UNIFORM: Unifying Knowledge from Large-scale and Diverse Pre-trained Models
-
ArXiv URL: http://arxiv.org/abs/2508.19498v1
-
作者: Chen Chen; Jingtao Li; Jiabo Huang; Weiming Zhuang; Lingjuan Lyu; Yimu Wang
-
发布机构: SONY AI; University of Waterloo
TL;DR
本文提出了一个名为 UNIFORM 的统一知识迁移框架,旨在从大量异构(不同架构、不同训练数据)的预训练模型中,通过新颖的特征投票和Logit投票机制,解决知识冲突问题,从而高效地将共识知识迁移到一个学生模型中,且无需任何手动标注。
关键定义
- UNIFORM: 本文提出的核心框架,全称为 Unifying Knowledge from Large-scale and Diverse Pre-trained Models。它是一个统一的知识迁移框架,能够从大量、多样化的现成模型中学习,对教师模型的架构或训练数据几乎没有限制。
- 预测型教师 (Predictive Teachers): 指那些在与目标任务一致的标签空间上训练的模型。这类教师能够直接为目标类别提供预测分数(Logits),例如领域自适应中的源模型或开放词汇分类器。
- 描述型教师 (Descriptive Teachers): 指那些虽然没有在目标类别上训练,但能提供信息丰富的通用视觉特征表示的模型。这类教师在任意标签空间上学习的视觉表示都可以被利用。
- 特征投票 (Features Voting): UNIFORM中用于处理特征层面知识冲突的核心机制。它首先将所有教师的特征映射到统一的潜在空间,然后通过计算特征符号的共识方向,过滤掉与大多数教师不一致的“噪声”特征维度,最后聚合得到一个更可靠的、经过去噪的特征表示用于指导学生模型学习。
- Logit投票 (Logits Voting): UNIFORM中用于处理预测层面知识冲突的核心机制。它通过在所有预测型教师的预测结果中进行投票,确定一个最可信的伪标签(pseudo-class)。在进行知识蒸馏时,该机制会特别强调这个伪标签,从而减轻因不同教师预测不一致而对学生模型造成的干扰。
相关工作
目前,利用多个预训练模型知识的方法主要有模型合并(Model Merging)、专家混合(Mixture-of-Experts, MoE)和知识蒸馏(Knowledge Distillation, KD)。
- 现状与瓶颈:
- 模型合并:虽然直接,但要求所有模型的网络架构必须相同,这限制了其在多样化的模型库中的应用。
- 专家混合 (MoE):通过路由机制在不同子模块(专家)间切换,但对存储和计算资源要求很高,在资源受限的场景下难以部署。
- 知识蒸馏 (KD):分为基于Logit和基于特征两种。基于Logit的方法要求教师和学生共享相同的标签空间,受限于数据偏见;而单纯基于特征的方法又忽略了教师预测中蕴含的高层语义信息。现有方法难以同时处理架构和训练数据均不相同的异构模型。
- 本文要解决的问题: 如何设计一个统一的框架,能够有效地从大量、多样化(包括不同架构、不同训练数据)的公开预训练模型中整合并迁移知识,以训练一个强大的、无需人工标注数据的目标识别模型,同时克服现有方法在处理异构性方面的局限性。
本文方法
本文提出了UNIFORM框架,旨在从一个由\($N^p\)$个预测型教师和\($N^d\)$个描述型教师组成的庞大模型集合中,为一个在无标签数据上训练的学生模型提供监督信号。其核心在于设计了两个创新的投票机制来解决来自不同教师的知识冲突。

图1: (a) 公开模型的数量近年来急剧增加。(b) UNIFORM框架利用这些模型作为知识来源,从预测型教师和描述型教师中进行知识迁移来训练一个强大的视觉模型。这些教师可以是同构的,也可以是异构的(不同的数据集D,不同的架构A,或两者都不同A&D)。
创新点1:特征投票与迁移 (Features Voting and Transfer)
为了解决不同教师(尤其是描述型教师)因训练数据和架构不同而产生的特征表示冲突(例如,特征向量中对应维度的符号相反),本文设计了一个两阶段的特征投票机制。
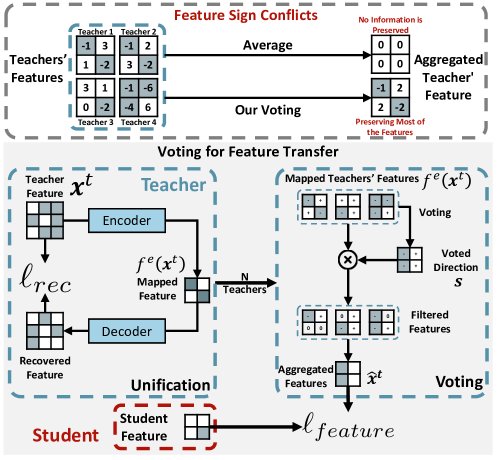
图2: (上) 特征冲突示例。简单地对教师特征求平均可能因符号冲突而抵消,导致信息量减少。(下) UNIFORM的特征投票与迁移机制。首先将所有教师特征统一到公共空间,然后通过投票解决特征符号冲突,过滤掉与多数方向不一致的特征,最后将聚合后的特征迁移给学生。
-
特征统一 (Features Unification): 首先,为每个教师模型配备一个编码器\($f\_i^e(\cdot)\)$,将其原始特征\($\mathbf{x}\_i^t\)$映射到一个与学生模型共享的\($D\)$维公共潜在空间。同时,使用一个解码器\($f\_i^d(\cdot)\)$和重构损失\($\ell\_{rec}\)$来保证映射过程中的信息保真度。
\[\ell_{rec}=\sum_{i\in[N^{t}]}\lVert f^{d}_{i}(f^{e}_{i}(\mathbf{x}^{t}_{i}))-\mathbf{x}^{t}_{i}\rVert_{2}\] -
特征投票 (Features Voting): 为解决直接平均特征导致的符号冲突问题,本文提出对特征符号进行投票,以确定一个共识方向向量\($\mathbf{s}\)$。
\[\mathbf{s}=\operatorname{sgn}\left(\sum_{i\in[N\_{teachers}]}\operatorname{sgn}(f^{e}_{i}(\mathbf{x}_{i}^{t}))\right)\] -
特征聚合与迁移: 基于共识方向\($\mathbf{s}\)$,过滤掉那些与\($\mathbf{s}\)$符号不一致的特征元素,然后对剩余的有效特征进行加权平均,得到最终的聚合特征\($\hat{\mathbf{x}}^{t}\)$。学生模型的特征\($\mathbf{x}\)$通过最小化与\($\hat{\mathbf{x}}^{t}\)$的距离来进行学习。
\[\ell_{feature}=\operatorname{dist}(\mathbf{x},\hat{\mathbf{x}}^{t})\]
创新点2:Logit投票与迁移 (Logits Voting and Transfer)
不同的预测型教师,即使在相同的标签空间训练,由于架构的归纳偏见(如CNN关注局部,Transformer关注全局),其预测的Logit分布也可能存在冲突,从而迷惑学生模型。
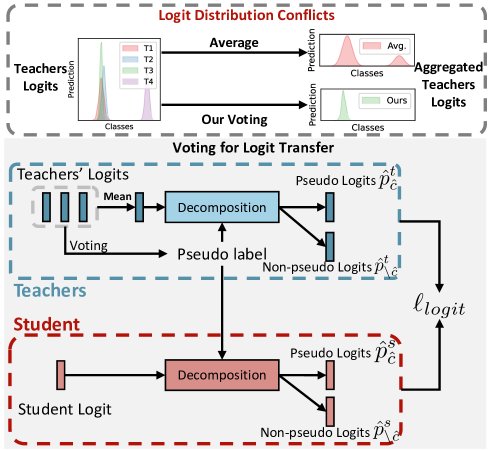
图3: (上) Logit分布冲突示例。教师们不一致的预测分布会迷惑学生。(下) UNIFORM的Logit投票与迁移机制。它不直接平均Logit,而是首先通过投票选出一个伪类别,然后在知识迁移中重点强调该类别,避免混淆。
-
Logit投票 (Logits Voting): 首先,在所有\($N^p\)$个预测型教师的最高分预测中进行投票,选出得票最多的类别作为该样本的伪类别\($\hat{c}\)$。
\[\hat{c}=\arg\max\tilde{p},\text{ where }\tilde{p}=\{\frac{\sum_{i\in[N^{p}]}\mathbb{1}[\arg\max\_{j\in[1,C]}p^{t}_{i,j}=c]}{N^{p}} \mid \forall c\in[C]\}\] -
加权Logit迁移: 在计算Logit层面的知识蒸馏损失时,对伪类别\($\hat{c}\)$和其他非伪类别赋予不同的权重\($\alpha\_1\)$和\($\alpha\_2\)$(通常\($\alpha\_1 > \alpha\_2\)$)。这使得学生模型更加关注教师们达成共识的预测,而减弱噪声信号的影响。
\[\ell_{logit}= \underbrace{H(\hat{p}^{t})}_{\text{constant}}+\underbrace{\alpha_{1}(\hat{p}_{\hat{c}}^{t}\log{p}_{\hat{c}})}_{\text{pseudo class}}+\underbrace{\alpha_{2}(\sum_{c\in[1,C],c\neq\hat{c}}\hat{p}_{c}^{t}\log{p}_{c})}_{\text{non-pseudo classes}}\]
整体训练目标
UNIFORM的总损失函数是上述几个部分的加权和:
\[\mathcal{L}=\ell_{logit}+\beta_{1}\ell_{feature}+\beta_{2}\ell_{rec}\]训练完成后,所有教师模型和辅助的编解码器都会被丢弃,只保留轻量的学生模型用于推理。
实验结论
本文在多达11个基准数据集上进行了广泛实验,使用了超过100个不同架构(ResNet, ViT, Swin, ConvNeXt)和训练数据的公开模型作为教师。
核心结果
- 有效性: 在不同规模的数据集组合(2个、5个和11个)上,UNIFORM的性能均显著优于所有基线方法(如KD, CFL, OFA, 以及本文为对比而设计的CFL+)。如下表所示,随着任务复杂度的增加(数据集增多),UNIFORM的优势愈发明显,有时学生模型的性能甚至超过了有监督训练的单个教师模型。
| 方法 | 需要标注数据? | 预测型教师 | 描述型教师 | CUB200 | Flowers102 | Pets | Cars | Dogs | 平均(数据集) | 平均(类别) |
|---|---|---|---|---|---|---|---|---|---|---|
| 预测型教师 (ViT) | $\checkmark$ | 86.59 | 96.86 | 93.13 | 82.80 | 85.90 | - | - | ||
| KD [22] | $\times$ | $\checkmark$ | 85.26 | 95.85 | 89.42 | 71.76 | 67.83 | 82.03 | 80.05 | |
| OFA [19] | $\times$ | $\checkmark$ | 86.21 | 97.89 | 90.98 | 74.70 | 73.36 | 84.62 | 82.57 | |
| CFL+ | $\times$ | $\checkmark$ | $\checkmark$ | 85.69 | 95.67 | 93.51 | 72.70 | 88.46 | 87.21 | 84.39 |
| UNIFORM | $\times$ | $\checkmark$ | $\checkmark$ | 86.43 | 98.11 | 93.68 | 77.10 | 88.40 | 88.75 | 86.15 |
- 鲁棒性: 在包含11个数据集的极具挑战性的场景中,尽管教师间的干扰更强,UNIFORM仍然展现出最佳的平均性能,证明了其处理复杂知识冲突的鲁棒性。
消融研究与分析
- 投票机制的有效性: 消融实验(如表4)证实,特征投票和Logit投票两个模块都对性能有显著贡献,二者结合使用时效果最佳,验证了缓解知识冲突的重要性。
- 教师类型的影响: 实验(如表5)表明,同时使用预测型和描述型教师比仅使用预测型教师效果更好。UNIFORM在这两种设定下都比基线方法有显著提升,证明其能有效利用两种类型的知识。
- 学生架构的通用性: UNIFORM在多种学生架构(ResNet-50, ViT, SwinTransformer, ConvNeXt)上均表现出色,且更先进的架构能从整合的知识中获益更多。
| 方法 | 投票机制 | 平均(数据集) | 平均(类别) |
|---|---|---|---|
| CFL+ | 无 | 87.21 | 84.39 |
| UNIFORM | 仅 Logit 投票 | 88.59 | 85.97 |
| UNIFORM | 仅特征投票 | 88.33 | 86.71 |
| UNIFORM | 两者皆有 | 88.75 | 86.15 |
可扩展性分析
- 对教师数量的扩展性: 实验结果表明,随着描述型教师数量的增加,UNIFORM的性能持续提升,即使教师数量超过100个也未出现饱和。相比之下,基线方法(CFL+)在教师数量达到约30个时性能便已饱和。这充分证明了UNIFORM在利用大规模模型库方面的卓越扩展能力。
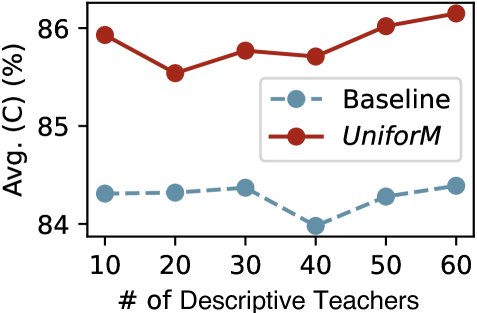
图5(b): 在5数据集设定下,随着描述型教师数量增加,UNIFORM(蓝色)的平均类别准确率持续提升,而基线方法CFL+(橙色)很快饱和。
最终结论
本文提出的UNIFORM框架通过新颖的投票机制,成功解决了从大规模异构模型库中进行知识迁移时的核心挑战——知识冲突问题。实验证明,该方法不仅性能优越,而且具有强大的可扩展性,为在无标注数据情况下利用海量在线模型资源提供了一条有效途径。