VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool Use
-
ArXiv URL: http://arxiv.org/abs/2509.01055v1
-
作者: Zhuofeng Li; Kai Zou; Yi Lu; Zhiheng Lyu; Ping Nie; Hui Chen; Wenhu Chen; Chao Du; Tianyu Pang; Dongfu Jiang; 等12人
-
发布机构: HKUST; Independent; National University of Singapore; NetMind.AI; Sea AI Lab; Shanghai University; University of Toronto; University of Waterloo
TL;DR
本文提出了 VerlTool,一个统一、模块化且高效的框架,旨在解决智能体强化学习与工具使用 (Agentic Reinforcement Learning with Tool use, ARLT) 领域的系统碎片化、执行效率低下和扩展性差等核心问题。
关键定义
- 带可验证奖励的强化学习 (Reinforcement Learning with Verifiable Rewards, RLVR):一种优化语言模型的范式,通过一个预定义的、可验证的奖励函数 $R_{\phi}(x,y)$ 对模型单轮生成的答案 $y$ 进行评估和优化。
- 带工具使用的智能体强化学习 (Agentic Reinforcement Learning with Tool use, ARLT):本文对现有范式进行的扩展。在 ARLT 中,智能体与环境的交互是多轮次的,轨迹表示为 $\tau={a_0, o_0, \ldots, a_{n-1}, o_{n-1}, a_n}$,其中 $a_i$ 是智能体生成的动作,而 $o_i$ 是调用工具后返回的外部观测 (Observation Tokens)。这与仅接收标量奖励的传统智能体强化学习不同。
- 观测 Token (Observation Tokens, $o_i$):由外部工具(如代码解释器、搜索引擎)执行动作 $a_{i-1}$ 后返回的特定信息,以文本或图像等形式存在。这些 Token 对于模型来说是“离策略 (off-policy)”的,在策略优化时通常会被掩码处理,以避免训练不稳定。
- 异步 Rollout (Asynchronous Rollout):VerlTool 的一项核心系统设计。它允许每个智能体轨迹在生成一个动作后,立即独立地与工具服务器交互,而无需等待同一批次中的其他轨迹完成,从而消除了同步执行带来的等待“气泡”,显著提升了训练效率。
相关工作
当前,增强大型语言模型(LLM)能力的主流方法包括通过提示工程或指令微调来集成外部工具。然而,这些方法通常是静态的,缺乏根据工具执行的实时反馈进行动态调整和纠错的能力。
为了解决这一问题,研究界开始将强化学习与工具使用相结合,催生了我们称之为 ARLT 的新范式。该范式支持模型通过与环境的长期多轮互动来学习和优化其工具使用策略。
然而,现有的 ARLT 系统存在以下关键瓶颈:
- 系统碎片化:多数实现是为特定任务或工具(如代码执行、搜索)定制的,工具逻辑与训练代码紧密耦合,难以扩展和复用。
- 效率低下:普遍采用同步 Rollout 机制,即在批次中所有智能体都生成动作后,才统一与工具交互,导致大量 GPU 空闲时间。
- 扩展性有限:现有框架对多模态工具(如图像处理)的支持不足,增加了新工具的集成难度和开发开销。
本文旨在解决这些系统级挑战,通过推出一个通用、高效且易于扩展的 ARLT 训练框架来推动该领域的研究。
本文方法
ARLT 训练范式
本文将 ARLT 形式化为 RLVR 的多轮次扩展。在 RLVR 中,优化目标是最大化单轮生成 $y$ 的期望奖励,同时用 KL 散度惩罚与参考模型的偏离:
\[\max_{\pi_{\theta}}\mathbb{E}_{x\sim\mathcal{D},y\sim\pi_{\theta}(\cdot\mid x)}\left[R_{\phi}(x,y)\right]-\beta\,\mathbb{D}_{\text{KL}}\left[\pi_{\theta}(y\mid x)\,\ \mid \,\pi_{\text{ref}}(y\mid x)\right]\]在 ARLT 中,轨迹变为多轮的动作-观测序列 $\tau={a_0, o_0, \ldots, a_n}$。由于观测 Token $o_i$ 是外部工具生成的(离策略),在计算 GRPO 损失时需要将其掩码,仅对模型自己生成的动作 Token $a_j$ 进行优化:
\[J_{\text{GRPO-ARLT}}(\theta)=\frac{1}{G}\sum_{i=1}^{G}\frac{1}{\sum_{j=0}^{n} \mid a_{j} \mid }\sum_{j=0}^{n}\sum_{t=T_j}^{T_j+ \mid a_j \mid }\min\left[r_{i,t}(\theta)\cdot\hat{A}_{i,t},\,\text{clip}\left(r_{i,t}(\theta),1-\epsilon,1+\epsilon\right)\cdot\hat{A}_{i,t}\right]\]VerlTool 框架设计
为实现上述范式,VerlTool 采用了一个模块化和解耦的架构,主要由 Verl 工作流 (Verl Workflow) 和 工具服务器 (Tool Server) 两部分组成,通过统一的 API 进行通信。
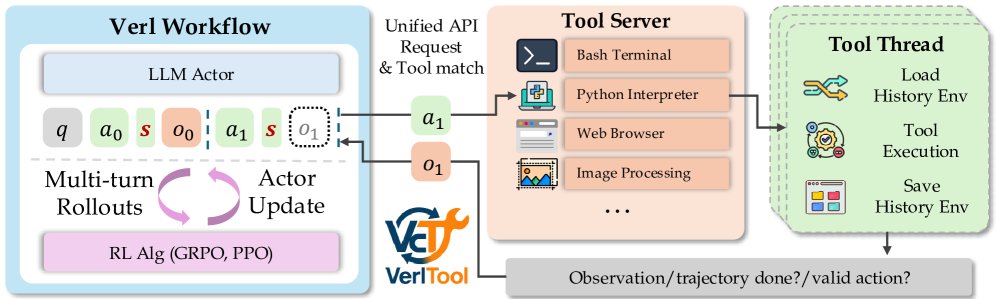
- Verl 工作流:负责所有强化学习相关的活动,如多轮 Rollout 和模型更新。
- 工具服务器:负责执行模型生成的工具调用请求,并返回观测结果。
这种设计将 RL 训练与工具执行完全分离,提高了系统的模块化程度和可维护性。
创新点
VerlTool 的设计包含四大核心创新:
1. 上游对齐与模块化
VerlTool 将 VeRL 框架作为一个子模块继承,确保了与上游更新的兼容性。这种设计分离了 RL 训练核心与智能体交互逻辑,简化了维护并加速了框架的迭代。
2. 统一的工具管理
框架提供了一个专用的工具服务器,并通过标准化的 API 支持各种工具。目前已支持的工具包括:
| 工具 | 描述 |
|---|---|
| Python Code Interpreter | 执行 Python 代码 |
| Search Faiss Search | 文档向量相似度搜索 |
| Globe Web Search API | 实时网页搜索与检索 |
| Image Image Processing | 图像缩放、视频帧选择 |
| Terminal Bash Terminal | 执行 Shell 命令 |
| Database SQL Executor | 数据库查询与数据管理 |
| Plug MCP Interface | 用于外部工具的模型上下文协议 |

VerlTool 采用了工具即插件(Tool-as-Plugin)的设计。开发者只需继承 \(BaseTool\) 类并实现几个简单的接口函数,就可以轻松地集成新工具,极大地降低了开发门槛。
3. 异步 Rollout 设计
这是 VerlTool 在效率上的关键突破。传统的同步模式下,系统需等待批次中所有轨迹都生成动作后才能统一调用工具,导致 GPU 闲置。VerlTool 的异步设计允许每个轨迹在生成动作后立即与工具服务器交互,实现了 RL 流程与工具执行的并行化。
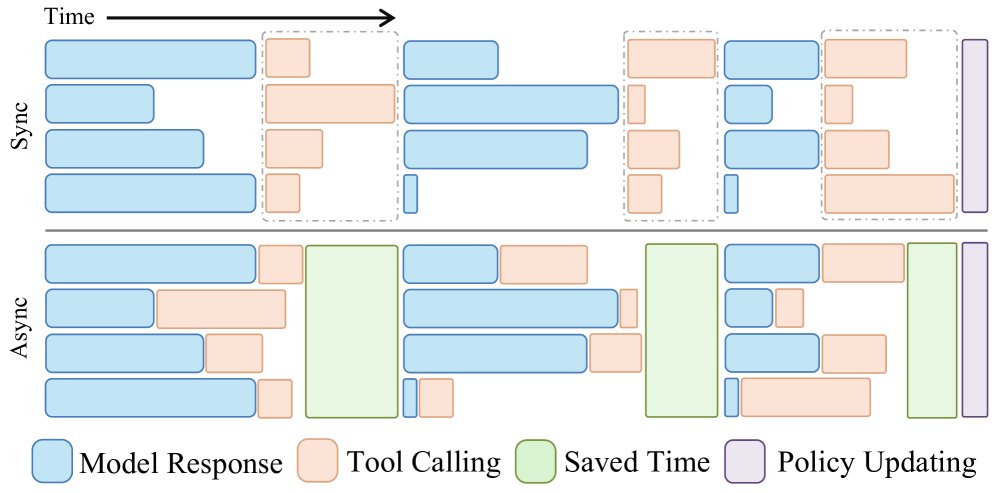
实验证明,这种设计显著减少了等待时间,带来了接近 2倍 的 Rollout 阶段加速。
| Math-TIR | SQL | DeepSearch | |
|---|---|---|---|
| 轮次 | 4 | 5 | 5 |
| 同步 (秒) | 87 | 111 | 193 |
| 异步 (秒) | 66 | 91 | 98 |
| 加速比 (×) | 1.32 | 1.22 | 1.97 |
4. 稳健的 Tokenization 策略
在多轮交互中,如何拼接模型生成的动作和工具返回的观测是一个实际挑战。分开 tokenize 再拼接,与先拼接字符串再统一 tokenize,可能会产生不同的 Token 序列,尤其是在边界处。

为保证训练的稳定性,VerlTool 采用先分别 Tokenize 再拼接 Token 序列的策略,确保了多轮 Rollout 过程中 Token 序列前缀的一致性。
实验结论
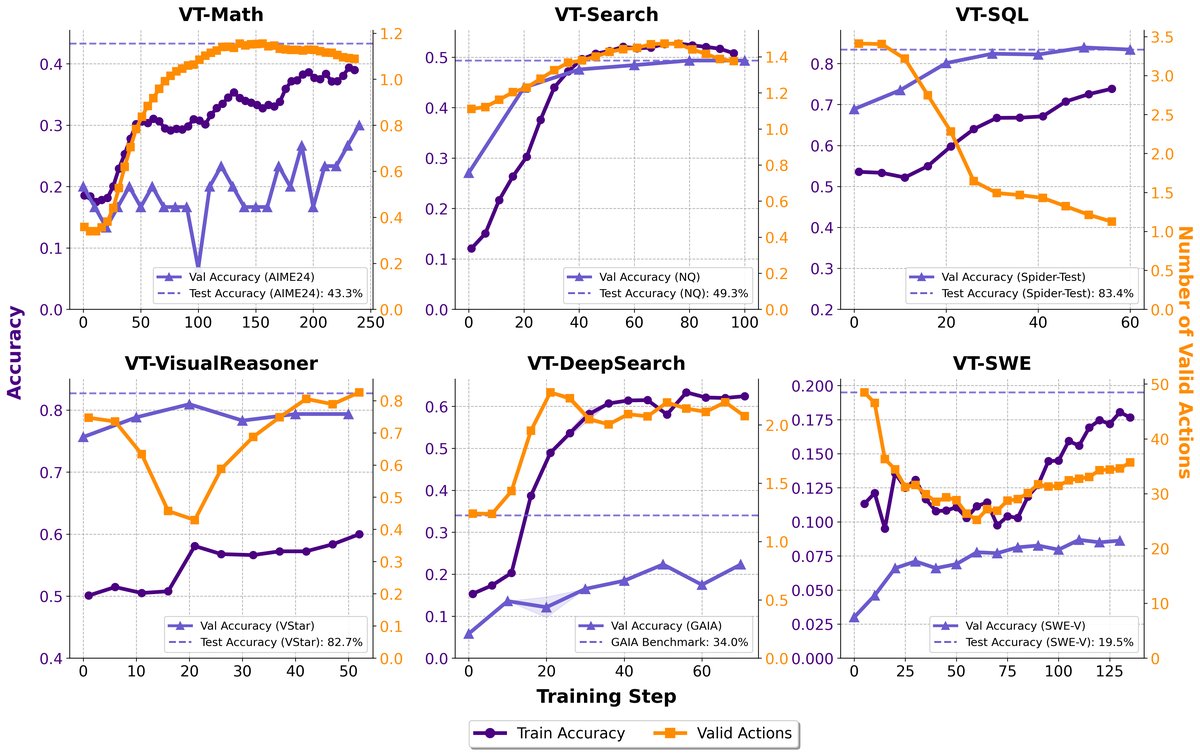
本文在数学推理、知识问答、SQL生成、视觉推理、网页搜索和软件工程六个 ARLT 任务上对 VerlTool 进行了全面评估。
关键实验结果
- 性能具有竞争力:使用 VerlTool 训练的模型在六个任务上均达到或超过了专门为该任务设计的基线系统。例如,在知识问答任务上,VT-Search 模型的平均分达到_45.9%,优于 Search-R1 的_35.0%;在数学任务上,VT-Math-7B 达到_62.2%_的平均分,同样具有竞争力。
| VT-Search 结果 (7B 模型) | NQ† | TriviaQA⋆ | PopQA⋆ | HotpotQA† | 2wiki⋆ | Musique⋆ | Bamboogle⋆ | 平均分 |
|---|---|---|---|---|---|---|---|---|
| Search-R1-base (GRPO) | 39.5 | 56.0 | 38.8 | 32.6 | 29.7 | 12.5 | 36.0 | 35.0 |
| VT-Search-base (GRPO) | 49.3 | 66.2 | 50.2 | 44.8 | 45.3 | 19.3 | 46.4 | 45.9 |
| VT-Math 结果 (7B 模型) | GSM8K | MATH 500 | Minerva Math | Olympiad Bench | AIME24 | AMC23 | 平均分 |
|---|---|---|---|---|---|---|---|
| ToRL-7B | 92.7 | 82.2 | 33.5 | 49.9 | 43.3 | 65.0 | 61.1 |
| VT-Math-base (DAPO) | 92.1 | 82.8 | 34.9 | 51.6 | 36.7 | 75.0 | 62.2 |
- 广泛支持多模态工具:实验成功验证了框架对文本、视觉、系统级工具的无缝集成能力。例如,VT-VisualReasoner 智能体能够在多轮交互中动态地处理和操作图像,完成了现有单模态框架无法支持的复杂视觉推理任务。
| VT-VisualReasoner 结果 | V* Bench |
|---|---|
| Pixel-Reasoner-7B | 84.3 |
| VT-VisualReasoner (GRPO-Complex) | 82.7 |
- 展现出工具使用的动态性与智能体能力:
- 学习策略随任务变化:在 VT-SQL 任务中,随着训练进行,模型学会了减少不必要的 SQL 执行器调用(因为结果可预测);而在 VT-DeepSearch 任务中,工具使用频率显著增加,因为解决问题高度依赖于搜索获取的信息。这表明智能体能根据工具的内在价值学习不同的使用策略。
- 涌现出高级能力:训练后的模型展现出自我纠正、迭代优化和战略性工具选择等复杂行为,证明了 ARLT 能够培养出超越简单工具调用的、真正的智能体解决问题的能力。
总结
VerlTool 作为一个可扩展、高效且统一的训练基础设施,成功解决了现有 ARLT 系统在开发和应用中的痛点。它通过系统性的设计,为研究和部署具备工具使用能力的大型语言模型智能体提供了坚实的基础,有望推动 ARLT 领域未来的发展。