VibeVoice Technical Report
-
ArXiv URL: http://arxiv.org/abs/2508.19205v1
-
作者: Weijiang Xu; Yutao Sun; Yan Xia; Yaoyao Chang; Hangbo Bao; Furu Wei; Li Dong; Shaohan Huang; Wenhui Wang; Zhiliang Peng; 等3人
-
发布机构: Microsoft Research
TL;DR
本文提出了一种名为 VibeVoice 的新模型,它通过一个创新的、具有超高压缩率的连续语音tokenizer和一个基于大型语言模型的下一token扩散框架,实现了长达90分钟、多达4人的高质量长篇对话语音合成。
关键定义
-
VibeVoice: 一个为生成长篇、多说话人语音而设计的创新框架。其核心是利用大型语言模型(Large Language Model, LLM)作为序列处理器,结合一个高效的语音tokenizer和一个token级的扩散解码头,实现了端到端的语音生成。
- 连续语音 Tokenizer (Continuous Speech Tokenizer): 本文提出的一个关键组件,用于将语音信号编码为连续的latent vectors。它包含两个部分:
- 声学 Tokenizer (Acoustic Tokenizer): 基于变分自编码器(Variational Autoencoder, VAE)的$\sigma$-VAE变体,将24kHz的音频以3200倍的压缩率编码为7.5 Hz的低帧率声学特征,旨在高保真地重建音频。
- 语义 Tokenizer (Semantic Tokenizer): 采用与声学编码器类似的层次化结构,但通过自动语音识别(Automatic Speech Recognition, ASR)任务进行训练,旨在提取与文本内容对齐的语义特征。
- 下一Token扩散 (Next-Token Diffusion): VibeVoice的生成机制。模型以自回归的方式运行,LLM在每个时间步预测一个隐藏状态 $h_i$,该状态随后引导一个轻量级的扩散头(Diffusion Head)通过迭代去噪过程,从高斯噪声中生成对应的连续声学特征 $z_{a,i}$。
相关工作
当前的文本到语音(Text-to-Speech, TTS)技术在生成短时、单说话人的高保真语音方面取得了显著成功。然而,对于播客、多人有声书等长篇、多说话人对话音频的合成,仍存在巨大挑战。传统的做法是将单个句子分别合成后拼接,但这难以实现自然的轮流对话和符合上下文的韵律。
近年来,虽然出现了一些针对长对话语音生成的研究,但多数系统要么不开源,要么在生成长度、稳定性和音质方面仍有不足。
本文旨在解决的核心问题是:如何可扩展地、稳定地生成长达90分钟的高质量、多说话人对话音频,并捕捉对话中自然的“氛围感 (vibe)”。
本文方法
VibeVoice的核心是一个基于大型语言模型(LLM)的序列模型,它整合了特制的音频编码器和基于扩散的解码模块,以实现可扩展的高保真多说话人语音合成。整体推理架构如下图所示。
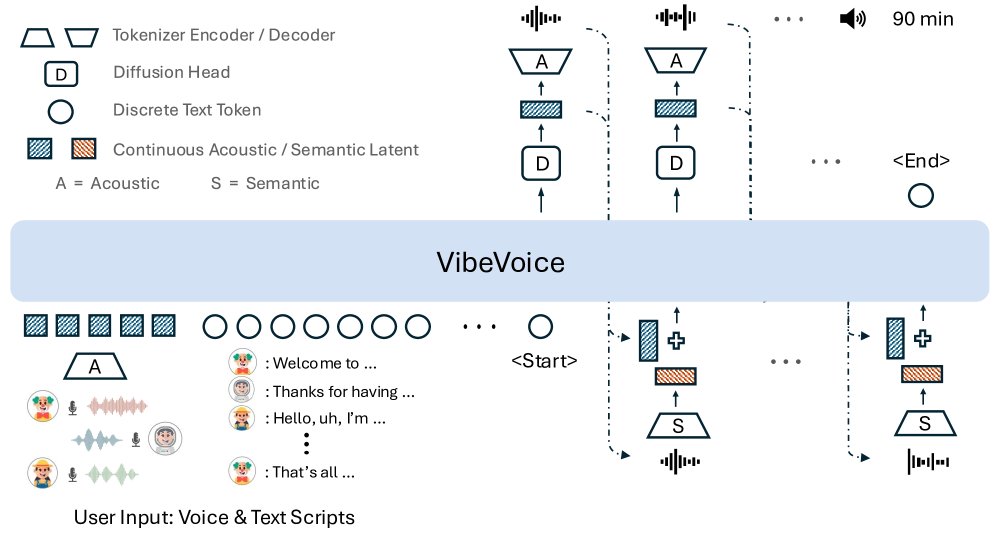 图 2: VibeVoice采用下一token扩散框架合成长篇多说话人音频。声音提示和文本脚本作为初始输入,LLM处理混合上下文特征,其隐藏状态引导一个token级扩散头(D)预测声学VAE特征,最后由声学解码器(A)恢复为语音。
图 2: VibeVoice采用下一token扩散框架合成长篇多说话人音频。声音提示和文本脚本作为初始输入,LLM处理混合上下文特征,其隐藏状态引导一个token级扩散头(D)预测声学VAE特征,最后由声学解码器(A)恢复为语音。
语音 Tokenizers
本文采用两个独立的tokenizer来分别学习声学和语义特征。
声学 Tokenizer 采用$\sigma$-VAE架构,以避免在自回归模型中常见的方差崩溃问题。其编码器将输入音频 $\mathbf{x}$ 映射为潜在分布的均值 $\mu$,而方差 $\sigma$ 则是一个预定义的分布,最终通过重参数化技巧采样得到潜向量 $\mathbf{z}$。该tokenizer具有镜像对称的编解码结构,通过7级修改过的Transformer模块(使用1D因果卷积替代自注意力)和6个下采样层,实现了从24kHz输入到7.5 Hz输出的3200倍超高压缩率。
语义 Tokenizer 的结构与声学编码器类似,但不包含VAE组件,其目标是提取确定性的、面向内容的特征。它通过一个ASR代理任务进行训练,使其输出的特征表示与文本语义对齐。
VibeVoice 模型
输入表示: 模型输入 $X$ 由用户指定的声音样本特征和文本脚本拼接而成,并用角色标识符 \(Speaker_k\) 分隔:
\[X=[\texttt{Speaker}_{1}:{\mathbf{z}}_{1},...,\texttt{Speaker}_{N}:{\mathbf{z}}_{N}]+[\texttt{Speaker}_{1}:T_{1},...,\texttt{Speaker}_{N}:T_{N}]\]其中,$\mathbf{z}_N$ 是声学潜向量表示,$T_N$ 是对应角色的文本脚本。在自回归生成过程中,已生成的语音段会被声学和语义tokenizer重新编码,作为下一时间步的输入。
创新点: VibeVoice的核心创新在于其高效的生成框架和超低帧率的语音表示。
-
超低帧率 (7.5 Hz) 连续声学Tokenizer: 这是实现长音频合成的关键。相比于常见的50Hz或100Hz,7.5Hz的帧率将生成一分钟音频所需的token数量减少了几个数量级。这极大地降低了LLM处理长序列的计算和内存压力,使得合成长达90分钟的音频成为可能。同时,该Tokenizer在极高的压缩率下依然保持了出色的重建质量。
-
下一Token扩散框架: 模型不直接预测离散的音频token,而是利用LLM的隐藏状态 $\mathbf{h}_i$ 去引导一个轻量级扩散头。这个扩散头通过多步去噪过程,从随机噪声中生成连续的声学VAE特征 $\mathbf{z}_{a,i}$。这种方式相比传统的自回归方法,能更好地保留声音的细节和丰富度,并提高了生成稳定性。
-
简化的端到端架构: VibeVoice摒弃了复杂的先验设计。它将声音提示(voice font)和文本脚本直接拼接后输入给LLM,由LLM统一处理上下文信息。这种端到端的模式简化了流程,并增强了模型的上下文理解能力。
实现细节: 模型的核心LLM采用了Qwen2.5的1.5B和7B版本。在训练期间,预训练的声学和语义tokenizer保持冻结,仅训练LLM和扩散头参数。训练中使用了课程学习策略,逐步将LLM处理的序列长度从4096增加到65536个token。
实验结论
VibeVoice 播客(长篇对话)
本文将VibeVoice与多个业界领先的对话语音生成系统进行了主观和客观评测。
| 模型 | 真实感 (MOS) | 丰富度 (MOS) | 偏好度 (MOS) | 平均 (MOS) | WER (Whisper) | WER (Nemo) | SIM-O |
|---|---|---|---|---|---|---|---|
| Nari Labs Dia | - | - | - | - | 11.96 | 10.79 | 0.541 |
| Mooncast | - | - | - | - | 2.81 | 3.29 | 0.562 |
| SesameAILabs-CSM | 2.89 ±1.15 | 3.03 ±1.11 | 2.75 ±1.08 | 2.89 ±1.12 | 2.66 | 3.05 | 0.685 |
| Higgs Audio V2 | 2.95 ±1.13 | 3.19 ±1.06 | 2.83 ±1.16 | 2.99 ±1.13 | 5.94 | 5.97 | 0.543 |
| Elevenlabs v3 alpha | 3.34 ±1.11 | 3.48 ±1.05 | 3.38 ±1.12 | 3.40 ±1.09 | 2.39 | 2.47 | 0.623 |
| Gemini 2.5 pro | 3.55 ±1.20 | 3.78 ±1.11 | 3.65 ±1.15 | 3.66 ±1.16 | 1.73 | 2.43 | - |
| VibeVoice-1.5B | 3.59 ±0.95 | 3.59 ±1.01 | 3.44 ±0.92 | 3.54 ±0.96 | 1.11 | 1.82 | 0.548 |
| VibeVoice-7B | 3.71 ±0.98 | 3.81 ±0.87 | 3.75 ±0.94 | 3.76 ±0.93 | 1.29 | 1.95 | 0.692 |
表 1: 人类主观与客观评测结果。主观指标与SIM-O越高越好,WER越低越好。
- 主观评测: 在真实感、丰富度和整体偏好度上,VibeVoice-7B模型全面超过了包括Gemini 2.5 Pro和Elevenlabs在内的所有竞品。
- 客观评测: 在词错误率(Word Error Rate, WER)方面,VibeVoice-1.5B表现最佳,证明其语音清晰度最高。在说话人相似度(Speaker Similarity, SIM)方面,VibeVoice-7B表现最佳,说明其音色模仿能力更强。
- 结论: 无论是主观听感还是客观指标,VibeVoice在长篇对话生成任务上均达到了SOTA水平。扩大模型规模(从1.5B到7B)显著提升了音质和音色相似度。
VibeVoice 短句
尽管VibeVoice主要为长篇语音设计,但在短句评测基准SEED上同样表现出强大的泛化能力,取得了与专门为短句设计的模型相竞争的性能,同时其解码步数远少于其他模型。
| 模型 | 帧率 (Hz) | test-zh CER(%) ↓ | test-zh SIM ↑ | test-en WER(%) ↓ | test-en SIM ↑ |
|---|---|---|---|---|---|
| Seed-TTS | - | 1.12 | 0.796 | 2.25 | 0.762 |
| Spark TTS | 50 | 1.20 | 0.672 | 1.98 | 0.584 |
| VibeVoice-1.5B | 7.5 | 1.16 | 0.744 | 3.04 | 0.689 |
表 2: SEED测试集上的部分结果。
Tokenizer 重建质量
| Tokenizer | Token 速率(Hz) | PESQ ↑ | STOI ↑ | UTMOS ↑ |
|---|---|---|---|---|
| Encodec (8q) | 600 | 2.72 | 0.939 | 3.04 |
| WavTokenizer (1q) | 75 | 2.373 | 0.914 | 4.049 |
| Ours (Acoustic) | 7.5 | 3.068 | 0.828 | 4.181 |
表 3: LibriTTS test-clean数据集上的部分语音tokenizer重建质量客观评测。
实验结果表明,本文提出的声学tokenizer在远低于其他模型的token速率(7.5 Hz)下,依然在PESQ和UTMOS(感知质量预测)等关键指标上取得了最佳性能。这验证了该tokenizer在实现极致压缩的同时,有效保留了音频高保真度的能力,是VibeVoice成功的基石。
总结
VibeVoice通过超低帧率的混合语音表征与端到端的下一token扩散框架相结合,显著推进了长篇对话语音合成技术的发展。它能够可扩展地生成长达90分钟、多达4位说话人的高品质音频,在主观听感和客观指标上均超越了现有SOTA系统。
局限性与风险:
- 语言限制:目前仅支持英语和中文。
- 非语音音频:模型只关注语音合成,不处理背景噪音、音乐等。
- 语音重叠:当前模型无法生成对话中的语音重叠部分。
- 滥用风险:高质量的合成语音可能被用于制作深度伪造(deepfakes)音频,从事欺诈或传播虚假信息。