Unifying Tree Search Algorithm and Reward Design for LLM Reasoning: A Survey
-
ArXiv URL: http://arxiv.org/abs/2510.09988v1
-
作者: Siqi Sun; Chenyu You; Xiang Zhang; Wanli Ouyang; Sheng Xu; Jiaqi Wei; Juntai Cao; Wenxuan Huang; Muhammad Abdul-Mageed; Zhangyang Gao
-
发布机构: Fudan University; Stony Brook University; The Chinese University of Hong Kong; University of British Columbia; Zhejiang University
引言
随着大型语言模型 (LLM) 的扩展定律进入回报递减的阶段,研究前沿正从数据和参数的暴力增长转向算法效率和新的推理形式。在此背景下,两个相互关联的范式成为核心:深思熟虑的推理时搜索 (deliberative Test-Time Search, TTS),即在推理时分配自适应的辅助计算来解决难题;以及自我提升 (Self-Improvement),即模型通过高质量的推理轨迹构建和精炼自身的训练信号。
树搜索 (Tree search) 已成为连接 TTS 和自我提升的关键方法。它通过系统地探索和评估多个推理分支,超越了贪心、单路径解码(如标准思维链 CoT)的局限性,从而在复杂的多步推理任务中取得了显著的成效。同时,这些搜索机制也成为参数化自我提升的引擎,通过将搜索发现的最优推理轨迹提炼为合成训练数据,来微调基础模型或训练专门的奖励函数,从而实现持续改进的自进化循环。
然而,尽管在 TTS 和自我提升方面取得了快速进展,该领域仍然高度碎片化。多样化的搜索范式、不一致的符号表示和评估协议使得系统性比较和累积进步变得困难。特别是,作为指导搜索至关重要的奖励或价值估计 (reward or value estimation),其在瞬态的推理时搜索和持久的参数优化中扮演着根本不同的角色,但这一区别仍未明确。
为解决此问题,本文提出了一个统一的概念和数学框架,旨在阐明核心机制,并为跨 TTS 和自我提升范式比较方法建立严谨的基础。主要贡献包括:
- 统一框架:引入一个数学框架,通过搜索机制 (Search Mechanism)、奖励公式 (Reward Formulation) 和转移函数 (Transition Function) 这三个核心组件来解构和比较不同的树搜索算法。本文正式区分了用于 TTS 的瞬态启发式奖励 (Heuristic Reward) 和用于自我提升的持久学习目标奖励 (Learning-Target Reward)。
- 新颖的分类体系:提出了一个新颖的分类体系,沿三个正交轴组织现有算法:搜索机制、奖励/价值估计方法,以及总体的应用范式(测试时增强 vs. 自我提升)。
- 综合与展望:综合了两个范式的关键进展,指出了在扩展搜索复杂性和设计有效奖励信号方面的开放挑战,并为构建真正自进化、具备深思熟虑能力的 LLM 勾勒了研究议程。
通用AI中的基础搜索范式
解决复杂问题可以被形式化为一个搜索任务:在状态-动作空间中寻找从初始状态到目标状态的最优路径,该空间通常表示为树 $T_{Q}$。语言模型推理所隐含的状态空间不仅巨大,而且是组合爆炸、高维度且具有语义结构的,使得穷举搜索在计算上不可行。本节回顾了三种基础的树搜索范式——无信息搜索、有信息搜索和蒙特卡洛树搜索——为理解它们在LLM推理中的现代应用奠定概念基础。
无信息搜索:盲目探索
传统搜索算法,如广度优先搜索 (Breadth-First Search, BFS)、深度优先搜索 (Depth-First Search, DFS) 和统一成本搜索 (Uniform Cost Search, UCS),在对目标位置知之甚少的情况下运行。这些算法仅依赖于问题的基本定义(可用动作、成本、目标识别标准)来系统地探索搜索空间。
无信息搜索的主要特点是,它只能通过探索顺序和累积成本来区分不同的解决方案路径。不同的算法提供不同的保证:BFS 找到步骤最短的路径,而 UCS 找到成本最低的路径。
有信息搜索:启发式引导的探索
与无信息搜索不同,有信息搜索 (informed search) 或启发式搜索 (heuristic search) 算法利用关于目标位置的额外知识。这种知识被编码在一个启发式函数 (heuristic function) $h(n)$ 中:
\[h(n) = \text{从节点 } n \text{ 到达目标状态的最廉价路径的估计非负成本}\]通过结合启发式函数,有信息搜索算法可以对哪些路径最有希望进行探索做出有根据的决策,从而可能减少寻找解决方案所需的计算资源。启发式函数的质量至关重要。如果一个启发式函数从不“高估”到目标的真实成本,则称其为可采纳的 (admissible)。
常见的有信息搜索算法包括贪婪最佳优先搜索 (Greedy Best-First Search)、A* 搜索、束搜索 (Beam Search) 等。A* 搜索在使用可采纳的启发式函数时,能保证找到最优解。然而,这些算法的有效性在很大程度上依赖于设计出高质量且与问题相关的启发式函数。
蒙特卡洛树搜索:从经验中学习
蒙特卡洛树搜索 (Monte Carlo Tree Search, MCTS) 是一种在线规划 (online planning)算法,最初用于计算机围棋领域,并因其在 AlphaGo 中的核心作用而闻名。用于 LLM 推理时搜索的 MCTS 是一种单玩家 (single-player) 的形式,它探索不同的动作序列,而不是模拟对抗性玩家。
MCTS 保留了四个核心阶段:选择 (selection)、扩展 (expansion)、模拟 (simulation) 和反向传播 (backpropagation)。在选择阶段,算法使用上置信界算法 (Upper Confidence Bound, UCB) 策略遍历树,该策略通过最大化以下公式来平衡探索与利用:
\[a^* = \arg\max_{a \in A(s)} \left[ Q(s,a) + c\sqrt{\frac{\ln N(s)}{N(s,a)}} \right]\]其中,$Q(s,a)$ 是在节点 $s$ 采取动作 $a$ 的预期未来奖励估计,$N(s)$ 是节点 $s$ 的访问次数,$N(s,a)$ 是在节点 $s$ 选择动作 $a$ 的次数,$c$ 是探索常数。
与依赖预定义启发式的 A* 等算法不同,MCTS 通过经验(模拟/rollout)动态构建其评估函数。这使其特别适合 LLM 推理,因为在 LLM 推理中定义精确的启发式函数非常具有挑战性。
探索策略对比
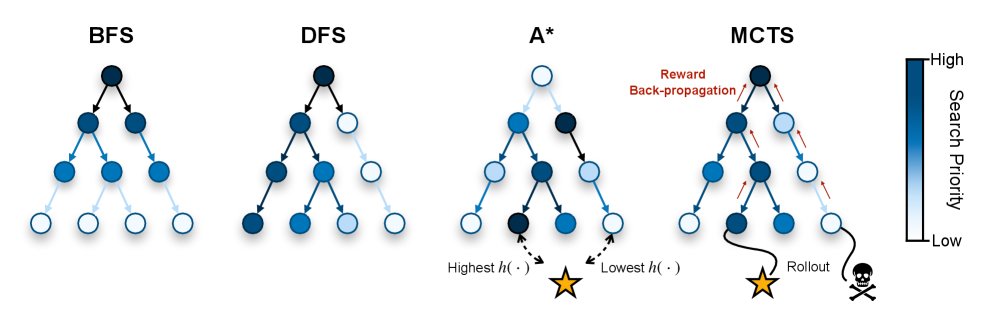
上图概念性地展示了这三种不同的探索策略:
- 无信息搜索(如BFS/DFS)由严格的、拓扑驱动的扩展规则控制。
- 有信息搜索(如A*)通过一个启发式函数 $h(\cdot)$ 引入了目标导向性,使其能够专注于有希望的区域。
- MCTS 用一个通过统计采样动态学习的价值函数取代了静态启发式。这种自适应、自我修正的机制使其能够在不需要先验领域知识的情况下,将计算资源集中在最有希望的搜索空间区域。这使其成为导航 LLM 广阔且定义不明确的推理空间的首选搜索范式。
通过搜索实现测试时扩展 (Test-Time Scaling)
随着模型参数和训练数据扩展带来的收益递减,一个新前沿已经出现:测试时扩展 (Test-Time Scaling, TTS)。该范式研究如何在推理期间优化分配计算资源,以增强模型的有效推理能力。与通过将知识编码到模型权重中来优化全局策略的训练时扩展不同,测试时扩展是为给定的问题实例 $Q$ 执行特定于实例的优化。
LLM扩展的两种优化:训练时 vs. 测试时
下图阐明了两种不同的模型性能提升方法,每种方法都在其独特的优化空间中由其独特的目标信号定义。
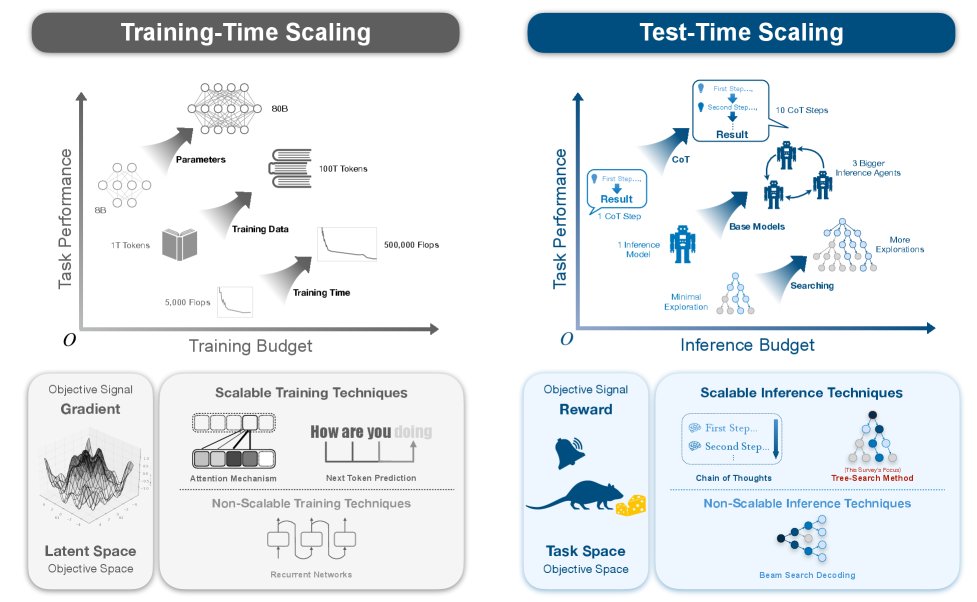
训练时扩展:潜在参数空间中的优化
训练的目标是学习一组参数 $\theta^*$,以最小化在数据分布 $\mathcal{D}$ 上的期望损失函数 $\mathcal{L}$:
\[\theta^* = \arg\min_{\theta \in \Theta} \mathbb{E}_{(i,o) \sim \mathcal{D}}[\mathcal{L}(f_{\theta}(i), o)],\]其中 $\Theta$ 是高维的参数空间 (parameter space)。此范式中的优化信号 (optimization signal) 是损失函数关于参数的梯度 $\nabla_{\theta}\mathcal{L}$。最终产物是一个静态的训练好的模型 $\pi$。
测试时扩展:任务定义的目标空间中的优化
给定一个固定的预训练模型 $\pi$,测试时扩展旨在为特定问题实例 $Q$ 找到一个最优的推理轨迹 $p^*$。这是一个在离散、结构化的解空间 (solution space) $\mathcal{P}(Q)$ 中进行的搜索。此处的优化信号是一个评估轨迹质量的标量奖励 (reward) 或价值 (value)。推理时的优化问题是:
\[p^* = \arg\max_{p \in \mathcal{A}(\pi, Q, \mathcal{C}_{\text{infer}})} V(p),\]其中 $\mathcal{A}$ 是受推理计算预算 $\mathcal{C}_{\text{infer}}$ 约束的搜索算法,$V(p)$ 是评估最终轨迹的函数。像树搜索这样的可扩展推理技术,使用中间奖励 $r_s$ 或部分轨迹价值 $v_i$ 来动态分配计算资源。
在目标空间中实施搜索
从潜在空间中的梯度到目标空间中的奖励,这一概念转变为优化算法带来了根本性的变化。测试时扩展通过能够导航复杂、不可微解空间的搜索过程来实现。
树搜索作为可扩展的推理优化器
树搜索方法,特别是 MCTS,为此类优化提供了一个有原则的框架。它们构建一个搜索树 $T_Q$,其中每个节点代表一个部分推理轨迹。在 LLM 搜索中,动作选择通常采用 AlphaGo 推广的 PUCT 风格规则,该规则结合了策略网络的先验知识。
\[a^* = \underset{a \in \mathcal{A}(s_i)}{\arg\max} \left( q_j + U(C_i, C_j) \right),\]其中,$U(C_i, C_j)$ 是不确定性奖励项,其公式为:
\[U(C_i, C_j) = c_{\text{exp}} \cdot \pi(a \mid p_i, Q) \cdot \frac{\sqrt{n_i}}{1+n_j}.\]这里,$n_i$ 和 $n_j$ 分别是父节点和子节点的访问次数,$\pi(a \mid p_i, Q)$ 是模型给出的先验概率。这种综合方法使得算法能够随着分配的推理计算预算有效扩展推理性能。
分解目标空间:提示空间与答案空间
测试时搜索运行其上的任务定义目标空间,可以被有效地分解为两个相关的层级:提示空间 (Prompt Space) 和答案空间 (Answer Space)。
提示空间 ($\mathcal{P}$): 搜索算法
提示空间 $\mathcal{P}$ 包含了 LLM 为解决问题可以采用的所有可能的推理结构或“步骤模板”。选择一个模板 $p \in \mathcal{P}$ 本质上等同于选择一个“算法”。这个选择至关重要,因为它定义了模型通过自回归生成所模拟的计算图。选择一个次优的模板可能会使搜索变得低效甚至不可行。
答案空间 ($\mathcal{S}$): 搜索解
对于任意给定的提示模板 $p$,都存在一个相应的答案空间 $\mathcal{S}_p$,它包含遵循该模板结构可以生成的所有可能的推理轨迹。一个有效的模板 $p^*$ 会极大地剪枝答案空间,简化通往正确解的路径。当代许多测试时计算方法主要在这一层级操作,它们通常固定一个启发式定义的提示模板(例如,“一步一步思考”),然后在此模板产生的答案空间 $\mathcal{S}_p$ 中进行探索。
测试时搜索的统一视图
一个全面的测试时搜索框架必须考虑在这两个空间上的联合优化。最终目标是发现一个解轨迹 $s^*$,它能最大化价值函数 $V(\cdot)$:
\[s^* = \arg\max_{p \in \mathcal{P}, s \in \mathcal{S}_p} V(s)\]这揭示了当前研究的一个关键空白:虽然大量工作投入到在给定答案空间 $\mathcal{S}_p$ 内优化搜索算法,但对提示空间 $\mathcal{P}$ 的系统性探索仍然是一个巨大的开放挑战。
奖励:强化学习与搜索的统一信号
在高级AI系统中,奖励信号是指导行为的基本要素。然而,根据其目标的时间范围,它的作用可以分为两个不同但互补的功能:塑造持久的、长期的策略 (policy)(通过强化学习)或指导短暂的、短期的规划 (planning)(通过搜索)。
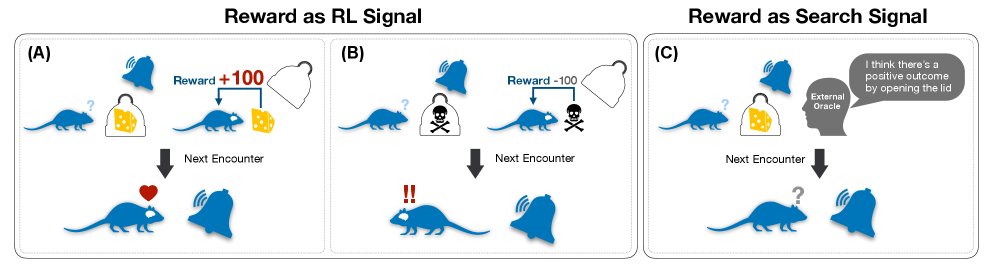
通过策略塑造进行强化学习:为泛化而内化奖励
当奖励信号与学习算法(如强化学习 RL)结合时,其目的是被内化 (internalized)。奖励的反馈直接修改模型权重,从而在其行为上产生持久的变化。这个过程类似于技能习得,经验被提炼成一个稳健、通用的策略。在现代的从人类反馈中进行强化学习 (RLHF) 中,这通常通过优化策略参数 $\theta$ 以最大化一个目标函数来实现,该目标函数平衡了累积奖励和对基础策略先验的遵守。
优化目标可以表示为:
\[\theta^* = \arg\max_{\theta} \mathbb{E}_{\tau \sim \pi_{\theta}} \left[ G(\tau) \right] - \lambda \int_{s \in \tau} D_{KL} \left( \pi_{\theta}(\cdot \mid s) \ \mid \pi_{\mathcal{P}}(\cdot \mid s) \right) ds\]其中 $D_{KL}$ 是 KL 散度。因为这种学习是永久性的,奖励函数被设计用于灌输通用原则 (general principles),例如逻辑一致性、真实性或鼓励循序渐进的推理。奖励在这里扮演着长期教师的角色。
通过深思熟虑的规划进行搜索:为具体性而外化奖励
相反,在测试时搜索期间,奖励信号充当一个外部化的启发式 (externalized heuristic)。它指导一个深思熟虑的过程(如 MCTS)来为单个、即时的任务导航解空间。奖励评估候选的动作序列(规划),使系统能够为手头的特定问题确定一个高质量的解决方案。
对于给定的任务和特定的外部奖励函数 $R_{\text{ext}}$,目标是找到一个最优规划 $p^*$,以最大化外部信号与由冻结模型提供的内部、路径依赖的启发式 $\mathcal{H}_{\theta}$ 的组合:
\[p^* = \arg\max_{p \in \mathcal{P}_{\text{plan}}} \left[ \sum_{t=0}^{T-1} \gamma^t R_{\text{ext}}(s_t, a_t) + \mathcal{H}_{\theta}(s_T, p) \right]\]这里的启发式 $\mathcal{H}_{\theta}$ 是最终状态 $s_T$ 和所走路径 $p$ 的一个复杂函数。从“规划即推理” (planning as inference) 的角度看,这可以被视为:
\[\mathcal{H}_{\theta}(s_T, p) = V_{\theta}(s_T) - \beta \cdot \log \left( \int_{\tilde{p} \in \mathcal{N}(p)} e^{-\mathcal{E}(\tilde{p})/\tau_c} d\tilde{p} \right)\]其中 $V_{\theta}(s_T)$ 是模型的内在价值估计,第二项则作为基于路径邻域“自由能”的复杂度惩罚。奖励在这里充当一个临时的、任务特定的向导。