Unifying Large Language Models and Knowledge Graphs: A Roadmap
-
ArXiv URL: http://arxiv.org/abs/2306.08302v3
-
作者: Linhao Luo; Jiapu Wang; Chen Chen; Xindong Wu; Shirui Pan; Yufei Wang
-
发布机构: Beijing University of Technology; Griffith University; Hefei University of Technology; Monash University; Nanyang Technological University; Zhejiang Lab
引言
大语言模型(Large Language Models, LLMs),例如ChatGPT和GPT-4,因其涌现能力和泛化性,在自然语言处理和人工智能领域引发了新的浪潮。然而,LLMs是黑箱模型,常常难以捕获和访问事实性知识。相比之下,知识图谱(Knowledge Graphs, KGs)是结构化的知识模型,明确地存储了丰富的实体知识。KGs能够通过提供外部知识来增强LLMs的推理能力和可解释性。同时,KGs自身存在构建和演进困难的问题,使得现有方法难以生成新事实和表示未见知识。因此,统一LLMs和KGs,协同利用它们的优势,是互补且必要的。
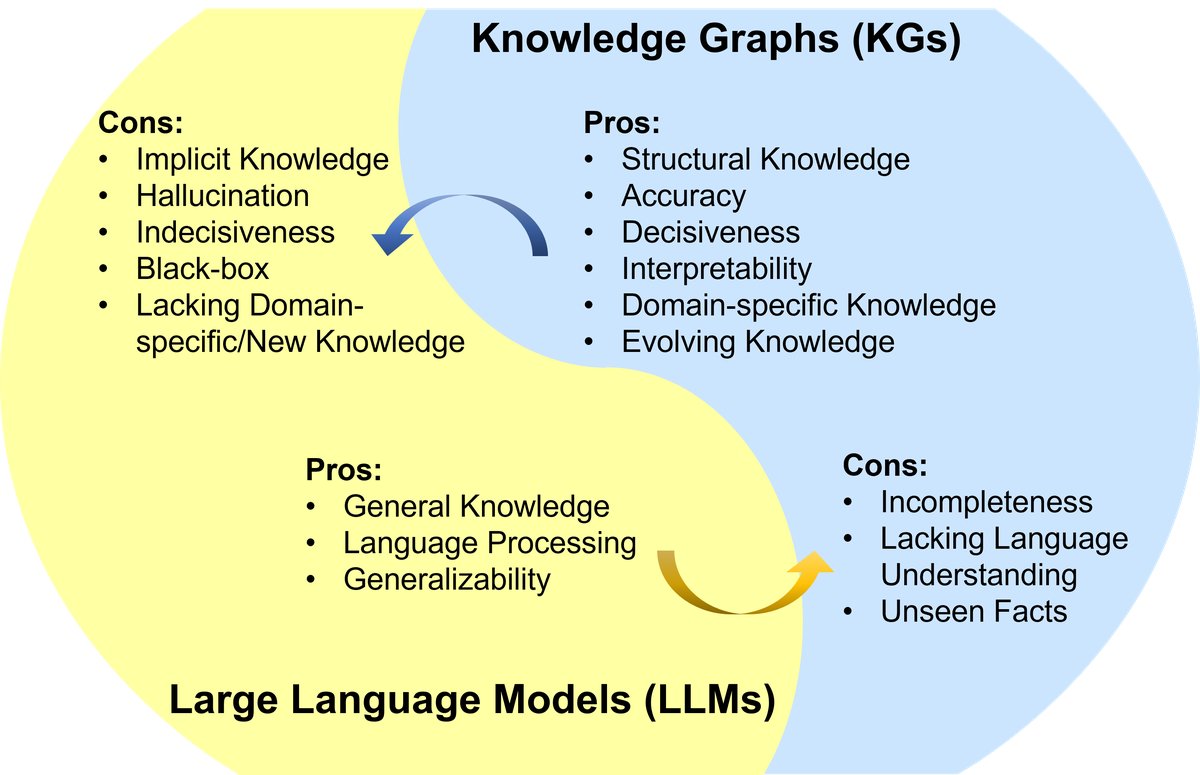
图1: LLM与KG的优缺点总结。LLM优点: 通用知识、语言处理、泛化能力;LLM缺点: 隐式知识、幻觉、不确定性、黑箱、缺乏领域/新知识。KG优点: 结构化知识、准确性、确定性、可解释性、领域特定知识、可演进知识;KG缺点: 不完整性、缺乏语言理解能力、无法处理未见事实。
本文旨在为统一LLMs和KGs提供一个前瞻性的路线图。该路线图包含三个通用框架:
- 知识图谱增强的LLMs (KG-enhanced LLMs):在LLMs的预训练和推理阶段融入KGs,或用于增进对LLM所学知识的理解。
- 大语言模型增强的KGs (LLM-augmented KGs):利用LLMs处理不同的KG任务,如嵌入、补全、构建、图到文本生成和问答。
- 协同的LLMs+KGs (Synergized LLMs + KGs):LLMs和KGs扮演同等重要的角色,以互利的方式工作,实现数据和知识双驱动的双向推理,共同增强双方。
本文回顾并总结了这三个框架下的现有工作,并指出了未来的研究方向。
背景
大语言模型 (LLMs)
LLMs是在大规模语料库上预训练的语言模型,在多种自然语言处理(NLP)任务中表现出色。大多数LLMs源于Transformer架构,该架构利用自注意力(self-attention)机制赋能其编码器和解码器模块。
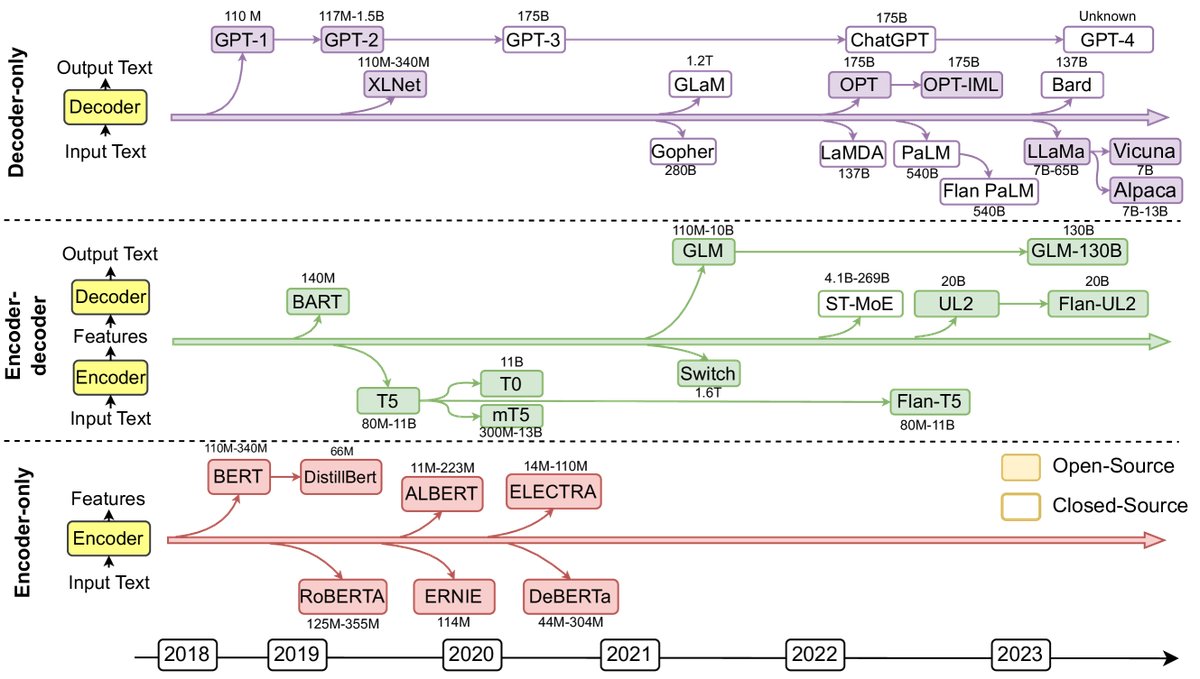
图2: 近年来的代表性大语言模型(LLMs)。实心方块表示开源模型,空心方块表示闭源模型。
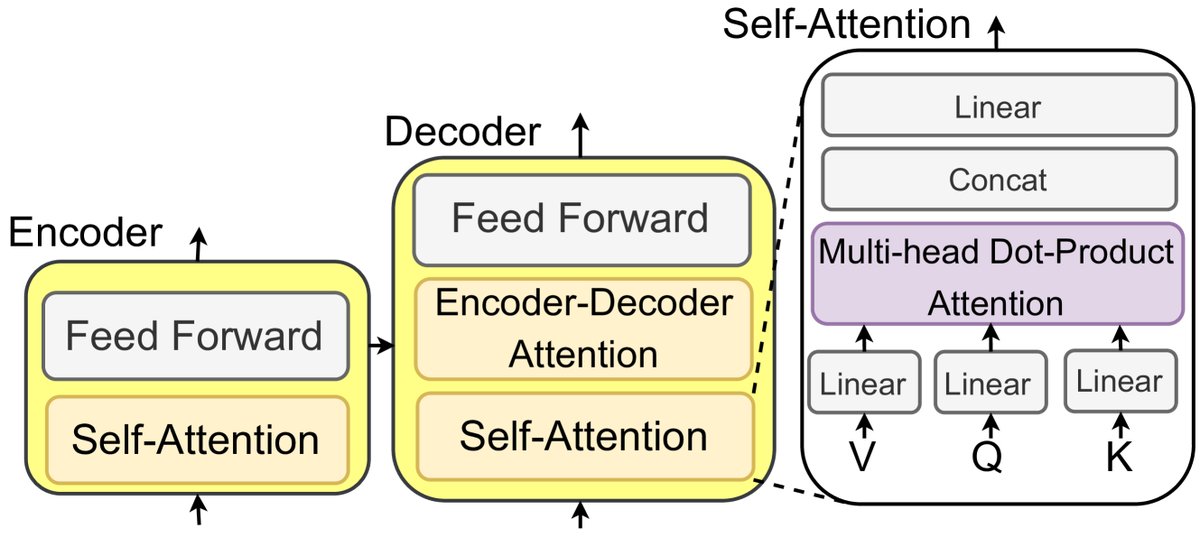
图3: 基于Transformer和自注意力机制的LLM示意图。
根据架构,LLMs可分为三类:
- 仅编码器LLMs (Encoder-only LLMs):如BERT、RoBERTa,用于理解整个句子,适用于文本分类和命名实体识别等任务。
- 编码器-解码器LLMs (Encoder-decoder LLMs):如T5、GLM-130B,用于根据上下文生成文本,适用于摘要、翻译和问答任务。
- 仅解码器LLMs (Decoder-only LLMs):如GPT系列、LLaMA,用于根据上文预测下一个词,通过少量示例或指令即可执行下游任务。
提示工程 (Prompt Engineering)
提示工程是通过设计和优化提示(prompts)来最大化LLM在各种应用中性能的新兴领域。一个提示通常包含指令(Instruction)、上下文(Context)和输入文本(Input Text)。例如,思维链(Chain-of-thought, CoT)提示通过引导模型进行中间步骤推理,来解决复杂任务。提示工程也使得将KGs这类结构化数据整合进LLMs成为可能,例如通过模板将KG线性化为文本段落。
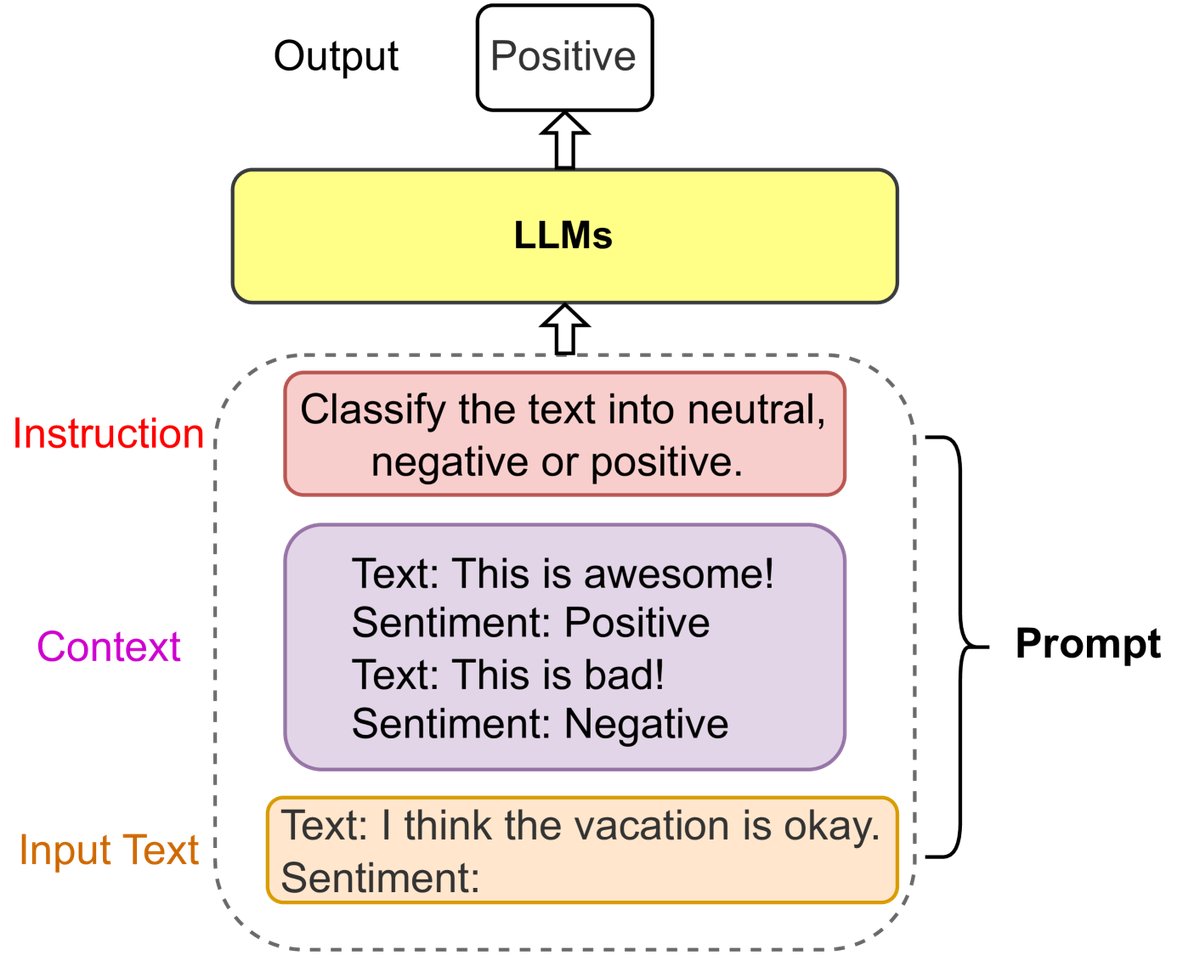
图4: 一个情感分类提示的例子。
知识图谱 (KGs)
知识图谱以三元组 $\mathcal{KG}={(h,r,t)\subseteq\mathcal{E}\times\mathcal{R}\times\mathcal{E}}$ 的形式存储结构化知识,其中 $\mathcal{E}$ 是实体集,$\mathcal{R}$ 是关系集。
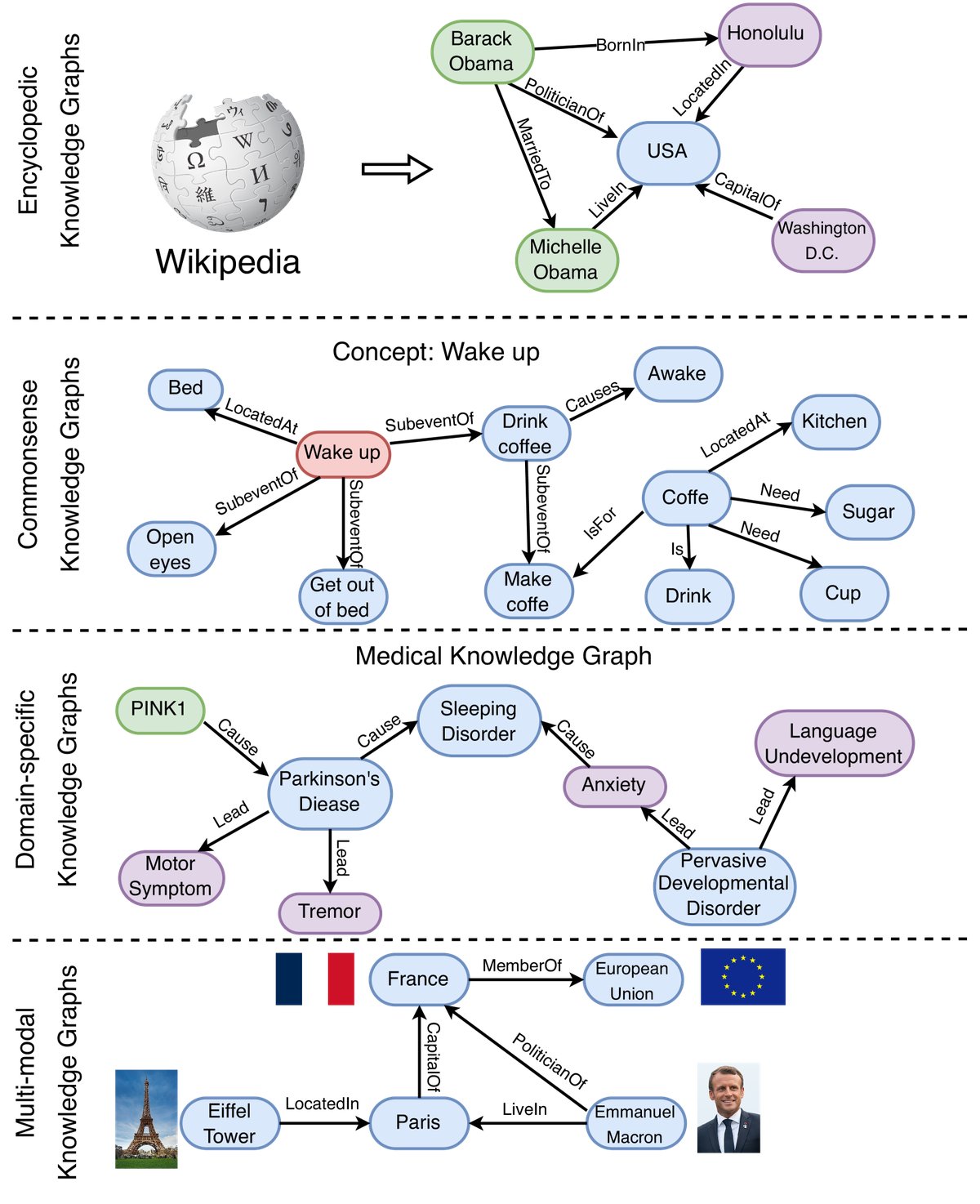
图5: 不同类别知识图谱的示例,包括百科知识图谱、常识知识图谱、领域知识图谱和多模态知识图谱。
根据存储的信息类型,KGs可分为四类:
- 百科知识图谱 (Encyclopedic KGs):表示现实世界中的通用知识,如Wikidata、Freebase、YAGO。它们通常从维基百科等大型信息源构建。
- 常识知识图谱 (Commonsense KGs):存储日常概念、物体和事件及其关系的知识,如ConceptNet、ATOMIC。
- 领域知识图谱 (Domain-specific KGs):表示特定领域的知识,如医学领域的UMLS、金融、生物等。这类KG规模较小但更精确可靠。
- 多模态知识图谱 (Multi-modal KGs):用多种模态(如图像、声音)表示事实,如IMGpedia、MMKG。
应用
LLMs和KGs已在多种现实世界应用中得到广泛应用。
| 名称 | 类别 | LLMs | KGs | 链接 |
|---|---|---|---|---|
| ChatGPT/GPT-4 | 聊天机器人 | ✓ | \(https://shorturl.at/cmsE0\) | |
| ERNIE 3.0 | 聊天机器人 | ✓ | ✓ | \(https://shorturl.at/sCLV9\) |
| Bard | 聊天机器人 | ✓ | ✓ | \(https://shorturl.at/pDLY6\) |
| Firefly | 图片编辑 | ✓ | \(https://shorturl.at/fkzJV\) | |
| AutoGPT | AI助手 | ✓ | \(https://shorturl.at/bkoSY\) | |
| Copilot | 编码助手 | ✓ | \(https://shorturl.at/lKLUV\) | |
| New Bing | 网页搜索 | ✓ | \(https://shorturl.at/bimps\) | |
| Shop.ai | 推荐系统 | ✓ | \(https://shorturl.at/alCY7\) | |
| Wikidata | 知识库 | ✓ | \(https://shorturl.at/lyMY5\) | |
| KO | 知识库 | ✓ | \(https://shorturl.at/sx238\) | |
| OpenBG | 推荐系统 | ✓ | \(https://shorturl.at/pDMV9\) | |
| Doctor.ai | 健康助手 | ✓ | ✓ | \(https://shorturl.at/dhlK0\) |
表I: 使用LLMs和KGs的代表性应用。
路线图与分类
本节提出了一个统一LLMs和KGs的明确路线图,并对相关研究进行分类。
路线图
本文提出的路线图确定了三个统一LLMs和KGs的框架。
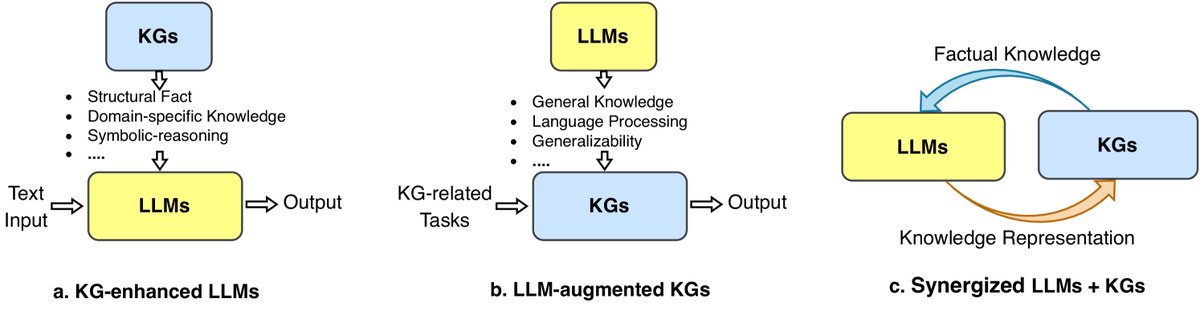
图6: 统一KG和LLM的通用路线图。(a) KG增强的LLMs。(b) LLM增强的KGs。(c) 协同的LLMs + KGs。
-
KG增强的LLMs (KG-enhanced LLMs):针对LLMs存在幻觉、缺乏可解释性的问题,利用KGs来增强LLMs。KGs中明确的结构化知识可以在预训练阶段注入LLM,或在推理阶段作为外部知识源,以提升LLMs的知识感知能力和可解释性。
-
LLM增强的KGs (LLM-augmented KGs):针对KGs存在不完整、构建困难等问题,利用LLMs强大的泛化能力来解决KG相关任务。LLMs可以作为文本编码器来丰富KG表示,或用于从原始语料中抽取实体关系以构建KG。
-
协同的LLMs + KGs (Synergized LLMs + KGs):这是一个统一框架,旨在让LLMs和KGs相互促进、协同工作。
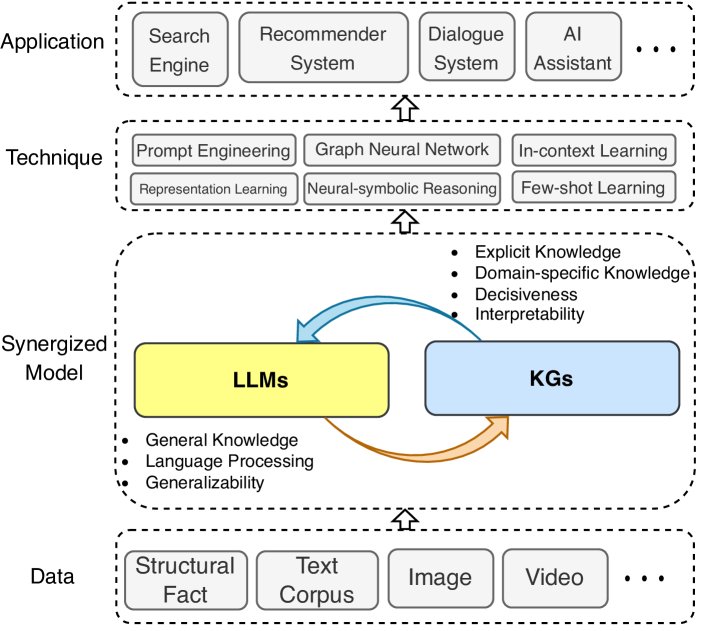
图7: 协同的LLMs + KGs的通用框架,包含四层:1) 数据层,2) 协同模型层,3) 技术层,4) 应用层。
该协同框架包含四层:
- 数据层 (Data):LLMs处理文本数据,KGs处理结构化数据,并可扩展至多模态数据。
- 协同模型层 (Synergized Model):LLMs和KGs在此层相互协同以提升能力。
- 技术层 (Technique):整合LLMs和KGs的相关技术以进一步提升性能。
- 应用层 (Application):将整合后的模型应用于搜索引擎、推荐系统、AI助手等现实世界应用。
分类体系
为了更好地理解统一LLMs和KGs的研究,本文对每个框架提供了细粒度的分类。
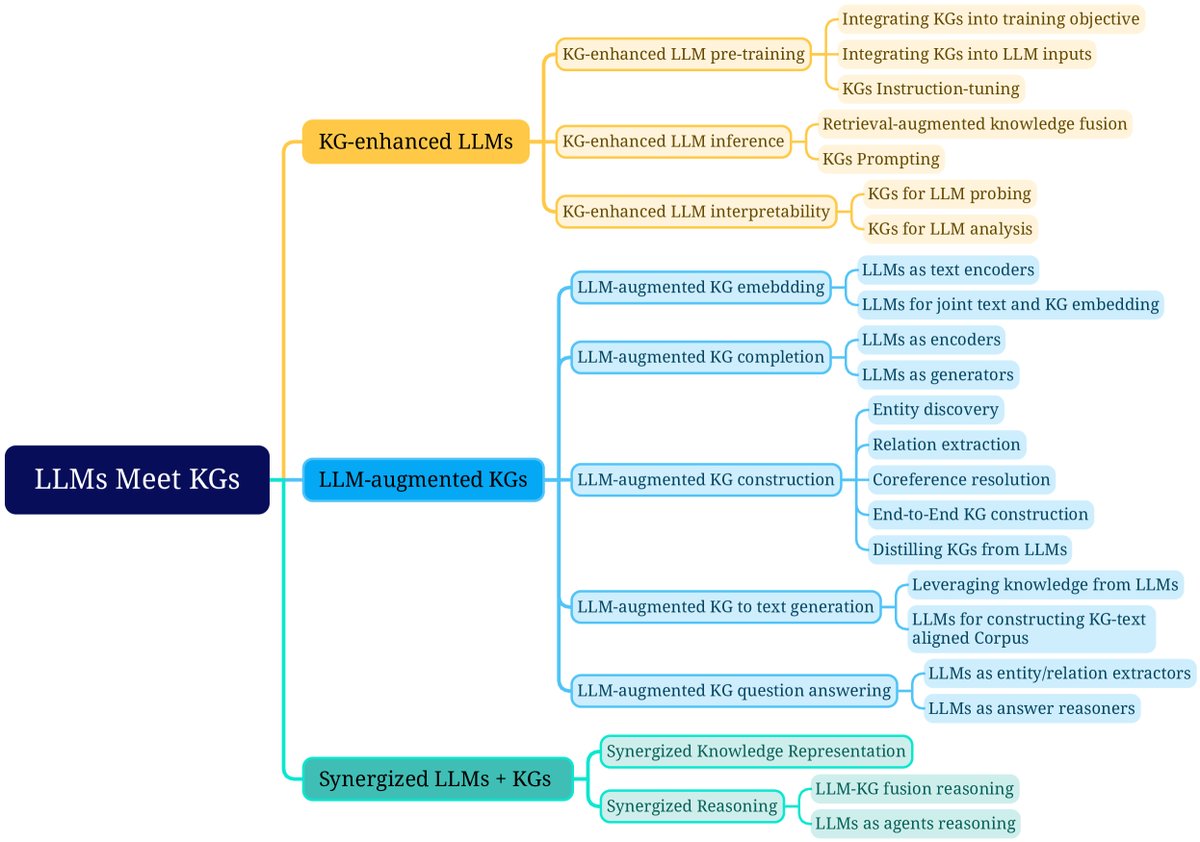
图8: 统一LLMs与KGs研究的细粒度分类。
KG增强的LLMs
该框架下的研究被分为三类:
- KG增强的LLM预训练:在预训练阶段应用KGs,提升LLMs的知识表达能力。
- KG增强的LLM推理:在推理阶段利用KGs,使LLMs能访问最新知识而无需重新训练。
- KG增强的LLM可解释性:利用KGs来理解LLMs学到的知识,并解释其推理过程。
LLM增强的KGs
该框架下的研究根据任务类型分为五类:
- LLM增强的KG嵌入:应用LLMs通过编码文本描述来丰富KG的表示。
- LLM增强的KG补全:利用LLMs编码文本或生成事实以提升KG补全性能。
- LLM增强的KG构建:应用LLMs处理实体发现、关系抽取等任务以构建KG。
- LLM增强的图到文本生成:利用LLMs生成描述KG事实的自然语言文本。
- LLM增强的KG问答:利用LLMs连接自然语言问题与KG中的答案。
协同的LLMs + KGs
本文从知识表示和推理两个角度回顾了协同LLMs + KGs的最新尝试。
知识图谱增强的大语言模型
为解决LLMs缺乏事实知识和易产生事实错误的缺点,研究者提出整合KGs来增强LLMs。下表总结了典型的KG增强LLM方法。
| 任务 | 方法 | 年份 | KG类型 | 技术 |
|---|---|---|---|---|
| KG增强的LLM预训练 | ERNIE [35] | 2019 | E | 整合KG到训练目标 |
| GLM [102] | 2020 | C | 整合KG到训练目标 | |
| Ebert [103] | 2020 | D | 整合KG到训练目标 | |
| KEPLER [40] | 2021 | E | 整合KG到训练目标 | |
| WKLM [106] | 2020 | E | 整合KG到训练目标 | |
| K-BERT [36] | 2020 | E + D | 整合KG到语言模型输入 | |
| CoLAKE [107] | 2020 | E | 整合KG到语言模型输入 | |
| ERNIE3.0 [101] | 2021 | E + D | 整合KG到语言模型输入 | |
| KP-PLM [109] | 2022 | E | KG指令微调 | |
| RoG [112] | 2023 | E | KG指令微调 | |
| KG增强的LLM推理 | KGLM [113] | 2019 | E | 检索增强的知识融合 |
| REALM [114] | 2020 | E | 检索增强的知识融合 | |
| RAG [92] | 2020 | E | 检索增强的知识融合 | |
| Li et al. [64] | 2023 | C | KG提示 | |
| Mindmap [65] | 2023 | E + D | KG提示 | |
| KG增强的LLM可解释性 | LAMA [14] | 2019 | E | 用于LLM探测的KG |
| LPAQA [118] | 2020 | E | 用于LLM探测的KG | |
| KagNet [38] | 2019 | C | 用于LLM分析的KG | |
| knowledge-neurons [39] | 2021 | E | 用于LLM分析的KG |
表II: KG增强的LLM方法总结。E: 百科知识图谱, C: 常识知识图谱, D: 领域知识图谱。
KG增强的LLM预训练
将KG融入LLM预训练的方法主要有三类:
1. 将KGs整合到训练目标中
这类研究着重设计知识感知的训练目标。
- 基于实体设计目标:ERNIE 提出文本-知识对齐的训练目标,让模型学习文本Token和KG实体之间的对齐关系。KEPLER 则将知识图谱嵌入的目标和掩码语言模型的目标结合在一个共享编码器中进行训练。WKLM 通过替换文本中的实体并让模型判断是否被替换,来注入知识。
- 基于图结构设计目标:GLM 利用KG的图结构为实体分配不同的掩码概率,距离近的实体有更高的概率被遮蔽。
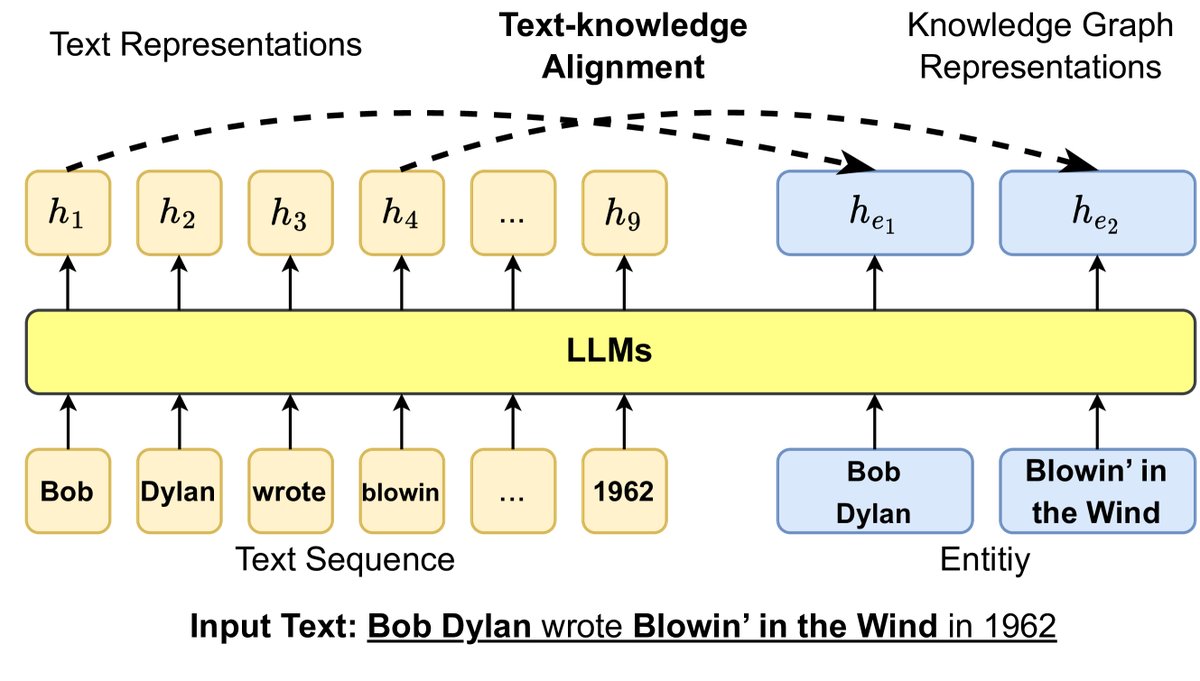
图9: 通过文本-知识对齐损失将KG信息注入LLM训练目标,其中 $h$ 表示LLM生成的隐藏表示。
2. 将KGs整合到LLM输入中
这类研究将相关的知识子图引入LLM的输入。
- 避免知识噪声:直接将KG三元组序列化并与句子拼接(如ERNIE 3.0)可能导致“知识噪声”。为解决此问题,K-BERT 设计了一个“可见矩阵”,使得句子中的Token只能看到彼此,而知识实体可以额外看到三元组信息。CoLAKE 则构建了一个统一的词-知识图,将文本Token和KG实体节点连接起来。
- 关注长尾实体:DkLLM 关注低频和长尾实体,用伪Token嵌入替换这些实体作为LLM的新输入。
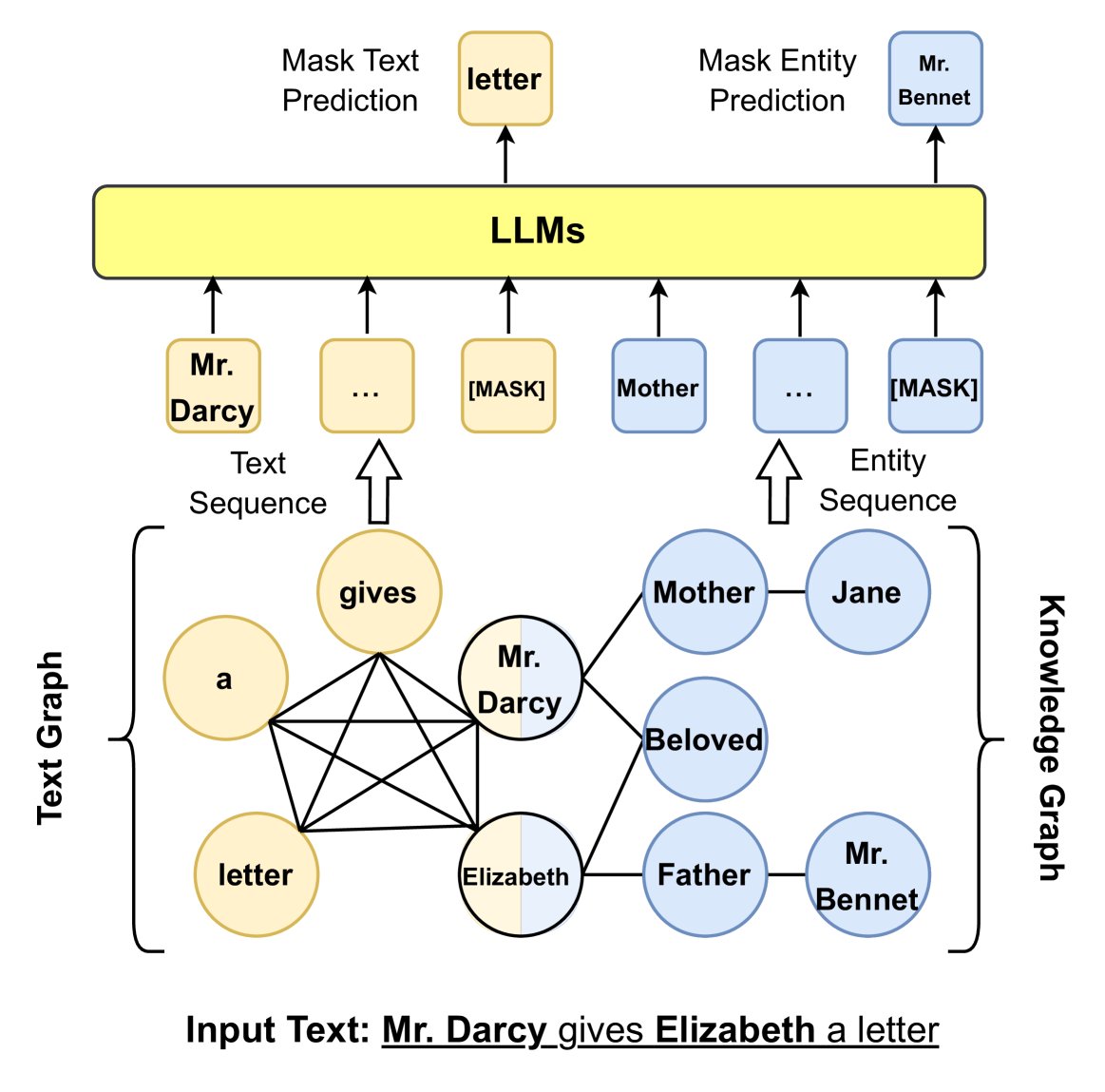
图10: 利用图结构将KG信息注入LLM输入。
3. KGs指令微调 (KGs Instruction-tuning)
该方法旨在微调LLMs,使其能更好地理解KG结构并遵循指令。它使用KG中的事实和结构来创建指令微调数据集。例如,KP-PLM 设计模板将图结构转换为自然语言文本,并以此微调LLM。RoG 则微调LLM以生成基于KG的关系路径作为规划,引导模型进行忠实的推理。
KG增强的LLM推理
预训练方法无法在不重新训练模型的情况下更新知识。因此,研究人员开发了在推理时注入知识的方法,特别是在需要最新知识的问答(QA)任务中。
1. 检索增强的知识融合
该方法的核心思想是从大型语料库中检索相关知识,然后将其融合到LLM中。
- RAG 模型在生成答案前,首先从非参数化的知识库中检索相关文档,然后将这些文档作为额外上下文输入到参数化的Seq2Seq LLM中。
- REALM 在预训练阶段就集成了一个知识检索器,可以在预训练和微调时从大型语料库中检索和关注文档。
- KGLM 则根据当前上下文从KG中选择事实来生成事实性句子。
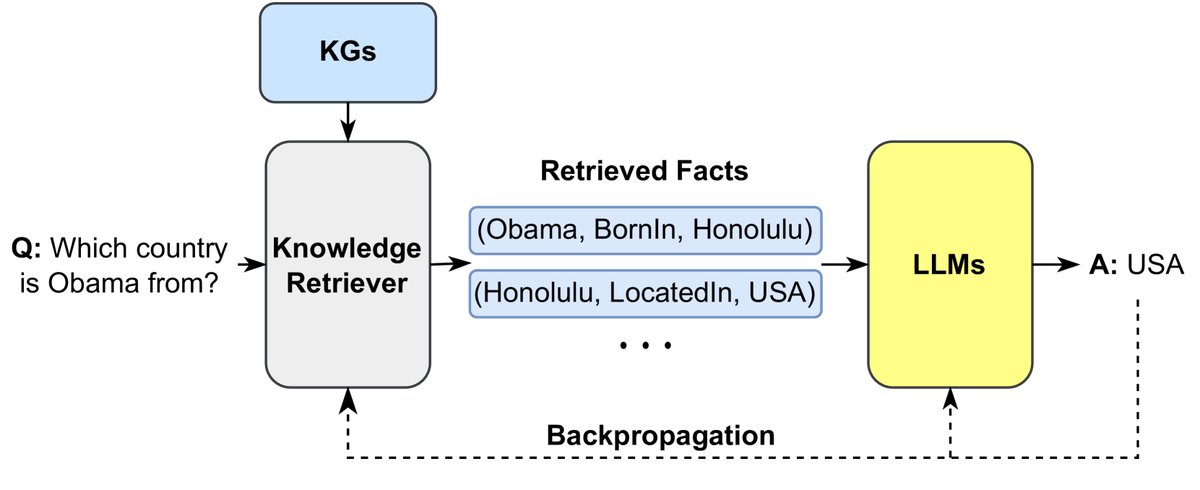
图11: 检索外部知识以增强LLM的生成过程。
2. KGs提示 (KGs Prompting)
该方法旨在设计精巧的提示,将结构化的KGs转换为文本序列,作为LLM的上下文。
- Li等人使用预定义模板将每个三元组转换为短句。
- Mindmap 设计了一种将图结构转换为思维导图(mind map)的提示,使LLM能够整合KG中的事实和其自身的隐式知识进行推理。
- CoK (Chain-of-Knowledge) 提出一种知识链提示,利用一系列三元组引导LLM逐步推理,最终得出答案。
预训练与推理的比较
- KG增强的LLM预训练:能让知识表示与语言上下文深度对齐,使LLM从头开始学习利用知识,在知识密集型任务中通常能达到最优性能。但缺点是知识更新成本高,无法处理动态变化的或未见过的新知识。
- KG增强的LLM推理:通过改变推理输入即可轻松更新知识,能更好地处理新知识和新领域。但缺点是LLM本身可能未经过充分训练来有效利用这些临时注入的知识,可能导致次优性能。
选择建议:对于处理时间不敏感的知识(如常识、推理),应考虑预训练方法。对于需要处理频繁更新的开放域知识,推理时增强的方法更为合适。
KG增强的LLM可解释性
尽管LLMs取得了巨大成功,但其黑箱特性和缺乏可解释性仍饱受诟病。KGs因其结构化和可解释的特性,被用来提升LLMs的可解释性。这主要分为两类:
1. 用于LLM探测的KGs (KGs for LLM Probing)
LLM探测旨在理解存储在LLMs内部的知识。LLMs通过在大型语料库上训练来隐式地存储知识,但很难确切知道它们存储了什么,并且它们还存在“幻觉”问题。
图12: 使用知识图谱进行语言模型探测的通用框架。
LAMA 是第一个利用KGs探测LLM知识的工作。如图12所示,LAMA首先通过预定义的提示模板将KG中的事实转换为“完形填空”式的句子(例如,将三元组 \((Dante, born in, Florence)\) 转换为句子 “Dante was born in [MASK]”),然后让LLM预测被遮蔽的实体。通过比较LLM的预测结果与KG中的真实答案,可以评估LLM掌握事实知识的程度。