ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
-
ArXiv URL: http://arxiv.org/abs/2307.16789v2
-
作者: Dahai Li; Yining Ye; Yankai Lin; Lan Yan; Shi Liang; Runchu Tian; Xiangru Tang; Sihan Zhao; Jie Zhou; Maosong Sun; 等8人
-
发布机构: ModelBest Inc.; Renmin University of China; Tencent Inc.; Tsinghua University; Yale University; Zhihu Inc.
TL;DR
本文提出了一个名为ToolLLM的通用工具使用框架,通过构建一个包含超过16000个真实世界API的大规模指令微调数据集ToolBench,并采用一种新颖的深度优先搜索决策树(DFSDT)方法,成功地将开源大语言模型(LLaMA)的工具使用能力提升至与ChatGPT相当的水平。
关键定义
- ToolLLM: 一套通用的工具使用框架,涵盖了为大型语言模型(LLMs)赋能工具使用能力所需的数据构建、模型训练和评估的全过程。
- ToolBench: 本文构建的一个大规模、高质量的工具使用指令微调数据集。它包含从RapidAPI平台收集的16,464个真实世界RESTful API,以及围绕这些API自动生成的超过12万条指令,覆盖了单工具和多工具使用的复杂场景。
- 深度优先搜索决策树 (Depth-First Search-based Decision Tree, DFSDT): 本文为增强LLM的规划和推理能力而开发的一种新颖算法。与传统的单路径推理方法不同,DFSDT允许模型构建一个决策树,探索多条可能的推理路径,并能够在遇到错误或死胡同时进行回溯,从而显著提高了解决复杂问题的成功率。
- ToolEval: 本文开发的一款基于ChatGPT的自动化评估器,用于衡量LLM的工具使用能力。它包含两个关键指标:通过率 (Pass Rate),衡量模型成功完成指令的能力;以及胜率 (Win Rate),通过对比两个模型生成的解决方案来评估其质量。
- ToolLLaMA: 基于ToolBench数据集对LLaMA模型进行微调后得到的模型。该模型展现出强大的工具执行能力和对未见API的泛化能力。
相关工作
目前,开源的大语言模型(LLMs),如LLaMA,尽管在基础语言任务上表现出色,但在使用外部工具(API)来完成复杂指令方面能力显著不足。这与顶尖的闭源模型(如ChatGPT)强大的工具使用能力形成鲜明对比。
现有研究在为工具使用构建指令微调数据方面存在几大瓶颈:
- API数量和真实性有限:以往工作要么不涉及真实世界的API,要么仅覆盖极小范围且多样性差的API。
- 应用场景受限:大多数研究局限于仅涉及单个工具的简单指令,而真实世界任务常需要多个工具协同工作。此外,它们通常假设用户会预先指定好API,这在拥有海量API的现实场景中不切实际。
- 规划与推理能力不足:现有方法多采用思路链(CoT)或ReACT等单路径推理框架,这些方法在面对复杂指令时容易因单步错误导致整体失败,探索空间有限。
因此,本文旨在解决的核心问题是:如何弥补开源LLM与闭源LLM在工具使用能力上的差距,通过构建高质量的数据集和开发更优的推理策略,系统性地提升开源LLM掌握和使用大规模真实世界API的能力。
本文方法
本文提出了ToolLLM框架,其核心在于通过高质量的数据、创新的推理方法和系统的训练评估流程,来教会开源LLM使用工具。整个框架由三大部分组成:ToolBench数据集构建、ToolLLaMA模型训练与API检索器,以及ToolEval评估器。
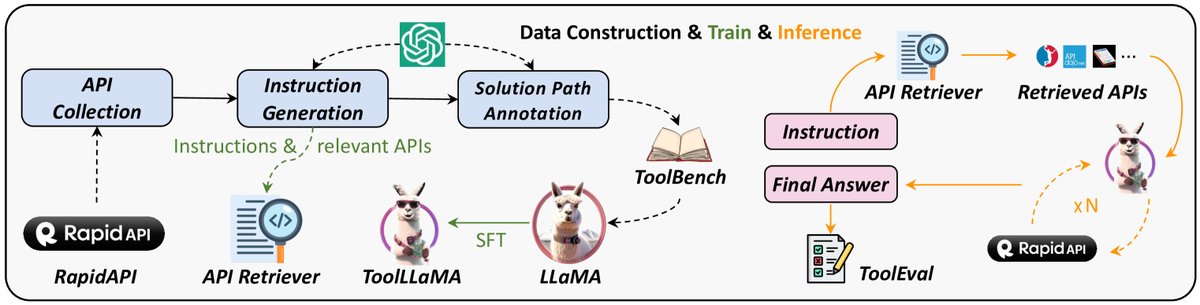
ToolBench数据集构建
ToolBench的构建过程完全自动化,使用ChatGPT作为“数据标注员”,主要分为三个阶段:
1. API收集
从一个大型API市场RapidAPI上收集了16,464个真实的RESTful API,这些API覆盖了金融、社交媒体、电商等49个不同类别。为了确保数据集的质量,对API进行了严格筛选,移除了失效或不稳定的API,最终保留了3,451个高质量工具(包含16,464个API)。
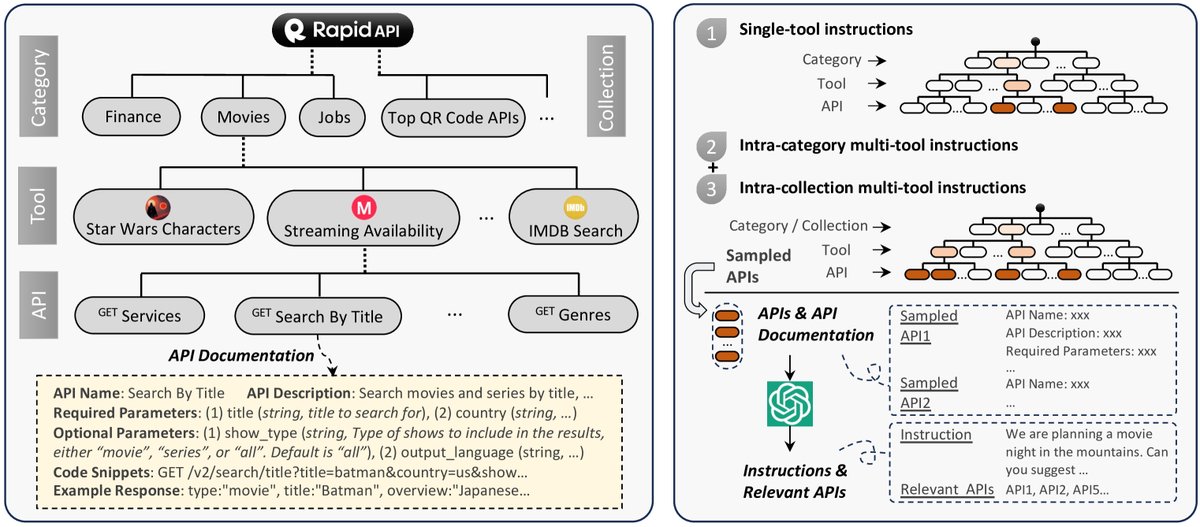
2. 指令生成
为了确保指令的多样性和真实性,本文并非从零开始构思指令,而是先采样API组合,再让ChatGPT围绕这些API生成合适的指令。这种方法覆盖了三种场景:
- I1: 单工具指令:为单个工具内的API生成指令。
- I2: 同类别多工具指令:从同一API类别(如“天气”)中采样2-5个工具,生成需要跨工具协作的指令。
- I3: 同集合多工具指令:从RapidAPI预定义的“集合”(功能或目标相似的工具集)中采样工具,生成更复杂的跨领域协作指令。
通过这种方式,共生成了近20万条高质量的(指令,相关API)数据对,用于后续训练API检索器。
3. 解决方案路径标注
这是本文方法的核心创新所在。传统的ReACT方法只探索一条执行路径,一旦出错就难以挽回。为了解决这个问题,本文提出了深度优先搜索决策树(DFSDT)方法。
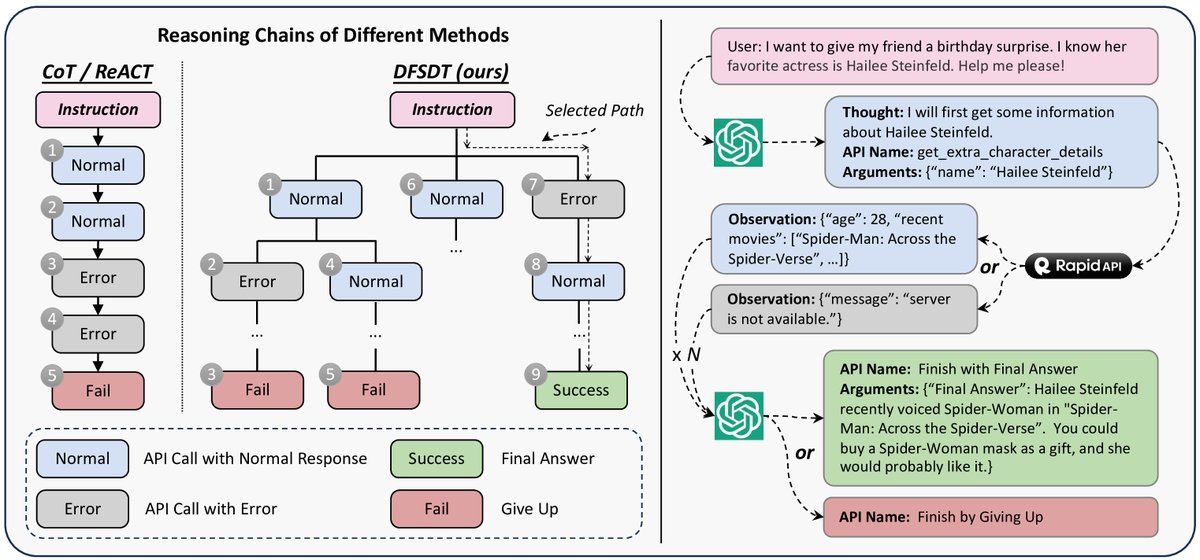
创新点:DFSDT算法
- 树状探索:DFSDT不再是线性地生成“思考-行动”序列,而是构建一个决策树。在每一步,模型可以生成多个可能的下一步行动作为候选分支。
- 评估与回溯:模型可以评估当前路径的有效性。如果一条路径看起来很有希望,就继续深入(深度优先);如果发现当前路径走不通(例如API调用失败或返回无用信息),模型可以调用一个特殊的“放弃”函数,回溯到上一个节点,并尝试探索其他分支。
- 多样化生成:在扩展新节点时,会提示模型生成与已探索路径不同的思考过程,从而增加搜索空间的多样性。
DFSDT的优势在于,它极大地扩展了LLM的探索空间,使其能够“三思而后行”,从多个潜在解决方案中选择最优路径,或在失败后及时“改弦易辙”。这不仅显著提高了复杂指令的求解成功率,也使得为ToolBench标注高质量的“解决方案路径”成为可能。最终,本文筛选出超过12万条成功的(指令,解决方案路径)对,用于微调ToolLLaMA模型。
模型训练与推理流程
ToolLLaMA模型
使用ToolBench数据集中高质量的(指令,解决方案路径)对,对LLaMA-2 7B模型进行微调,得到ToolLLaMA。为了处理API返回的长文本,本文使用位置插值技术将模型的上下文长度从4096扩展到了8192。
API检索器
为了让模型在面对海量API时能够自动找到合适的工具,本文还训练了一个基于Sentence-BERT的神经API检索器。该检索器能够根据用户指令,从16000多个API中高效地检索出最相关的Top-K个API,供ToolLLaMA在后续的决策过程中使用。
整个推理流程如下:
- 用户输入一条指令。
- API检索器从API池中召回最相关的几个API。
- ToolLLaMA接收指令和候选API,利用从DFSDT学习到的决策能力,进行多轮“思考-调用API”的循环。
- 最终,模型整合所有API返回的信息,生成最终答案。
实验结论
本文设计了全面的实验来验证ToolLLM框架的有效性,并开发了自动评估器ToolEval来衡量模型表现。
关键组件的有效性
- API检索器:实验表明,本文训练的API检索器在三个指令类型(I1, I2, I3)上的NDCG@5得分(84.9)远超BM25(17.0)和OpenAI的Ada模型(45.4),证明其能够从海量API中精准地找到所需工具。
| 方法 | I1 | I2 | I3 | 平均 | ||||
|---|---|---|---|---|---|---|---|---|
| NDCG | @1 | @5 | @1 | @5 | @1 | @5 | @1 | @5 |
| BM25 | 18.4 | 19.7 | 12.0 | 11.0 | 25.2 | 20.4 | 18.5 | 17.0 |
| Ada | 57.5 | 58.8 | 36.8 | 30.7 | 54.6 | 46.8 | 49.6 | 45.4 |
| 本文方法 | 84.2 | 89.7 | 68.2 | 77.9 | 81.7 | 87.1 | 78.0 | 84.9 |
- DFSDT的优越性:在使用ChatGPT进行标注时,与ReACT和ReACT@N(多次重复ReACT直到成本相当)相比,DFSDT在所有指令类型上的通过率都实现了大幅领先(平均通过率63.8% vs 35.3% / 44.5%)。尤其是在更复杂的I2(70.6%)和I3(62.8%)多工具任务上,优势更为明显,证明了DFSDT在解决复杂问题上的强大能力。
| 方法 | I1 | I2 | I3 | 平均 |
|---|---|---|---|---|
| ReACT | 37.8 | 40.6 | 27.6 | 35.3 |
| ReACT@N | 49.4 | 49.4 | 34.6 | 44.5 |
| DFSDT | 58.0 | 70.6 | 62.8 | 63.8 |
模型性能与泛化能力
-
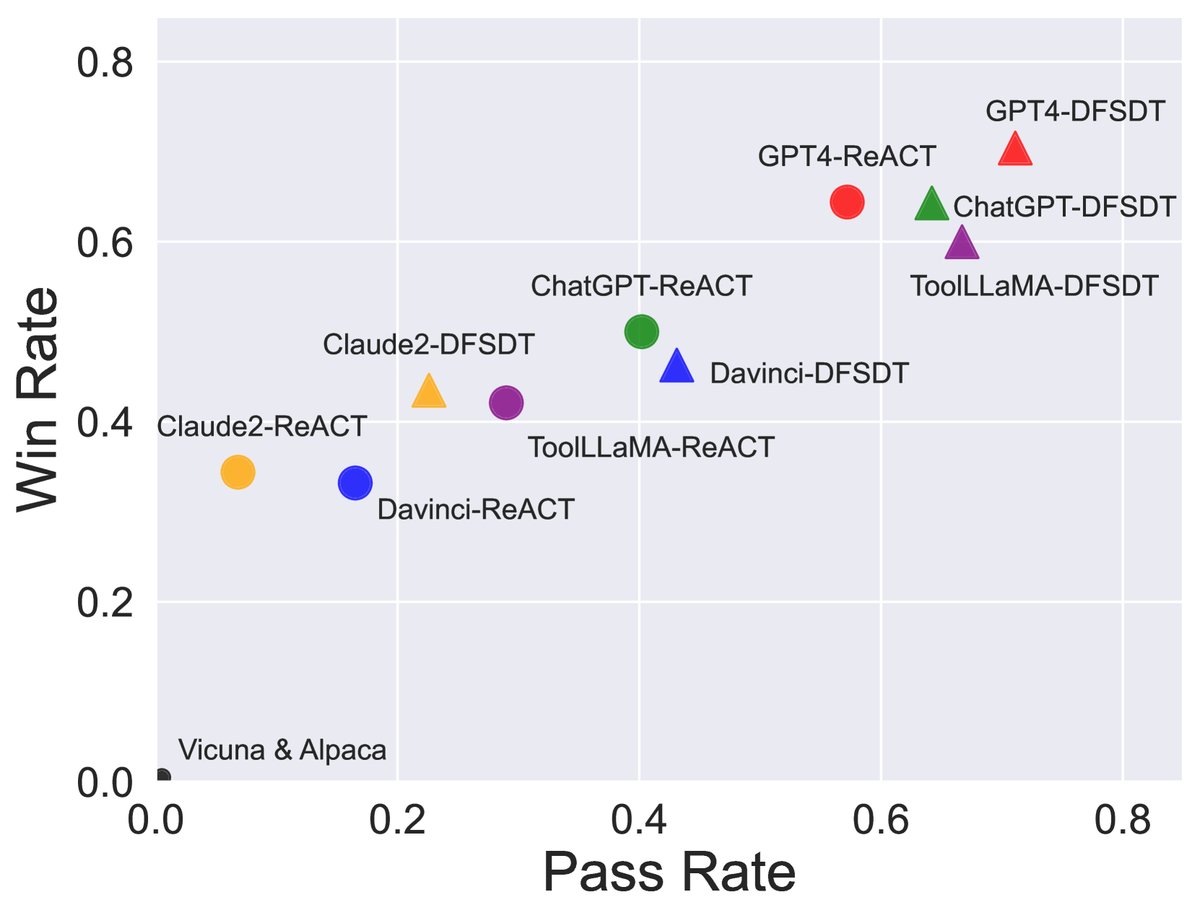
ToolLLaMA表现出色:在主实验中,ToolLLaMA的表现远超其他开源对话模型Vicuna和Alpaca(通过率和胜率均为0),并优于Text-Davinci-003和Claude-2。其整体性能与作为“教师模型”的ChatGPT相当,仅次于最强的GPT-4。这证明了ToolBench和微调策略的有效性。
-
强大的泛化能力:ToolLLaMA不仅能在训练过的工具上表现良好,在面对未见过的指令、未见过的工具、甚至未见过类别的工具时,依然保持了很高的通过率和胜率,平均通过率达到66.7%。这表明模型学会了理解API文档并进行泛化的通用能力。
-
与API检索器结合效果更佳:有趣的是,将ToolLLaMA与本文的API检索器结合使用时,性能甚至优于提供标准答案API的情况(平均通过率67.3% vs 66.7%)。这说明检索器有时能找到比预设答案更优或功能更强的替代API,进一步增强了系统的实用性。
| 模型 | 方法 | I1-Inst. | I1-Tool | I1-Cat. | I2-Inst. | I2-Cat. | I3-Inst. | 平均 |
|---|---|---|---|---|---|---|---|---|
| 通过率/胜率 | 通过率/胜率 | 通过率/胜率 | 通过率/胜率 | 通过率/胜率 | 通过率/胜率 | 通过率/胜率 | ||
| ChatGPT | ReACT | 41.5 / - | 44.0 / - | 44.5 / - | 42.5 / - | 46.5 / - | 22.0 / - | 40.2 / - |
| GPT4 | DFSDT | 60.0 / 67.5 | 71.5 / 67.8 | 67.0 / 66.5 | 79.5 / 73.3 | 77.5 / 63.3 | 71.0 / 84.0 | 71.1 / 70.4 |
| ToolLLaMA | DFSDT | 57.0 / 55.0 | 61.0 / 55.3 | 62.0 / 54.5 | 77.0 / 68.5 | 77.0 / 58.0 | 66.0 / 69.0 | 66.7 / 60.0 |
| ToolLLaMA | DFSDT-Retriever | 64.0 / 62.3 | 64.0 / 59.0 | 60.5 / 55.0 | 81.5 / 68.5 | 68.5 / 60.8 | 65.0 / 73.0 | 67.3 / 63.1 |
跨领域(OOD)泛化
在与本研究数据集完全不同的APIBench数据集上,未经任何针对性训练的ToolLLaMA表现出强大的零样本泛化能力。在HuggingFace和TorchHub两个领域,ToolLLaMA结合自研检索器,在AST准确率上甚至超过了专门为APIBench训练的Gorilla模型,证明了ToolLLM框架赋予模型的泛化能力是真实且稳健的。
| 方法 | HuggingFace | TorchHub | TensorHub |
|---|---|---|---|
| AST (↑) | AST (↑) | AST (↑) | |
| ToolLLaMA + 本文检索器 | 16.77 | 51.16 | 40.59 |
| Gorilla-ZS + BM25 | 10.51 | 44.62 | 34.31 |
| Gorilla-RS + BM25 | 15.71 | 50.00 | 41.90 |
总结
实验结果有力地证明,ToolLLM框架能够成功地为一个开源LLM注入强大的、可泛化的工具使用能力。通过大规模、贴近现实的ToolBench数据集和创新的DFSDT推理/标注方法,得到的ToolLLaMA模型在复杂的真实API调用任务上达到了与ChatGPT相媲美的水平,为构建更强大、更开放的AI智能体铺平了道路。