Tongyi DeepResearch Technical Report
-
ArXiv URL: http://arxiv.org/abs/2510.24701v1
-
作者: Zhengwei Tao; Yong Jiang; Qian Xiao; Maojia Song; Hailong Yin; Pengjun Xie; Xixi Wu; Shaowei Chen; Litu Ou; Guangyu Li; 等52人
-
发布机构: Alibaba Group; Tongyi Lab
TL;DR
本文介绍了通义深搜(Tongyi DeepResearch),一个开源的AI研究智能体,它通过创新的“智能体中训练”与“智能体后训练”两阶段训练框架,结合可扩展的合成数据引擎,实现了领先的深度研究能力。
关键定义
- 深度研究 (Deep Research): 一种新的智能体能力,指智能体在面对复杂研究任务时,能够自主地在互联网上进行多步推理和信息搜寻。该过程通常在几十分钟内完成,而人类则需要数小时。
- 智能体中训练 (Agentic Mid-training): 在预训练和后训练之间新增的一个中间阶段。通过让模型接触大规模、高质量的智能体行为数据,为其注入固有的智能体行为偏好(inductive bias),为后续的后训练阶段建立一个强大的智能体能力起点。
- 智能体后训练 (Agentic Post-training): 在中训练之后,通过监督微调(SFT)进行冷启动,并利用强化学习(RL)进一步解锁模型的深层研究潜力。此阶段专注于通过与环境的真实交互来优化和探索更优的策略。
- 合成数据引擎 (Synthetic Data Engine): 一套旨在消除人工标注、可自动化生成多样化、高质量智能体轨迹数据的系统。该引擎为训练的每个阶段(中训练、后训练)量身定制数据合成策略,是驱动智能体能力扩展的核心。
- 三态环境模型 (Three-form Environments): 本文提出的将交互环境建模为三种形态的框架,以平衡训练的稳定性、保真度和成本。三种环境包括:提供无限扩展性但无真实反馈的先验世界环境 (Prior World Environment);提供稳定、快速、低成本交互的模拟环境 (Simulated Environment);以及提供最高保真度但成本高、不稳定的真实世界环境 (Real-world Environment)。
相关工作
当前,能够执行深度研究任务的智能体系统已经展现出巨大潜力,但多数系统(如OpenAI、Claude、Grok、Gemini等)仍是闭源的,其内部研究过程无法被外界访问和研究。尽管学术界已有一些初步的探索,但仍然缺乏一个系统性的方法论和可以被社区共享的、完全开源的高性能模型。
本文旨在解决这一问题,目标是构建一个开放的AI研究人员——通义深搜(Tongyi DeepResearch),赋予大语言模型(LLM)自主规划、搜索、推理和综合知识的能力,从而推动和加速整个社区在该领域的研究进展。
本文方法
方法概述
本文提出的通义深搜(Tongyi DeepResearch)基于Qwen3-30B-A3B-Base模型构建,其核心是一个统一了智能体中训练和后训练的端到端训练框架。该框架旨在通过精心设计的训练阶段、可扩展的合成数据引擎以及多形态的交互环境,系统性地培养LLM从基础交互到高级自主研究的复杂能力。
智能体行为范式
通义深搜的智能体行为主要基于两种范式:
ReAct 范式
智能体的基础架构采用了ReAct (Yao et al., 2023) 框架,该框架交错地生成思考(Thought)和行动(Action)。智能体根据历史交互记录 $\mathcal{H}_{t-1}$ 生成当前的思考 $\tau_t$ 和行动 $a_t$,形成一个由“思考-行动-观察”三元组构成的轨迹 $\mathcal{H}_T$。
\[\mathcal{H}_{T}=(\tau_{0},a_{0},o_{0},\dots,\tau_{i},a_{i},o_{i},\dots,\tau_{T},a_{T})\]在任意步骤 $t$,策略 $\pi$ 生成思考和行动的公式为:
\[\tau_{t},a_{t}\sim\pi(\cdot \mid \mathcal{H}_{t-1})\]本文选择ReAct是因其简洁性和可扩展性,符合“苦涩的教训 (The Bitter Lesson)”所倡导的原则,即通用方法最终会胜过依赖复杂人类工程知识的方法。
上下文管理范式
为了解决长程任务中上下文窗口有限的问题,本文采用了上下文管理范式 (Context Management paradigm)。该范式不依赖完整的历史记录,而是在每一步 $t$ 都基于一个动态重构的工作区来做出决策。这个工作区只包含关键信息:问题 $q$、一个不断演进的报告(作为压缩记忆)$S_t$,以及上一步的交互(行动 $a_t$ 和观察 $o_t$)。其核心更新过程可表示为:
\[S_{t},\tau_{t+1},a_{t+1}\sim\pi(\cdot \mid S_{t-1},a_{t},o_{t})\]这种机制不仅避免了上下文溢出,还迫使智能体在每一步都进行信息的综合与提炼,模拟了人类研究中周期性总结和反思的模式。
整体训练流程
通义深搜的训练流程从预训练好的Qwen3-30B-A3B-Base模型开始,依次经过智能体中训练和智能体后训练两个核心阶段。

智能体中训练 (Agentic Mid-training)
该阶段是连接预训练和智能体后训练的关键桥梁,目标是为模型注入强大的智能体行为归纳偏置,同时保持其通用语言能力。
训练配置
此阶段采用两阶段的持续预训练 (Continual Pre-training, CPT)。
- 第一阶段: 使用较短的上下文长度。
- 第二阶段: 将上下文长度扩展至128K,并引入大量长序列(64K-128K)的智能体行为数据,以增强模型的长程推理能力。 在两个阶段中,都会混合一小部分通用的预训练数据,以防止模型遗忘基础能力。
大规模智能体行为数据合成
为支持中训练,本文设计了一套覆盖智能体工作流全生命周期的数据合成方法。

- 问题合成 (Question Synthesis): 基于一个持续更新的、以实体为中心的开放世界知识库,采样实体及其相关知识,生成需要特定行为模式(如多跳推理、数值计算)的各类问题。
- 规划行动 (Planning Action): 使用开源模型对合成的问题进行分解和初始行动预测,并利用问题构建时使用的实体知识进行拒绝采样,确保规划质量。
- 推理行动 (Reasoning Action): 引导大模型针对问题和相关知识生成完整的推理链,并通过推理长度和答案一致性进行双重过滤。
- 决策行动 (Decision-Making Action): 将智能体轨迹中的每一步显式地建模为决策过程。通过探索每个决策点的可能行动空间,并将原始轨迹重构为多步决策序列,以训练模型的决策能力。
此外,为了提升模型的通用函数调用能力,本文还通过环境扩展 (environment scaling) 的方式,自动构建了大量异构的、完全模拟的函数调用环境,并生成相应数据用于中训练。
智能体后训练 (Agentic Post-training)
后训练流程包含三个阶段:高质量数据合成、用于冷启动的监督微调(SFT)和智能体强化学习(RL)。
高质量数据合成
本文开发了一个端到端的自动化数据引擎,用于生成复杂的、高不确定性的、达到超人水平的问答对,无需任何人工干预。
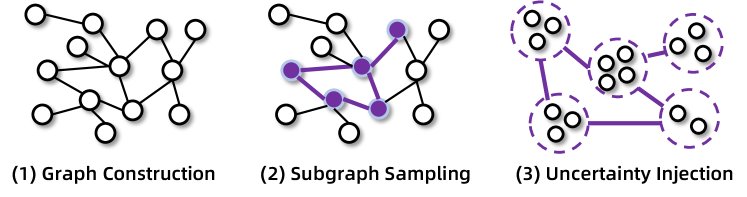
该流程首先通过随机游走构建高度互联的知识图谱,并从真实网站获取同构表格,以模拟真实的信息结构。然后,它采样生成初始问答对,并通过对实体关系进行一系列可控的“原子操作”(如合并相似属性的实体)来系统性地增加问题难度。此外,本文基于集合论对信息搜寻问题进行形式化建模,从而能以可控的方式扩展问题,减少推理捷径,并有效验证合成数据的正确性。
监督微调 (SFT)
SFT阶段旨在为强化学习提供一个鲁棒的初始策略。本文使用高性能开源模型为合成的高质量问题生成SFT训练轨迹,并通过严格的拒绝采样来筛选。训练采用了混合训练范式:
- ReAct模式数据: 训练模型在给定历史状态下,预测下一步的思考和工具调用。
- 上下文管理模式数据: 训练模型根据上一步的轨迹摘要、行动和观察,生成当前步骤的摘要、思考和行动。这种模式的数据能特别强化智能体的状态分析和战略决策能力。 训练也分为两个阶段,先用较短的上下文长度(40K)训练,再扩展到更长的上下文(128K)。
智能体强化学习 (RL)
为了让模型在复杂的网络环境中掌握更鲁棒的规划和搜索能力,本文应用了一个智能体RL框架。
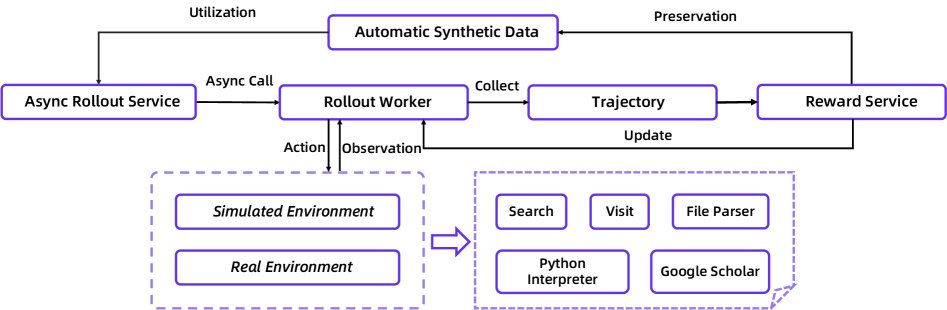
- 环境构建:
- 真实世界环境: 为了应对外部API的不稳定性(高延迟、失败、返回不一致),本文开发了一个统一的沙箱 (sandbox)。该沙箱通过中央调度、并发控制、缓存、超时重试、服务降级和备份数据源等机制,为智能体提供了一个确定性、稳定且高效的工具调用接口。
- 模拟环境: 为了降低成本和加速迭代,本文基于2024年的维基百科数据库构建了一个离线环境,并开发了一套本地RAG工具来模拟网络环境。
- 异步Rollout框架: 为了解决智能体交互耗时长、拖慢RL训练的问题,本文基于rLLM框架实现了一个步级别的异步RL训练循环。该架构使用独立的服务器分别处理模型推理和工具调用,允许多个智能体实例并行与环境交互。
- RL训练算法: 本文采用了GRPO算法的变体。当智能体完成一次任务尝试(rollout)后,如果最终答案与真实答案匹配,则会收到奖励。其损失函数定义如下:
其中,$\mathcal{J}_{\text{PPO}}$ 是标准的PPO损失,而 $\mathcal{J}_{\text{align}}$ 是一个对齐项,用于确保只有在最终答案正确时才对成功的轨迹进行正向梯度更新,这有助于稳定训练过程并提高样本效率。
实验结论
通义深搜在多个深度研究基准测试上取得了SOTA(State-of-the-Art)性能,其参数量仅为305亿(每个token激活33亿),但表现优于OpenAI-o3和Deepseek-V3.1等强大的基线模型。
具体性能表现如下:
| 基准测试 | Tongyi DeepResearch 性能 |
|---|---|
| Humanity’s Last Exam | 32.9 |
| BrowseComp | 43.4 |
| BrowseComp-ZH | 46.7 |
| WebWalkerQA | 72.2 |
| GAIA | 70.9 |
| xbench-DeepSearch | 75.0 |
| FRAMES | 90.6 |
| xbench-DeepSearch-2510 | 55.0 |
此外,在AIME25、HMMT25和SimpleQA等通用基准测试中也取得了优异表现。
这些实验结果充分验证了本文提出的“智能体中训练+后训练”框架以及合成数据引擎的有效性。最终结论是,本文提出的系统性方法论为构建可扩展、高性能的开源AI研究智能体提供了坚实的基础,并指明了智能体模型是未来发展的一个重要趋势。