方式,潜入式地引导智能体的行为,而无需进行明确的语言信息交换。
优点
该框架的设计具有模块化和任务无关的特点。自编码器和适配器可以一次预训练,然后广泛应用于不同任务,使得 \(THOUGHTCOMM\) 能够以最小的开销轻松集成到现有的多智能体系统中。
实验结论
本文通过合成数据实验严格验证了其可识别性理论的有效性。
合成数据评估
实验设置模拟了两个智能体、三个潜在思想(一个共享、两个私有)的场景。通过一个随机可逆变换生成观测数据,然后使用本文提出的稀疏正则自编码器进行思想恢复。
-
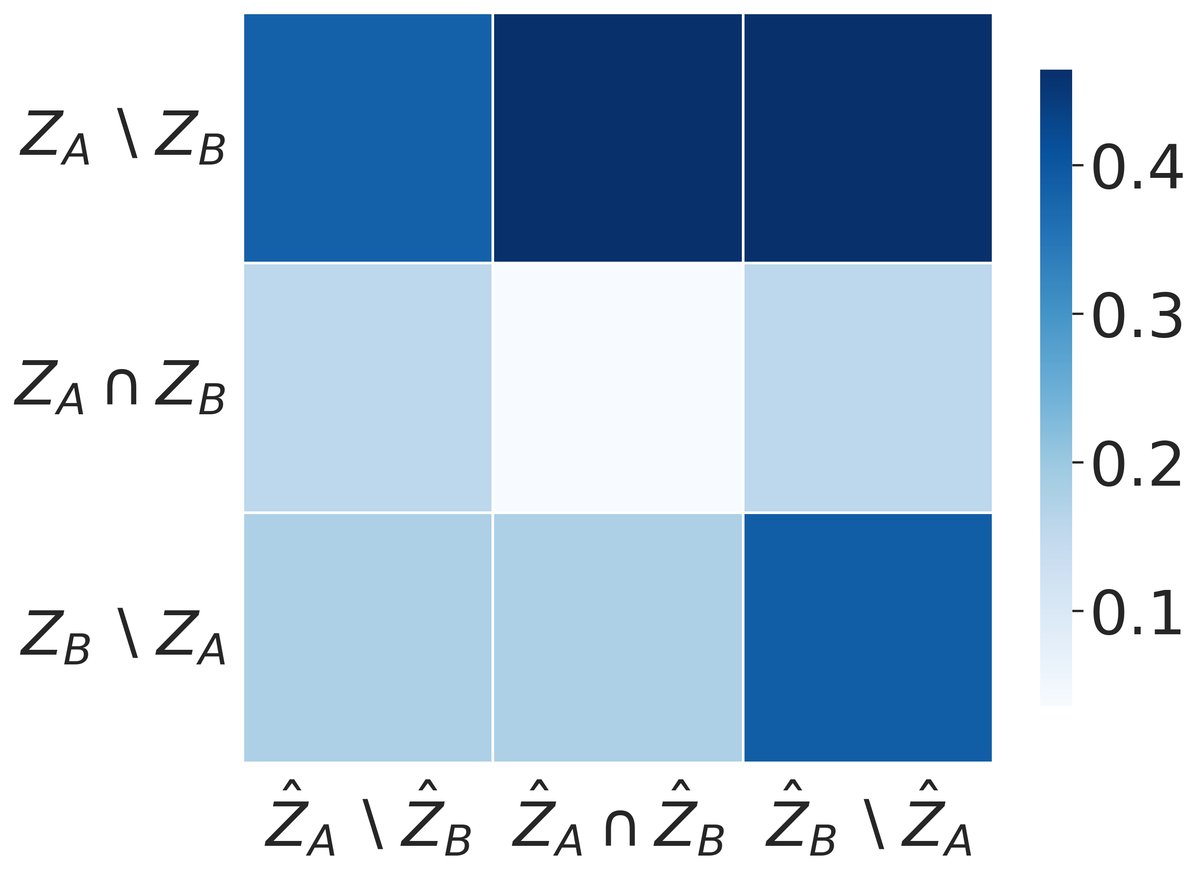
思想恢复的准确性: 恢复结果通过热力图展示,评估指标为 $R^2$ 分数。结果清晰地表明,带稀疏正则的模型(本文方法)能够准确地将恢复出的潜变量与真实的共享和私有成分对应起来(对角线上呈现高 $R^2$ 值),而没有稀疏正则的基线模型则完全失败,恢复出的潜变量是真实思想的混乱混合。这有力地证明了理论的正确性和稀疏正则化的必要性。
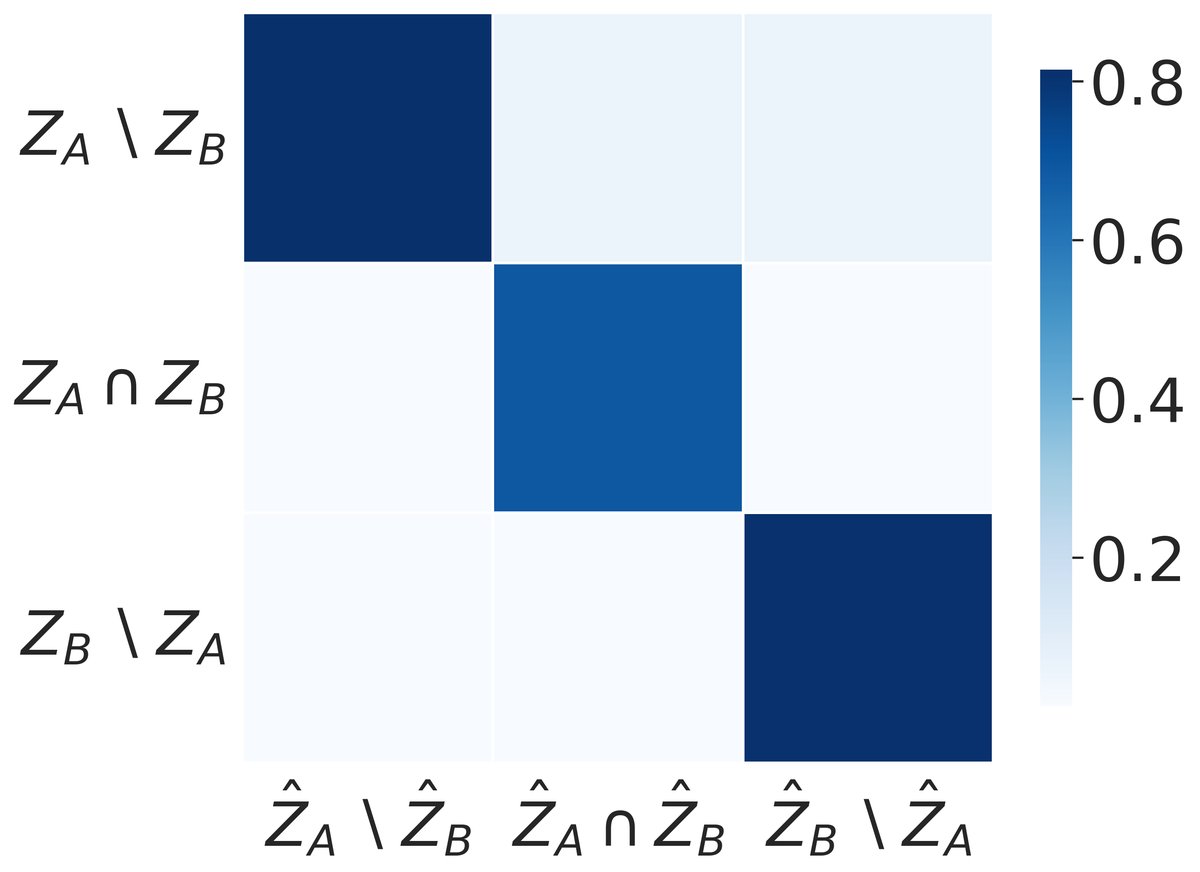
-
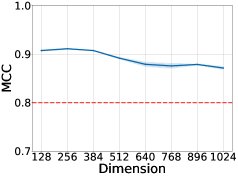
思想结构的恢复: 使用马修斯相关系数 (Matthews Correlation Coefficient, MCC) 来评估思想-智能体依赖结构的恢复效果。结果表明,本文方法在不同设置下均能取得很高的MCC分数,证实了其能够准确识别哪个智能体拥有哪个思想。
总结
综合来看,实验结果强有力地支持了本文的理论:\(THOUGHTCOMM\) 框架确实能够有效地从智能体的观测状态中解耦并识别出共享和私有的潜在思想及其分布结构。这为构建更高效、更智能的多智能体协作系统奠定了坚实的基础,展示了超越表层语言交流的巨大潜力。