TOUCAN: Synthesizing 1.5M Tool-Agentic Data from Real-World MCP Environments
-
ArXiv URL: http://arxiv.org/abs/2510.01179v1
-
作者: Zhangchen Xu; Anurag Roy; Radha Poovendran; Adriana Meza Soria; Rameswar Panda; Shawn Tan
-
发布机构: MIT-IBM Watson AI Lab; University of Washington
TL;DR
本文介绍了一个名为 TOUCAN 的大规模工具智能体数据集,包含 150 万条从近 500 个真实世界 MCP 环境中合成的轨迹,旨在通过提供多样、真实且复杂的训练数据,显著提升开源大型语言模型(LLM)的工具调用和智能体能力。
关键定义
本文主要基于并扩展了现有概念,以下是对理解本文至关重要的核心术语:
- TOUCAN:本文提出的工具智能体数据集(Tool-Agentic dataset)的名称。它是迄今为止最大的公开可用工具智能体数据集,包含 150 万条轨迹,覆盖了并行和多步工具调用、多轮对话以及边缘案例等场景。
- 工具智能体数据/轨迹 (Tool-Agentic Data/Trajectory):指一个任务-轨迹对。其中,任务是用户提出的需要使用工具解决的请求,轨迹则详细记录了智能体为完成该任务所经历的完整交互序列,包括思考规划、工具调用、工具返回的响应以及最终给用户的回答。
- 模型上下文协议 (Model Context Protocol, MCP):一种标准化的接口,旨在简化 LLM 与外部工具和真实世界环境的集成。它提供了一个统一的规范,使 LLM 智能体能够无缝地发现、调用和执行外部工具。本文利用 MCP 服务器作为生成轨迹的真实环境。
相关工作
当前,虽然大型语言模型(LLM)作为智能体在自动化任务方面展现出巨大潜力,但开源社区的发展受限于高质量、开放授权的工具智能体训练数据。
现有的工具调用数据集,如 Gorilla、ToolAlpaca 和 ToolLLM 等,虽然在一定程度上推动了模型工具使用能力的发展,但普遍存在一些局限性:
- 多样性有限:覆盖的工具种类和领域不够广泛。
- 真实性不足:很多数据集依赖模拟的工具响应,而非真实执行结果。
- 交互简单:大多关注单轮、单工具的调用,缺乏复杂的多工具协作和多轮对话场景。
- 规模较小:数据量不足以充分训练出强大的智能体能力。
这些瓶颈限制了开源模型在真实、复杂场景下规划和执行任务的能力。本文旨在解决这一关键问题,即缺乏一个大规模、多样化且贴近真实的工具智能体训练数据集。
本文方法
为了解决上述问题,本文提出了一个系统性的数据生成流程,并构建了 TOUCAN 数据集。其核心在于利用真实的 MCP 环境来合成高质量、大规模的工具智能体轨迹。
数据生成流程
TOUCAN 的构建遵循一个五阶段的流水线,并辅以三个扩展机制来增加数据的多样性。
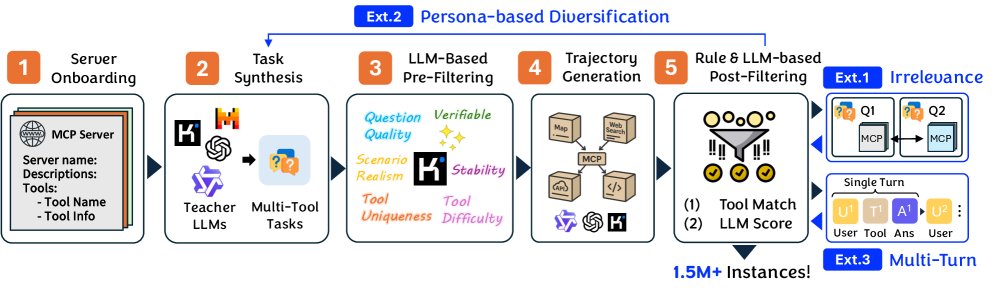
-
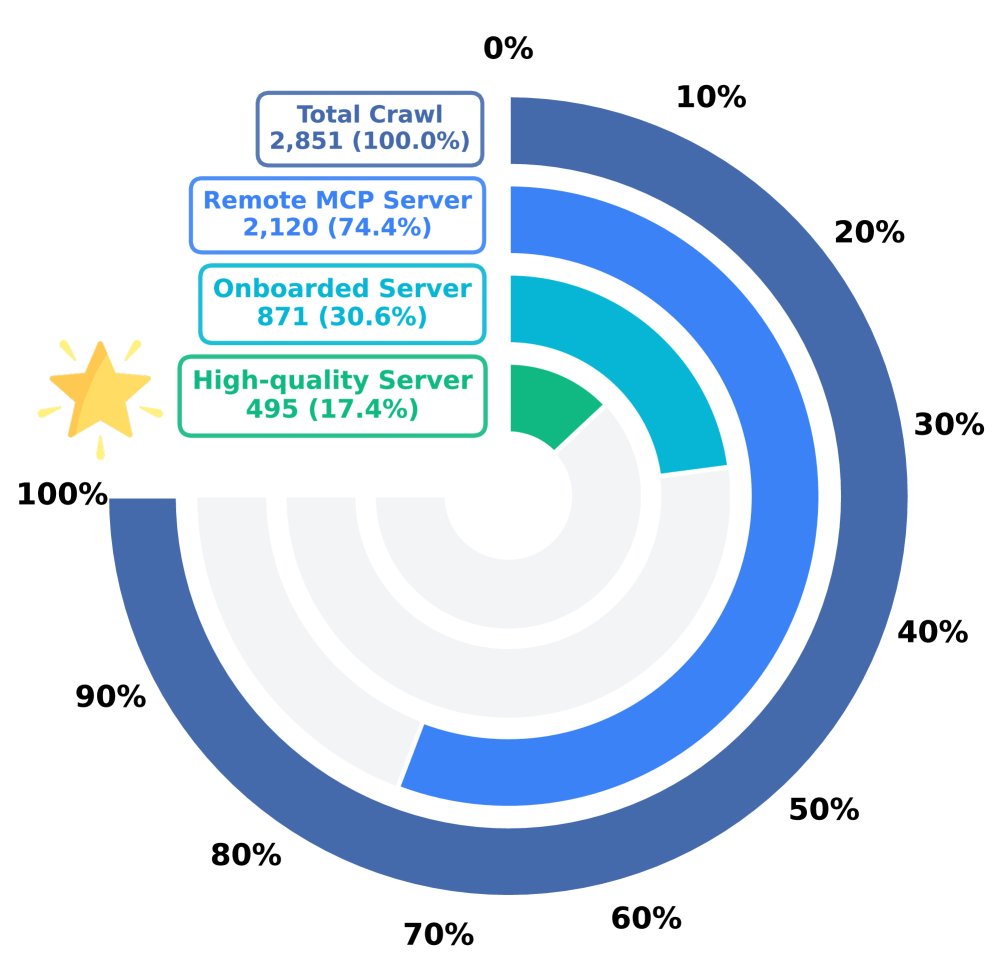
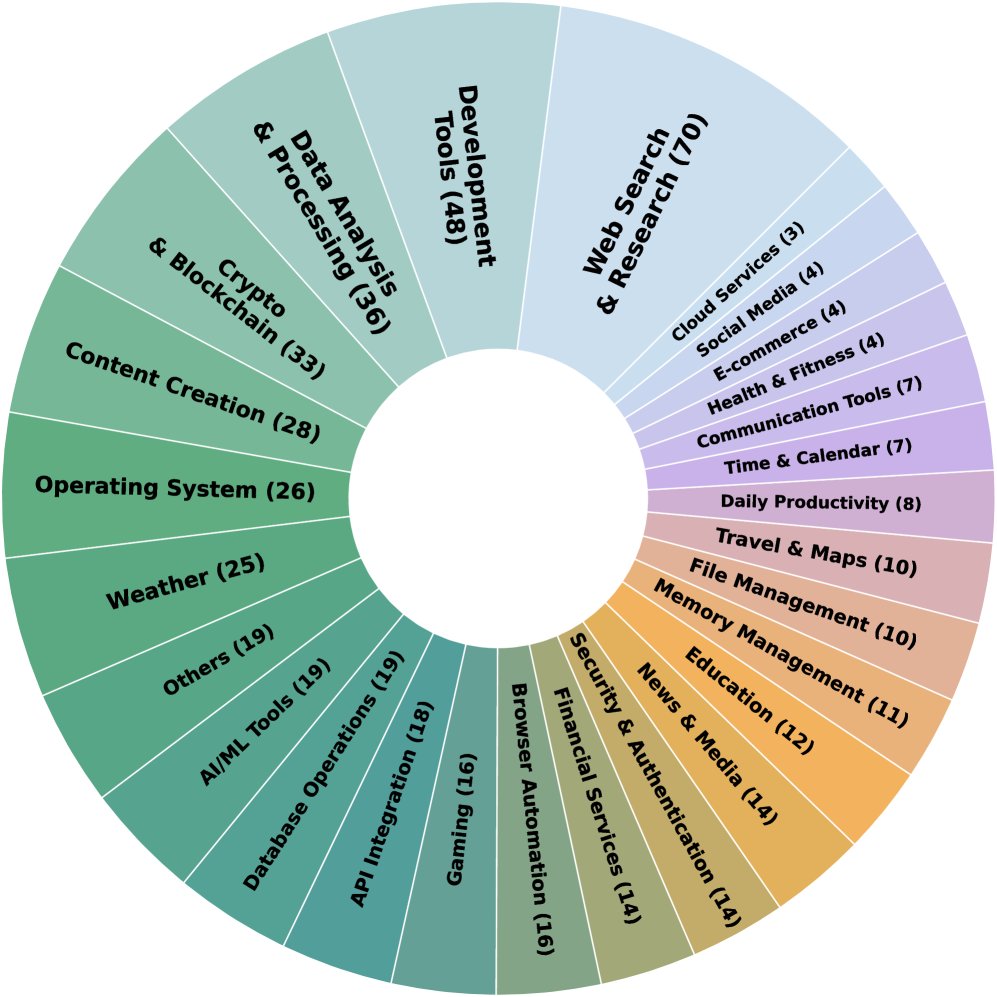
MCP 服务器引入 (MCP Server Onboarding):首先,从 GitHub 和 MCP 服务器注册平台 Smithery 收集了约 2800 个 MCP 服务器规范文件。经过严格筛选(仅保留可通过 HTTP 访问的远程服务器、排除需要第三方凭证的服务器、过滤掉功能异常的服务器),最终确定了 495 个高质量、功能多样的 MCP 服务器作为数据生成的基础环境。
- 任务合成 (Task Synthesis):为了确保任务的挑战性和真实性,本文利用五种不同的开源 LLM(\(Llama-3-70B-Instruct\), \(Qwen2-72B-Instruct\), \(Command-R+\), \(Gemma-2-27B-IT\), 和 \(Mistral-Large\))和三种策略来生成需要使用工具的任务:
- 单服务器任务:针对单个 MCP 服务器,生成调用其 1 到 3 个工具的任务。
- 跨服务器任务:根据服务器的领域分类,组合来自相同或不同领域的服务器,生成需要跨服务器工具协作的复杂任务。
- 自由探索任务:在 25 个精选的代表性服务器中,让 LLM 自由设计场景、选择工具并创建任务。
-
任务过滤 (Task Filtering):使用 \(GPT-4o-mini\) 模型作为评估者,从六个维度(工具选择难度、工具组合独特性、问题质量、场景真实性、答案可验证性、结果稳定性)对合成的任务进行 1-5 分的打分,并筛除低质量任务。
-
轨迹生成 (Trajectory Generation):针对筛选后的高质量任务,使用三种不同的教师模型(\(GPT-4.5-Turbo\), \(Claude-3-Opus\), \(Kimi-K2-Turbo\))结合两种智能体框架(\(LangChain\) 和 \(MetaAgent\)),在真实的 MCP 环境中执行工具调用,生成完整的智能体交互轨迹,包括思考过程、工具调用和真实返回结果。
- 轨迹过滤 (Trajectory Filtering):通过规则和模型两种方式确保轨迹质量。首先,使用基于规则的启发式方法过滤掉执行失败、包含本地路径或未调用指定工具的轨迹。然后,再次使用 \(GPT-4o-mini\) 对轨迹的完整性(是否完全解决了用户问题)和简洁性(是否以最少的步骤完成)进行评分,保留高质量的轨迹。
创新点:三种扩展机制
为了弥补核心流程生成的单轮交互数据的不足,并增加数据多样性,本文设计了三种扩展机制:
- 不相关任务生成 (Irrelevance Generation):通过故意打乱任务与 MCP 服务器的配对,创造出当前工具集无法解决的任务。这旨在训练模型学会识别 unsolvable queries 并拒绝回答,从而减少幻觉。
- 任务多样化 (Persona-based Diversification):引入不同的用户角色(Persona)或增加额外的约束条件来改写现有任务,使其在保持核心工具需求不变的同时,增加场景的丰富度和复杂度。
- 多轮对话生成 (Multi-turn Dialogue Generation):采用两种方式将单轮交互扩展为多轮对话:一是将需要多工具协作的复杂任务拆解成一系列连续的子问题;二是在现有对话基础上,让 LLM 生成自然的追问。
数据集分析
最终生成的 TOUCAN 数据集在多样性和复杂性上表现出色。
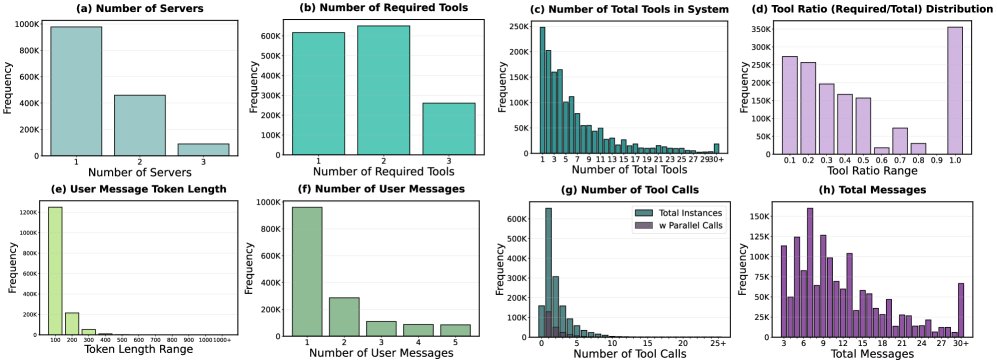
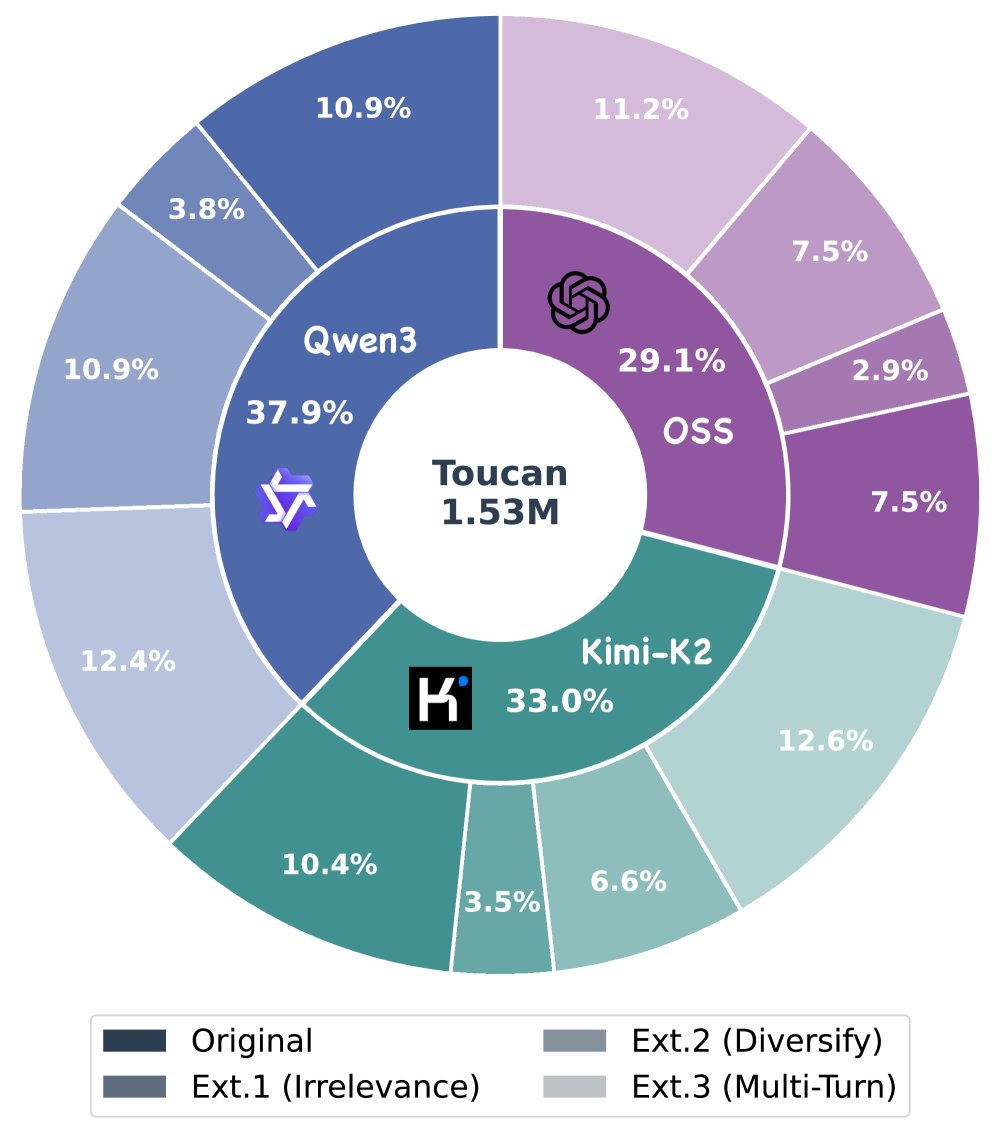
分析显示,TOUCAN 覆盖了大量的多服务器、多工具任务。大部分任务的上下文提供了比实际所需更多的工具,这对模型的工具选择能力提出了挑战。同时,数据集中包含了大量的多轮对话,交互长度和模式多样,更贴近真实世界。
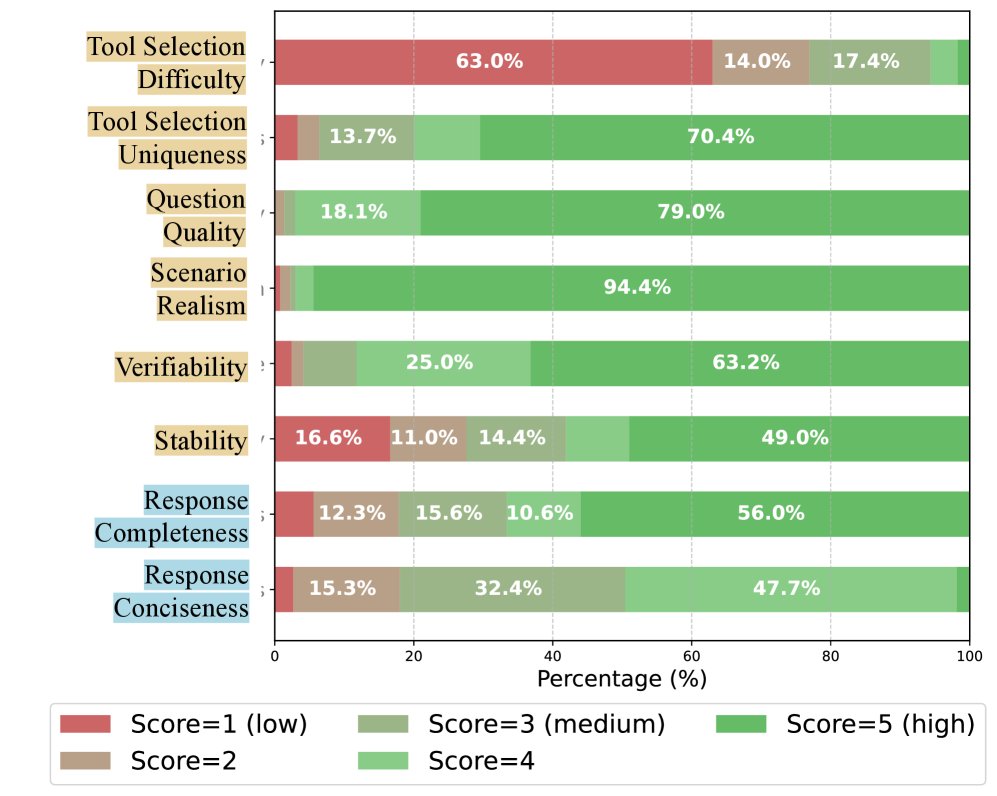
通过 LLM-as-a-judge 的质量评估,大部分任务的问题质量和场景真实性得分很高,轨迹的完整性和简洁性也令人满意。
实验结论
为了验证 TOUCAN 数据集的有效性,本文在 \(Llama-3-8B\), \(Qwen2.5-14B-Instruct\), 和 \(Gemma-2-27B\) 等不同规模的基座模型上进行了监督式微调(SFT),并在多个主流的工具智能体评测基准上进行了评估。
关键实验结果:
- 显著性能提升:在 BFCL V3、τ-Bench 和 τ²-Bench 等基准上,经过 TOUCAN 微调的模型相较于其基座模型,在工具调用和智能体能力各方面均表现出显著提升。
| 模型 | BFCL V3 总分 (Acc) | 单轮 (Acc) | 多轮 (Acc) | 多步 (Acc) | 并行 (Acc) | 不相关 (Acc) |
|---|---|---|---|---|---|---|
| 闭源模型 | ||||||
| GPT-4.5-Preview | 95.82 | 99.41 | 92.51 | 96.00 | 95.42 | 95.73 |
| GPT-4.1-Turbo | 92.14 | 99.07 | 87.23 | 92.17 | 89.92 | 92.31 |
| o3-mini | 92.05 | 98.60 | 85.39 | 91.50 | 91.95 | 92.82 |
| 开源模型 | ||||||
| Llama-3-TC-8B | 82.59 | 93.63 | 75.32 | 80.67 | 78.49 | 84.81 |
| Llama-3-8B-Instruct (基座) | 81.33 | 94.75 | 70.81 | 79.50 | 79.53 | 82.05 |
| Llama-3-8B-Instruct (TOUCAN) | 88.94 | 97.80 | 81.04 | 87.50 | 87.31 | 91.03 |
| Qwen2.5-14B-Instruct (基座) | 87.94 | 97.58 | 79.91 | 86.67 | 85.57 | 89.94 |
| Qwen2.5-14B-Instruct (TOUCAN) | 92.20 | 98.41 | 85.39 | 92.50 | 92.17 | 92.53 |
| DeepSeek-V2 | 92.83 | 98.49 | 86.89 | 92.50 | 94.13 | 92.15 |
| Gemma-2-27B-IT (基座) | 90.06 | 98.71 | 82.89 | 88.00 | 89.50 | 91.19 |
| Gemma-2-27B-IT (TOUCAN) | 93.81 | 99.53 | 88.65 | 94.00 | 94.04 | 93.81 |
| 模型 | τ-Bench (Win Rate) | τ²-Bench (Win Rate) |
|---|---|---|
| Llama-3-8B-Instruct (基座) | 49.38 | 51.52 |
| Llama-3-8B-Instruct (TOUCAN) | 53.75 | 58.33 |
| Qwen2.5-14B-Instruct (基座) | 53.75 | 60.18 |
| Qwen2.5-14B-Instruct (TOUCAN) | 55.62 | 63.89 |
| Gemma-2-27B-IT (基座) | 51.25 | 62.04 |
| Gemma-2-27B-IT (TOUCAN) | 55.00 | 62.96 |
- 超越更强的闭源模型:在 BFCL V3 基准上,TOUCAN 微调的模型(如 \(Gemma-2-27B\))的平均准确率甚至超过了像 \(GPT-4.1-Turbo\) 这样更大规模的闭源模型。
-
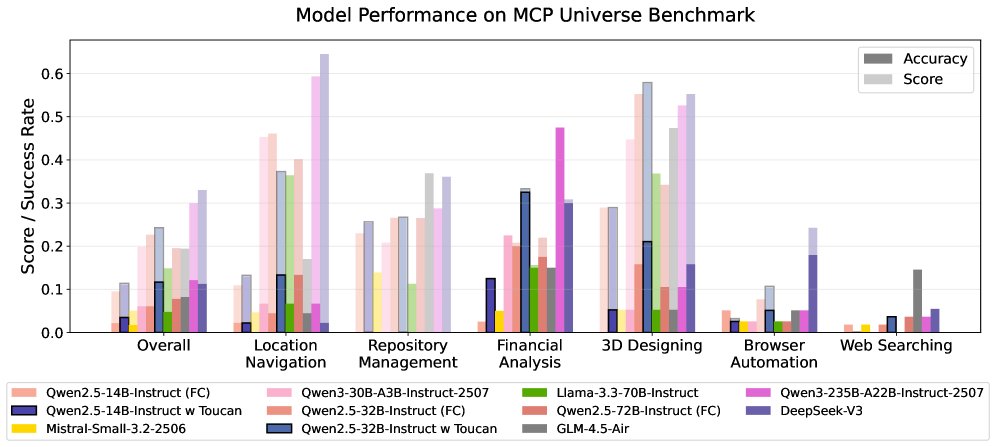
在真实环境中表现优异:在 MCP-Universe 基准(该基准包含许多 TOUCAN 训练时未见过的工具)上,TOUCAN 微调的模型在同等参数规模的开源模型中取得了最佳性能,证明了 TOUCAN 带来的泛化能力。
-
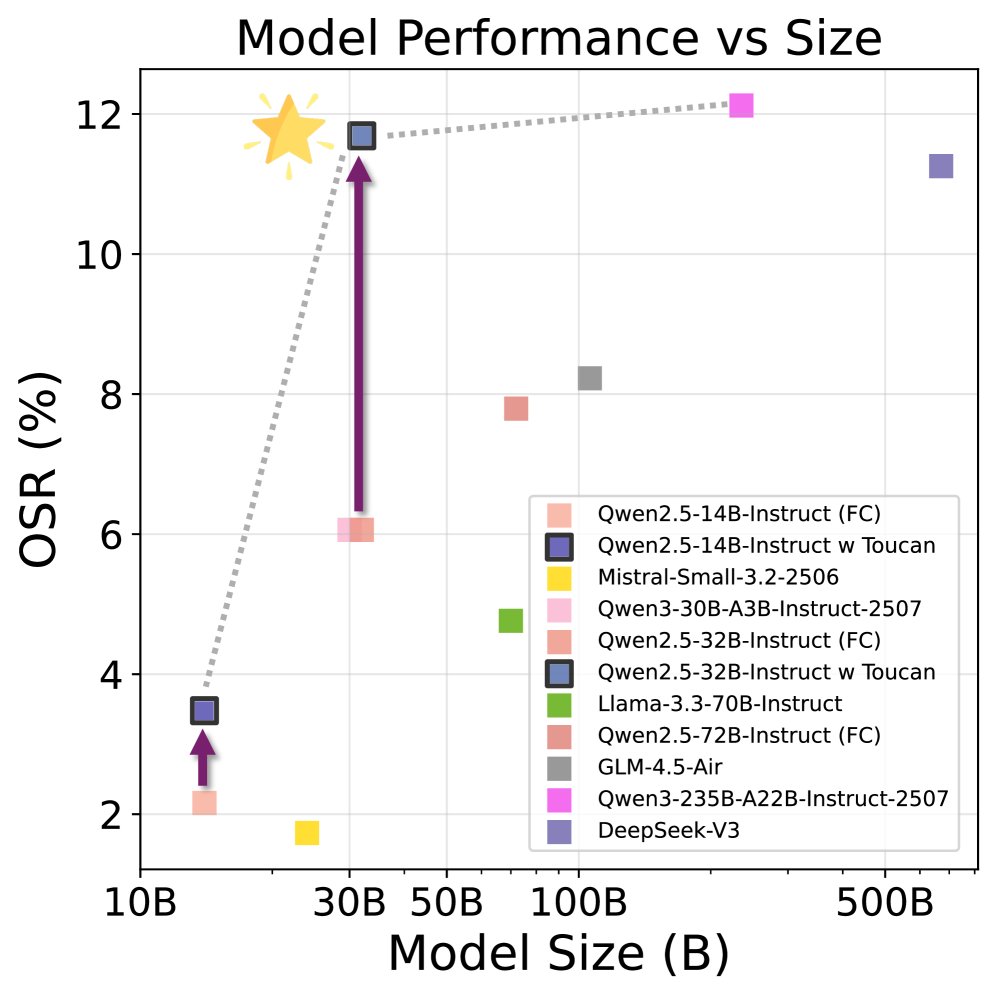
提升效率前沿:实验表明,经过 TOUCAN 微调的模型能够在更小的模型尺寸下达到更高的任务成功率,有效推动了模型在智能体任务上的“帕累托前沿”,实现了更优的性能-效率权衡。
- 消融实验验证:对三种扩展机制(不相关任务、多样化、多轮对话)的消融分析证实,每个部分都对模型的最终性能有积极贡献。
| 微调数据 | 总分 (Acc) |
|---|---|
| Core (81.1k) | 90.58 |
| Core + Ext.1 (Irrelevance, 40k) | 91.26 |
| Core + Ext.1 + Ext.2 (Diversify, 15.8k) | 91.46 |
| Core + Ext.1 + Ext.2 + Ext.3 (Multi-Turn, 35.2k) | 92.20 |
最终结论: 本文成功构建了目前规模最大、最接近真实世界的工具智能体数据集 TOUCAN。实验证明,使用 TOUCAN 微调可以显著增强开源 LLM 的工具规划、调用和多轮交互能力,使其在多个评测基准上达到甚至超越了更大规模的闭源模型,有力地推动了开源社区在 LLM 智能体领域的发展。