Train on Validation (ToV): Fast data selection with applications to fine-tuning
-
ArXiv URL: http://arxiv.org/abs/2510.00386v1
-
作者: Andrea Montanari; Eren Sasoglu; Ayush Jain
-
发布机构: Granica Computing Inc.; Stanford University
TL;DR
本文提出了一种名为“在验证集上训练 (Train on Validation, ToV)”的快速数据选择方法,通过反转训练集和验证集的传统角色,依据训练样本在模型于少量目标验证集上微调后的预测损失变化来为其评分,从而高效地筛选出对提升目标任务性能最有益的数据。
关键定义
本文的核心是提出了一种新的数据选择框架,其关键概念如下:
- 在验证集上训练 (Train on Validation, ToV): 一种数据选择策略。其核心思想不是像传统方法那样,通过在验证集上评估训练样本的影响来为训练样本打分,而是反过来:先在少量目标验证数据上短暂地训练模型,然后评估这种训练对整个训练池中每个样本的预测损失产生了多大影响。损失变化越大的样本被认为越有价值。
- 训练-验证对称性 (Train-Validation Symmetry): 本文方法所依赖的核心理论洞察。它指出,在梯度下降的一阶近似下,单个训练样本 \(x\) 对验证样本 \(z\) 损失的减少量,约等于验证样本 \(z\) 对训练样本 \(x\) 损失的减少量。ToV利用这一对称性,将计算成本高昂的“在验证集上评估训练样本”问题,转化为计算成本低得多的“在训练池上评估验证集训练效果”的问题。
- ToV 分数 (ToV Score): 用于衡量训练池中每个样本重要性的指标。对于一个训练样本 \(x\),其ToV分数被定义为模型在验证集上训练前后,在该样本 \(x\) 上的损失变化量。具体计算为 \(loss(θ_val, x) - loss(θ_bas, x)\),其中 \(θ_bas\) 是在基础数据上训练后的模型,\(θ_val\) 是在其基础上进一步用验证集微调后的模型。分数越高的样本被认为与目标任务越相关。
相关工作
当前,在微调大型模型时,从异构数据源中选择与目标任务分布最匹配的训练数据至关重要,但这通常面临目标领域数据稀缺的挑战。
领域内的主流方法(State-of-the-Art, SOTA)大多基于影响函数 (influence functions) 的思想,通过估算每个训练样本对验证集损失的影响来为其打分。这些方法,如 Pruthi et al. (2020) 和为指令调优设计的 LESS (Xia et al., 2024),虽然有效,但存在显著的计算瓶颈:它们通常需要计算或近似计算每个样本的梯度,甚至Hessian向量积,这在处理大规模训练池和长序列时变得非常昂贵和复杂。
本文旨在解决现有数据选择方法计算成本高、实现复杂的 конкретный问题。它提出了一种更简单、更快速的替代方案,旨在不牺牲性能的前提下,大幅降低数据选择过程的计算开销。
本文方法
方法动机与核心洞察
传统方法评估一个训练样本 \(x\) 的价值,会估算在 \(x\) 上进行一步梯度下降后,验证集 \(Z_val\) 的损失变化。以一阶泰勒展开近似,这个变化量约为 \(η * <∇ℓ(θ, z), ∇ℓ(θ, x)>\),其中 \(z\) 是验证样本。这个表达式在 \(x\) 和 \(z\) 上是对称的。
本文利用了这种对称性。与其为训练池中每个样本 \(x\) 计算它对整个验证集的影响(需要 \(N\) 次验证集评估),不如反过来:先用整个验证集 \(Z_val\) 对模型进行一步(或一个epoch)的训练,得到新模型 \(θ_val\),然后计算这个过程对每个训练样本 \(x\) 损失的影响。这个影响,即 \(ℓ(θ, x) - ℓ(θ_val, x)\),可以有效近似原始的影响分数。
这种“角色反转”将计算复杂度从与训练池大小 \(N\) 成正比,转变为几乎与 \(N\) 无关(只需两次对训练池的完整前向传播),从而实现了巨大的效率提升。
ToV 评分算法
本文提出了两种具体的算法实现,以方法A为主。 方法A (Method A) 的流程如下:
- 初始化: 从大规模训练池 \(X\) 中随机抽取一个小的基础子集 \(U\)。模型从预训练参数 \(θ₀\) 开始。
- 迭代评分: 进行 \(L\) 个周期的迭代。在每个周期 \(k\): a. 基础训练: 在基础子集 \(U\) 上训练一个epoch,得到基础模型 \(θ_bas_k\)。 b. 验证集微调: 在 \(θ_bas_k\) 的基础上,使用目标验证集 \(Z_val\) 进行一个epoch的微调,得到验证集微调模型 \(θ_val_k\)。 c. 计算分数: 对于训练池中 \(U\) 之外的每个候选样本 \(xᵢ\),计算其ToV分数:\(φᵢ⁽ᵏ⁾ = F(ℓ(θ_val_k, xᵢ) - ℓ(θ_bas_k, xᵢ))\)。其中 \(F\) 是一个变换函数(如恒等、绝对值等)。 d. 累加分数: 将当前周期的分数累加到总分中 \(φᵢ = φᵢ + φᵢ⁽ᵏ⁾ / L\)。
- 数据选择: 根据计算出的最终平均分数 \(φᵢ\),从高到低选择所需数量 \(n\) 的样本构成最终的训练集 \(S\)。
方法B (Method B) 是一个微小的变体,主要用于理论分析,其区别在于每个周期的基础训练会从上一个周期验证集微调后的模型参数开始。
创新点
- 角色反转: 最核心的创新在于颠覆了传统“训练影响验证”的评估模式,利用对称性原理,通过“验证影响训练”来高效评分,避免了计算每个样本的梯度。
- 计算高效: 该方法仅需要前向传播计算损失 (forward losses),无需计算反向传播的梯度 (per-example gradients) 或更高阶的导数,使其在计算上极为轻量,易于实现和扩展。
- 通用性: 该框架适用于各种任务,只需定义相应的损失函数即可。
针对Token-based学习的适配
对于指令调优或NER等任务,损失是在token层面计算的。本文将ToV方法适配如下:
- Per-token分数: 对比模型在验证集微调前后的变化,计算每个样本中每个token的对数损失差异 \(Δₜ\)。
-
聚合分数: 使用一个聚合函数 \(F\)(如 \(F(y)=y\), $$F(y)= y \(,\)F(y)=max{y,0}$$)处理每个token的分数后,再对整个序列求平均,得到该样本的最终ToV分数。 - 长度偏见校正: 为避免方法偏好较短序列(因其方差较高),在选择时采用分箱策略。将候选数据按序列长度分为10个箱,从每个箱中独立选出得分最高的样本,确保了所选数据在长度上的多样性。
实验结论
本文在指令调优 (Instruction Tuning, IT) 和命名实体识别 (Named Entity Recognition, NER) 两个任务上对ToV方法进行了广泛验证。
实验设置
- 指令调优: 使用 \(Llama2-7B-chat\) 作为基础模型,在Slim Orca、Alpaca等数据集的不同组合下进行5组实验,模拟了训练池与目标分布不同程度的重合情况。
- 命名实体识别: 使用 \(RoBERTa-base\) 模型,在Multinerd等4个数据集上进行6组实验。
- 对比方法: ToV与随机选择 (Random)、最大不确定性 (Max-Uncertainty) 以及基于影响函数的SOTA方法LESS进行了比较。
关键实验结果
- 指令调优任务:
- ToV在所有实验设置中均显著优于随机选择和最大不确定性选择。
- 在5个实验中的4个,ToV的表现优于复杂的LESS方法。
- 数据选择带来的性能提升非常显著,使用ToV选择一半数据(\(n=8k\))的效果,往往优于或持平于使用随机选择两倍数据(\(n=16k\))的效果,证明了其高效性。
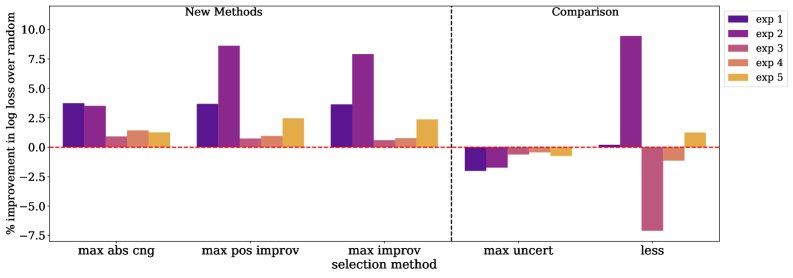
| 实验号 | 目标分布 | 训练池来源 (等比例混合) |
|---|---|---|
| 1 | Slim Orca (SO) | SO, Alpaca GPT-4 (A4), Alpaca GPT-3.5 (A35) |
| 2 | SO | A4, A35 |
| 3 | SO | SO |
| 4 | A4 | SO, A4, A35 |
| 5 | A4 | SO, A35 |
- 命名实体识别任务:
- ToV同样系统性地优于随机选择和最大不确定性方法。
- 与IT任务不同,LESS方法在该任务上表现不佳,未能超过随机选择的基线。而ToV则取得了稳定且显著的性能提升。
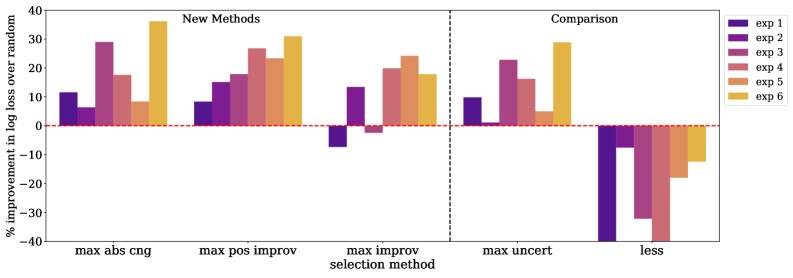
| 实验号 | 目标分布 | 训练池来源 (等比例混合) |
|---|---|---|
| 1 | Multinerd (MN) | MN, Ai4p, C4, Syn-big |
| 2 | MN | Ai4p, C4, Syn-big |
| 3 | MN | MN |
| 4 | Ai4p | MN, Ai4p, C4, Syn-big |
| 5 | Ai4p | MN, C4, Syn-big |
| 6 | Ai4p | Ai4p |
最终结论
实验结果有力地证明,Train on Validation (ToV) 是一种计算成本低、易于实现且极其有效的数据选择方法。在多个任务和不同的数据分布场景下,它不仅能大幅超越简单的基线方法,还能在多数情况下优于当前更复杂的SOTA方法。这表明ToV是微调大模型时进行数据选择的一个极具潜力的实用工具。