Transformer Enhanced Relation Classification: A Comparative Analysis of Contextuality, Data Efficiency and Sequence Complexity
-
ArXiv URL: http://arxiv.org/abs/2509.11374v1
-
作者: Bowen Jing; Yang Cui
-
发布机构: University of Manchester
TL;DR
本文通过系统性的对比实验,证实了基于Transformer的模型在关系分类任务上,无论是在标准性能、长文本处理能力还是数据效率方面,均显著优于传统的非Transformer深度学习模型。
关键定义
本文主要沿用并对比了现有模型,其核心在于评估不同模型在特定任务上的表现。理解本文的关键在于以下概念:
- 关系分类 (Relation Classification, RC):信息抽取的子任务,旨在识别文本中给定实体对(entity pair)之间的语义关系。例如,在句子“奥巴马出生在火奴鲁鲁”中,对于实体对(“奥巴马”,“火奴鲁鲁”),RC任务需要将其分类为“出生地城市”关系。
- 类型化实体标记 (Typed Entity Marker):一种为基于Transformer的模型增强输入表示的技术。它不仅使用特殊符号(如\(@\)和\(#\))来标记实体在句子中的位置,还显式地加入了实体的类型信息(如\(*subj-type*\)和\(^obj-type^\)),帮助模型更好地理解实体并进行关系分类。
相关工作
关系分类(RC)旨在将非结构化文本转化为结构化的(实体1, 关系, 实体2)三元组,是信息抽取的关键环节。
早期的深度学习方法首先采用卷积神经网络(CNNs)来自动学习词汇和句子级别的特征,摆脱了繁琐的人工特征工程。然而,CNN在捕捉长距离依赖方面存在不足。随后,长短期记忆网络(LSTM)等序列模型因其能更好地处理时序特征而受到关注,并通过引入注意力机制和位置感知信息进一步提升了性能。在此基础上,图卷积网络(GCNs)被引入,通过对句子的依存句法树进行编码来捕捉非连续的词语依赖,代表模型如C-GCN。
2017年Transformer模型的提出是自然语言处理领域的革命性突破。其自注意力机制有效解决了长距离依赖问题,且支持并行计算,为大规模预训练模型(如BERT)的出现奠定了基础。BERT及其变体(如RoBERTa, R-BERT, SpanBERT)通过在大规模语料上进行预训练,极大地增强了模型的上下文理解能力,在微调后于关系分类任务上取得了SOTA性能。
近年来,虽然大型语言模型(LLMs)如GPT系列展现出强大的通用能力,但它们在关系分类等特定任务上,性能常不及经过监督微调的BERT类模型,并且面临计算成本高和数据隐私等挑战。因此,领域内缺乏一个系统的实证研究,来比较不同技术路线(特别是Transformer与非Transformer模型)在不同场景下的性能表现。本文旨在填补这一空白,通过全面的实验对比来回答以下问题:
- 不同模型达到有效泛化需要多少数据?
- 句子长度如何影响模型的性能?

本文方法
本文设计了一套系统的实验流程,以实证方式对比了非Transformer模型和基于Transformer的模型在关系分类任务上的性能。
实验设置
研究选择了两类共六种代表性模型进行比较:
- 非Transformer深度学习模型:
- PA-LSTM: 结合了位置信息的位置感知LSTM。
- C-GCN: 结合了LSTM和图卷积网络的模型。
- AG-GCN (Attention Guided GCN): 使用注意力引导图卷积网络。
- 基于Transformer的模型:
- BERT: 经典的双向预训练语言模型。
- RoBERTa: 对BERT进行优化后的模型。
- R-BERT: 专为关系分类设计的BERT变体。
实验在三个广泛使用的数据集上进行:TACRED、TACREV (TACRED修正版) 和 Re-TACRED (TACRED另一修正版)。
评估维度不仅包括传统的Micro F1分数,还涵盖了两个关键的现实场景:
- 序列复杂度分析:在不同句子长度的测试集上评估模型性能,以考察模型处理长文本的能力。
- 数据效率分析:使用不同比例(20%, 40%, 60%, 80%)的训练数据来训练模型,以衡量模型在低资源(少样本)场景下的学习效率。
数据处理
针对两类模型,本文采用了不同的数据预处理流程:
-
非Transformer模型: 遵循传统流程。首先将Token转为小写,然后用实体类型(如\(SUBJ-ORG\))替换实体本身。词嵌入层使用预训练的GloVe向量,词表由数据集词汇和GloVe词汇共同构成,对于未登录词则进行随机初始化。
-
基于Transformer的模型: 采用了类型化实体标记技术来强化输入。
- 对于R-BERT,使用\(@\)和\(#\)分别标记主语和宾语实体。
- 对于BERT和RoBERTa,则进一步引入类型信息,格式为\(@ *subj-type* SUBJECT @ … # ^obj-type^ OBJECT #\)。这种方式明确地将实体的位置和类型信息编码到输入文本中,旨在增强模型对关系的理解能力。
实验结论
实验结果系统地揭示了基于Transformer的模型相对于传统深度学习模型在关系分类任务上的显著优势。
整体性能对比
| 模型 | 训练集: TACRED, 评估集: TACRED | 训练集: TACRED, 评估集: TACREV | 训练集: Re-TACRED, 评估集: Re-TACRED |
|---|---|---|---|
| 非Transformer模型 | |||
| PA-LSTM | 66.33 | 75.83 | 77.29 |
| C-GCN | 64.67 | 73.18 | 76.54 |
| Att-Guide-GCN | 67.11 | 78.07 | 80.68 |
| Transformer模型 | |||
| BERT | 70.1 | 82.26 | 90.13 |
| R-BERT | 69.34 | 82.39 | 89.65 |
| RoBERTa | 71.36 | 84.58 | 91.53 |
- 性能鸿沟:Transformer系列模型的F1分数普遍在80%-90%区间,而-非Transformer模型则在64%-67%区间,存在巨大性能差距。
- 模型表现:在所有模型中,RoBERTa表现最佳,在高质量的Re-TACRED数据集上达到了91.53%的F1分数,几乎达到或超过了人类水平。在非Transformer模型中,AG-GCN性能最优。
- 数据集质量:所有模型在修正后的TACREV和Re-TACRED数据集上的表现均远好于原始的TACRED,证明了修正版数据集的质量更高。
序列复杂度分析
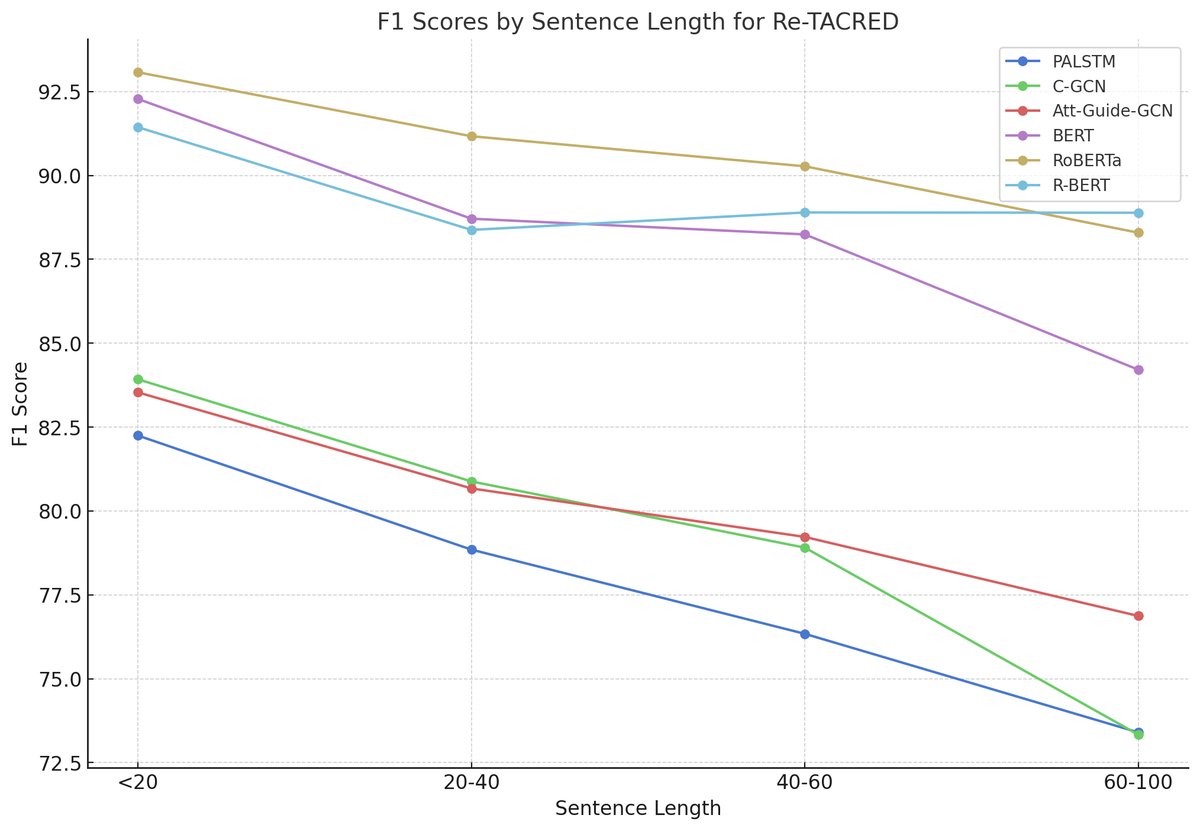
- 长句处理能力:随着句子长度增加,大多数模型的性能呈下降趋势。然而,RoBERTa和R-BERT在处理长序列(超过40个Token)时比标准BERT表现更稳定,显示出更强的长距离依赖建模能力。
- 模型差距:在所有句子长度区间,Transformer模型均一致且显著地优于非Transformer模型。
数据效率分析
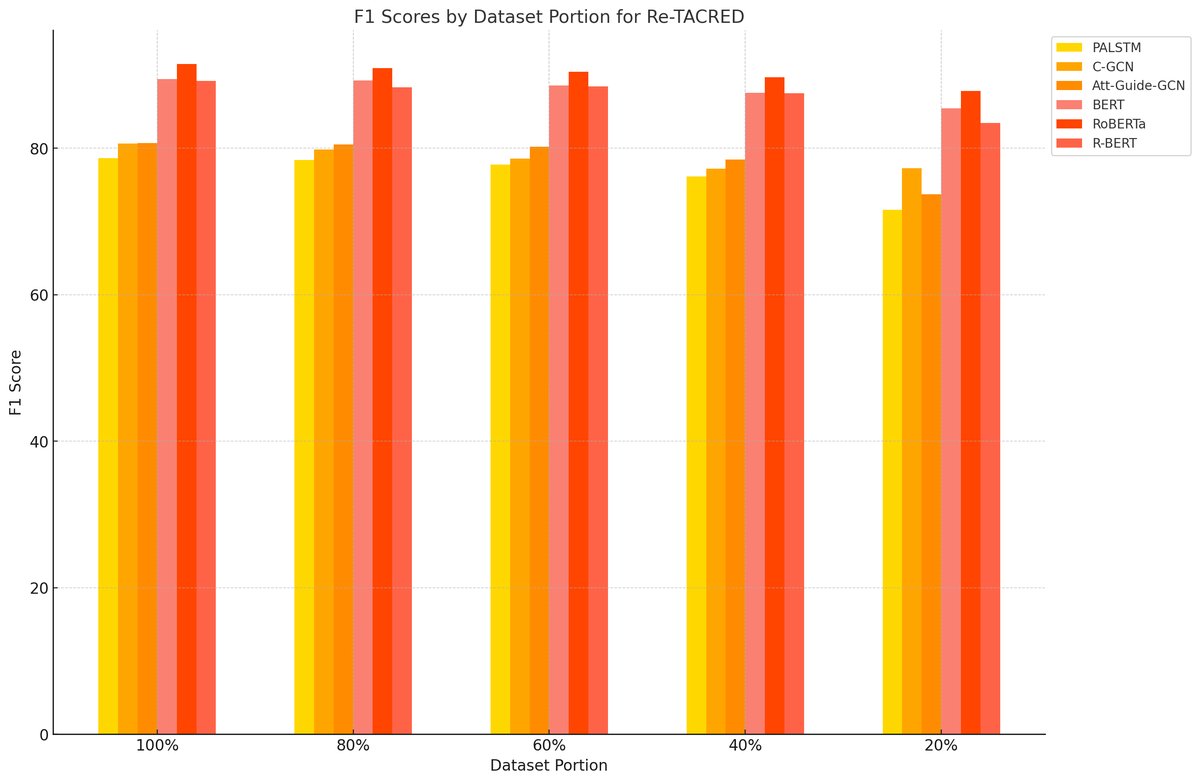
- 少样本学习:当训练数据较少时(如20%),Transformer模型与非Transformer模型之间的性能差距尤为明显。这表明Transformer模型(得益于预训练)具有更强的数据效率和少样本学习能力,能用更少的数据更快地学习到实体间的关系。
- 学习曲线:所有模型的性能都随着数据量的增加而提升。特别是Transformer模型,在数据量从20%增加到40%时性能提升显著,说明它们能快速从新增数据中获益。
总结
实验结果一致表明,基于BERT的Transformer模型在关系分类任务中全面优于传统的深度学习模型。RoBERTa是其中的佼佼者。这些模型不仅性能优越,而且相比于GPT-3等更大规模的通用LLMs,它们在训练和推理上需要更少的计算资源。此外,能够在本地部署运行的能力为处理临床数据等敏感信息提供了关键的数据隐私保障。