Tree Search for LLM Agent Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2509.21240v1
-
作者: Guanhua Chen; Xiangxiang Chu; Yong Wang; Ziyu Ma; Yuxiang Ji; Liaoni Wu
-
发布机构: Alibaba Group; Southern University of Science and Technology; Xiamen University
TL;DR
本文提出了一种名为 Tree-GRPO (Tree-based Group Relative Policy Optimization) 的方法,通过将传统强化学习中独立的链式轨迹采样替换为树搜索采样,从而在有限的 rollout 预算下为多轮智能体任务生成更多、更高质量的轨迹,并利用树结构从稀疏的结果奖励中隐式地构建出步骤级的过程监督信号。
关键定义
- Agent Step-level Node (智能体步骤级节点):本文中树搜索的基本单元。与传统的在 Token 或句子层面进行扩展不同,这里的每个节点代表一个完整的智能体交互步骤,即一个 \((Thought, Action, Observation)\) 元组。这种设计更符合智能体任务的结构化特点。
- Tree-based Rollout (基于树的 Rollout):一种轨迹采样策略。它首先并行生成 M 个独立的轨迹作为 M 棵树的初始主干,然后迭代地从这些树中随机选择节点进行扩展,生成新的分支。通过共享公共前缀,该策略能以更低的 Token/工具调用预算生成更多的训练轨迹。
- Intra-tree Advantage (树内优势):在同一棵树内部,通过比较共享同一父节点的各个分支(子树)最终获得的 outcome rewards,来估计相对优势。这在分叉点上隐式地构建了一个步骤级的偏好学习目标。
- Inter-tree Advantage (树间优势):在所有树生成的全部轨迹中进行比较,估计每个轨迹相对于全局轨迹集合的优势。这提供了一个更稳定、更全局的基线估计。Tree-GRPO 将树内优势和树间优势结合使用。
相关工作
当前,将强化学习(RL)应用于大型语言模型(LLM)智能体面临两大挑战:
- 高昂的 Rollout 预算:智能体任务通常涉及多轮与环境的交互,每个决策序列(trajectory)可能包含数千个 Token 和多次工具调用。现有的方法通常为每个任务独立采样多条完整的轨迹(链式采样),这导致了大量的冗余计算和高昂的API调用成本。
- 长时序任务中的监督信号稀疏:尽管轨迹很长,但大多数智能体RL方法仅依赖于任务完成后的最终 outcome reward(结果奖励)。这种单一的、稀疏的奖励信号很难精确地反馈到多步决策链条中的某一个具体步骤,导致信用分配(credit assignment)困难,学习效率低下,甚至训练崩溃。
本文旨在解决的核心问题是:在有限的 rollout 预算下,如何仅利用最终的 outcome reward,为智能体强化学习构建更细粒度的过程监督信号,以提升学习效率和性能。
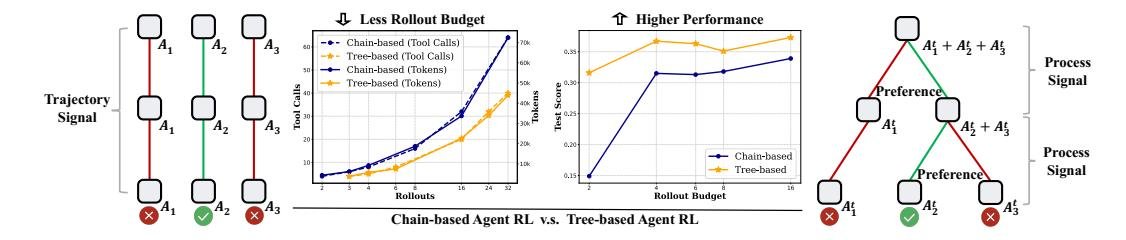 图1: 链式与树式采样在LLM多轮智能体RL中的对比。树结构带来两大优势:(i) 更少的 rollout 预算(Token和工具调用);(ii) 更高的性能。
图1: 链式与树式采样在LLM多轮智能体RL中的对比。树结构带来两大优势:(i) 更少的 rollout 预算(Token和工具调用);(ii) 更高的性能。
本文方法
为了应对上述挑战,本文提出了 Tree-GRPO,其核心是使用树搜索代替传统的链式采样,并在此基础上设计了独特的优势估计方法。
 图3: Tree-GRPO 训练流程概览。Rollout 以树搜索方式进行,每个节点对应一个完整的“思考-动作-观察”步骤。分组相对优势在树内和树间两个层面上进行估计,从而以更少的 rollout 预算构建步骤级过程监督信号。
图3: Tree-GRPO 训练流程概览。Rollout 以树搜索方式进行,每个节点对应一个完整的“思考-动作-观察”步骤。分组相对优势在树内和树间两个层面上进行估计,从而以更少的 rollout 预算构建步骤级过程监督信号。
Rollout策略:基于智能体步骤的树搜索
与在 Token 或句子层面进行搜索不同,Tree-GRPO 将一个完整的智能体交互步骤 \((τ, α, o)\) 定义为树的一个节点。这种设计与智能体任务的内在结构完美契合。
 图2: 链式与树式 rollout 在不同层面的对比。左:链式 rollout。中:节点为 Token/句子的树搜索。右(本文方法):节点为完整智能体步骤的树搜索。
图2: 链式与树式 rollout 在不同层面的对比。左:链式 rollout。中:节点为 Token/句子的树搜索。右(本文方法):节点为完整智能体步骤的树搜索。
其采样过程如下:
- 初始化 (Initialization):为每个任务提示(prompt)并行生成 M 条独立的轨迹,作为 M 棵树的初始骨架。
- 采样 (Sampling):从每棵树中随机选择 N 个非叶子节点进行下一步扩展。
- 扩展 (Expansion):对于每个被选中的节点,将其从根到该节点的路径作为上下文,继续生成后续的轨迹,并将新生成的轨迹作为新的分支嫁接到原树上。 通过重复步骤2和3,可以在固定的 Token/工具调用预算 $B$ 内生成远超链式采样的轨迹数量。例如,一次树扩展的期望成本仅为单条完整轨迹的一半 ($\frac{B}{2}$),而能得到一条新的训练数据。
创新点
本文方法的核心创新在于,通过树形结构的设计,巧妙地解决了效率和监督稀疏两大难题。
-
优点1:高效采样 通过在树中共享轨迹的公共前缀,极大地减少了重复生成相似内容的开销,降低了训练所需的 Token 和工具调用成本。在同等预算下,树搜索可以获得比链式采样多约1.5倍的样本。
-
优点2:隐式过程监督 树的结构天然地提供了过程监督的视角。在树的每个分叉点,不同子分支最终导向了不同的结果。通过回溯(back-propagate)这些分支叶子节点的 outcome rewards,可以在分叉点形成自然的偏好对比。例如,一个分支获得了高分,另一个分支失败了,这为模型在这一步的决策提供了明确的偏好信号(preference signal),相当于实现了步骤级的 Direct Preference Optimization (DPO)。
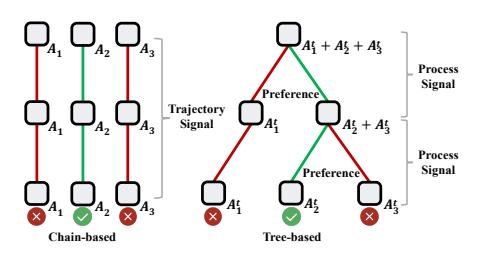 图4: 链式与树式 rollout 的对比。树结构天然地在分叉点(branching point)提供了过程信号。
图4: 链式与树式 rollout 的对比。树结构天然地在分叉点(branching point)提供了过程信号。
优势估计:树内与树间的结合
为了充分利用树结构带来的好处,同时保证训练的稳定性,Tree-GRPO 结合了两种优势估计:
- 树内分组相对优势 ($\hat{A}_{\text{Intra-tree}}$):在同一棵树内,比较从同一父节点分支出去的不同轨迹的奖励,计算相对优势。这部分主要贡献了细粒度的步骤级偏好信号。
- 树间分组相对优势 ($\hat{A}_{\text{Inter-tree}}$):将所有树生成的所有轨迹放在一起,计算每个轨迹在全局范围内的相对优势。这提供了一个更稳定和可靠的基线(baseline)。
最终的优势估计是两者的加和:$\hat{A}_{\text{tree}} = \hat{A}_{\text{Intra-tree}} + \hat{A}_{\text{Inter-tree}}$。
最终的优化目标函数为:
\[J_{\text{Tree-GRPO}}(\theta) = \mathbb{E}_{x \sim \mathcal{D}, \mathcal{H}^{\text{tree-search}} \pi_{\text{old}}(\cdot \mid x)} \left[ \frac{1}{G} \sum_{i=1}^{G} \frac{1}{ \mid \mathcal{H}^{i} \mid } \sum_{t=1}^{ \mid \mathcal{H}^{i} \mid } \min\left(r_{i,t}(\theta) \hat{A}_{\text{tree}}(\mathcal{H}^{i}), \\ \operatorname{clip}(r_{i,t}(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_{\text{tree}}(\mathcal{H}^{i}) \right) - \beta \mathbb{D}_{\text{KL}} \left( \pi_{\theta}(\mathcal{H} \mid x) \ \mid \pi_{\text{ref}}(\mathcal{H} \mid x) \right) \right]\]其中 $r_{i,t}(\theta)$ 是重要性采样率,$\pi_{\text{ref}}$ 是参考模型。
理论分析
本文从理论上证明了,在二元偏好假设下,树内优势优化(Intra-tree GRPO)的梯度结构与步骤级 DPO 的梯度结构是等价的,两者都具有 $\nabla_{\theta} J = w \cdot (\nabla_{\theta} \log p_{\theta}(\mathcal{H}_{\geq t}^{win}) - \nabla_{\theta} \log p_{\theta}(\mathcal{H}_{\geq t}^{loss}))$ 的形式,区别仅在于权重项 $w$ 的不同。这表明 Tree-GRPO 确实在在线 RL 框架内实现了隐式的步骤级偏好学习。
实验结论
本文在 11 个数据集上进行了广泛实验,涵盖单跳QA、多跳QA和网络智能体QA三类任务,并与多种基线方法进行了对比。
主要性能
- 多跳QA:在需要多轮交互的复杂任务中,Tree-GRPO 表现出巨大优势。对于小模型(如1.5B, 3B),相比链式RL方法(GRPO),取得了 16% 到 69% 的显著相对提升。即使在14B的大模型上,也带来了8.4%的改进。
- 单跳QA:在此类简单任务中,Tree-GRPO 依然稳定优于基线,但优势不如多跳任务明显,因为轨迹深度有限,过程监督的增益也有限。
- 网络智能体QA:在更具挑战性的网络智能体任务上,尽管RL的整体提升受限于训练数据质量,Tree-GRPO 仍然一致地优于链式 GRPO,尤其在 GAIA 数据集上平均提升 28%。
| 方法类型 | 方法 | NQ | Trivia | PopQA | Avg./ $\Delta_{rel}^{\%}$ | Hotpot | 2wiki | Musiq | Bamb | Avg./ $\Delta_{rel}^{\%}$ |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen2.5-3b | ReAct | 21.1 | 43.5 | 28.3 | 31.0 | 19.2 | 19.1 | 4.8 | 20.0 | 15.8 |
| + GRPO | 44.4 | 58.0 | 42.0 | 48.1 $\Delta_{base}$ | 39.0 | 36.3 | 15.2 | 36.8 | 31.8 $\Delta_{base}$ | |
| + Tree-GRPO | 46.8 | 59.7 | 43.6 | 50.0 +4.0% | 42.4 | 43.7 | 17.8 | 43.2 | 36.8 +16% |
表1: 单跳与多跳 QA 任务上的 EM 得分摘要(以 Qwen2.5-3b 为例)。Tree-GRPO 在所有任务上均超越链式 GRPO。
定量分析
- 预算效率:实验证明,Tree-GRPO 具有极高的预算效率。在 rollout 预算被严格限制时(如每 prompt 仅2次完整轨迹预算),链式RL方法学习困难,而 Tree-GRPO 仍能取得巨大成功(相对提升112%)。Tree-GRPO 仅用链式方法 1/4 的预算,就能达到更优的性能。
| 预算 (每个 prompt) | 方法 | 单跳 QA Avg. | 多跳 QA Avg. |
|---|---|---|---|
| 约2次轨迹 | Chain-based | 46.5 | 14.9 |
| Tree-based | 49.7 (+6.9%) | 31.6 (+112%) | |
| 约4次轨迹 | Chain-based | 48.1 | 31.8 |
| Tree-based | 50.0 (+4.0%) | 36.8 (+16%) |
表3: 不同训练预算下的性能对比(Qwen2.5-3b)。显示 Tree-GRPO 在低预算下优势尤其明显。
- 智能体行为:除了分数提升,Tree-GRPO 还鼓励智能体进行更长的交互,即进行更多轮的工具调用(平均从2.4次增加到3.0次)。这表明模型学会了通过更复杂的探索来解决问题,而不是寻求不合理的捷径,这对于解决长时序复杂任务至关重要。
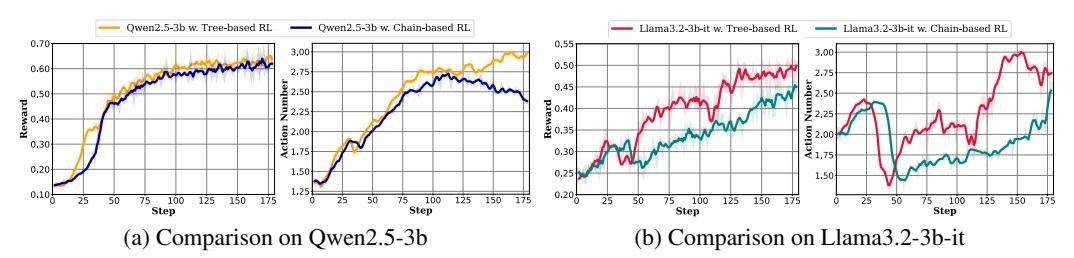 图5: 树式与链式RL在奖励和动作数上的对比。树式方法获得了更高的奖励,并鼓励了更多的动作(工具调用)。
图5: 树式与链式RL在奖励和动作数上的对比。树式方法获得了更高的奖励,并鼓励了更多的动作(工具调用)。
- 优势函数消融:实验验证了结合树内和树间优势的必要性。仅使用树内优势($\hat{A}_{intra-tree}$)会导致训练不稳定甚至崩溃;而两者的结合,既引入了步骤级偏好学习,又保证了稳定性。
总结
Tree-GRPO 通过创新的树搜索采样和双层优势估计,在不增加外部监督的情况下,有效解决了LLM智能体强化学习中的预算和稀疏奖励两大瓶颈。实验证明,该方法在多种任务和模型上均显著优于传统的链式RL方法,尤其是在低预算和复杂长时序任务中,展现了卓越的效率和性能。