VideoAgentTrek: Computer Use Pretraining from Unlabeled Videos
-
ArXiv URL: http://arxiv.org/abs/2510.19488v1
-
作者: Hongjin Su; Zekun Wang; Tao Yu; Binyuan Hui; Xinyuan Wang; Haoyuan Wu; Junda Chen; Jingren Zhou; Junli Wang; Jixuan Chen; 等14人
-
发布机构: Alibaba Group; The University of Hong Kong
TL;DR
本文提出了一种名为 VideoAgentTrek 的可扩展方法,通过一个逆动力学模块(VADM)从未经标注的公开屏幕录制视频中自动挖掘出结构化的训练数据,从而解决了训练计算机使用智能体(Agent)时对大规模手动标注数据的依赖问题。
关键定义
- VideoAgentTrek: 一个完整的、可扩展的自动化流程,旨在将无标签的屏幕录制视频转化为可用于训练计算机使用智能体的高质量数据。该流程包含三个主要阶段:视频收集与预处理、通过 VADM 模块提取结构化动作、以及利用所提取数据进行模型预训练和微调。
- VADM (VideoAgentTrek inverse Dynamics Module): VideoAgentTrek 的核心组件,一个逆动力学模块,负责从原始视频片段中恢复出结构化的动作信息。它包含两个关键部分:(1) 动作事件检测器,用于在视频中精准定位(精确到毫秒)各种 GUI 交互行为(如点击、输入)的起止时间点;(2) 动作参数化识别器,用于从已定位的视频片段中抽取出具体的动作参数(如点击的坐标 \((x,y)\)、输入的文本内容)。
- GUI-Filter: 一种轻量级的视频预处理工具。它基于 YOLOv8x 模型构建,通过检测视频帧中是否存在鼠标光标,来高效地过滤和保留仅包含图形用户界面(GUI)交互的视频片段,从而去除无关内容(如演示文稿、真人讲解)。
相关工作
当前,获取计算机使用智能体训练数据的方法主要有三种:
- 人工标注: 通过人工记录操作轨迹,能够生成高质量、高精度的标注数据,但成本极其高昂,难以规模化,且覆盖的应用场景有限。
- 程序化合成: 在模拟器或脚本化环境中自动生成大量交互数据,虽然规模大、参数精确,但往往缺乏真实世界UI的多样性和复杂性,与现实场景存在偏差。
- 网络挖掘: 从网络教程、RPA日志等资源中获取数据,覆盖面广、多样性好,但通常缺少精确的动作时间边界和结构化的动作参数,数据质量参差不齐。
研究领域的关键瓶颈在于,缺乏一种能够兼顾规模、多样性和质量的数据获取方法。本文旨在解决这一核心问题:如何将互联网上大量存在的、非结构化的屏幕录制视频,自动化地转化为可直接用于智能体训练的、带有精确参数的结构化交互轨迹,从而摆脱对昂贵人工标注的依赖。
本文方法
本文提出的 VideoAgentTrek 是一个三阶段的自动化流程,能将无标签的网络视频转化为结构化的智能体训练数据。
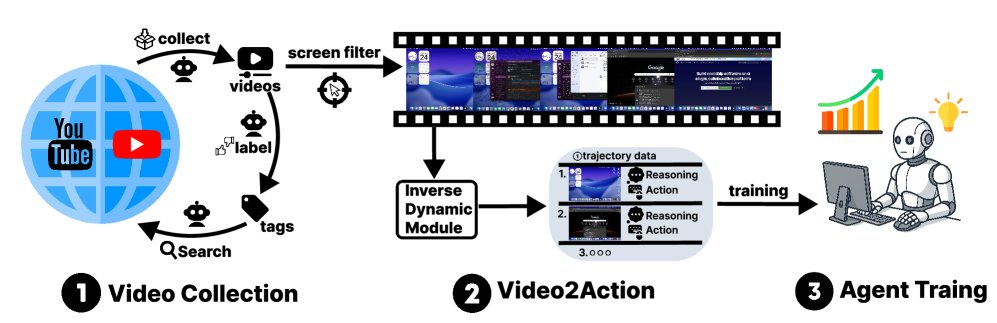 VideoAgentTrek 概览。(1) 视频收集与预处理: 爬取屏幕录制教程并通过 GUI-Filter 筛选出 GUI 操作片段。(2) VADM: 一个逆动力学模块,首先进行密集的动作事件检测以定位剪辑并分配动作类型,然后进行动作参数化(例如,点击坐标,输入的文本)以产生结构化的 $(\text{截图}, \text{动作}, \text{参数})$ 轨迹。(3) 模型预训练与微调: 使用挖掘出的轨迹对计算机使用智能体进行持续预训练和监督微调。
VideoAgentTrek 概览。(1) 视频收集与预处理: 爬取屏幕录制教程并通过 GUI-Filter 筛选出 GUI 操作片段。(2) VADM: 一个逆动力学模块,首先进行密集的动作事件检测以定位剪辑并分配动作类型,然后进行动作参数化(例如,点击坐标,输入的文本)以产生结构化的 $(\text{截图}, \text{动作}, \text{参数})$ 轨迹。(3) 模型预训练与微调: 使用挖掘出的轨迹对计算机使用智能体进行持续预训练和监督微调。
视频收集与预处理
视频采集
本文采用一种可扩展的视频收集策略。首先使用 “Excel 教程” 等种子关键词搜索视频,然后对高质量频道(样本通过率 $\geq$ 80%)下的所有视频进行整体收录,利用这些频道的标签和元数据进行迭代式发现。这种基于“频道一致性”的策略在少量人工监督下,高效地收集了约55,000个候选视频(约10,000小时)。
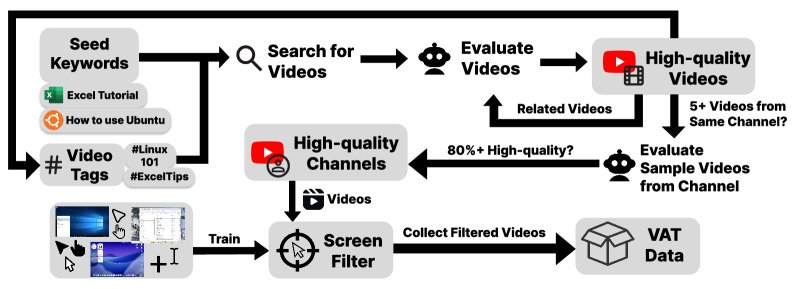 从种子关键词和标签出发,搜索和评估视频,扩展到相关视频和高质量频道(通过率$\geq$80%),并迭代收集包含GUI的视频用于VAT。
从种子关键词和标签出发,搜索和评估视频,扩展到相关视频和高质量频道(通过率$\geq$80%),并迭代收集包含GUI的视频用于VAT。
视频预处理
为了从候选视频中精确提取包含 GUI 交互的片段,本文开发了 \(GUI-Filter\) 模型。这是一个基于 YOLOv8x 的轻量级光标检测模型,能够过滤掉演示文稿等非交互内容。具体筛选标准为:连续6秒以上且至少80%的帧包含光标的片段被保留。最终,该工具从10,000小时的原始视频中成功提取了7,377小时的有效GUI交互录像。
数据分析
收集到的视频数据在分辨率(97%为720p或更高)和主题上都表现出高质量。通过对标题和描述的分析,视频内容主要为教程类(69.6%),覆盖了操作系统、专业软件、办公和日常应用等多个领域,其中操作系统(OS)相关内容占比最高(约36%),保证了数据的广度和实用性。
 领域分布图
领域分布图
VADM:逆动力学模块
VADM 是本文的技术核心,它模仿机器人领域的逆动力学思想,从观测(视频像素)中反推出执行的动作。该模块无需人工标注,即可将视频转化为结构化的 \((截图, 动作, 思考)\) 序列。
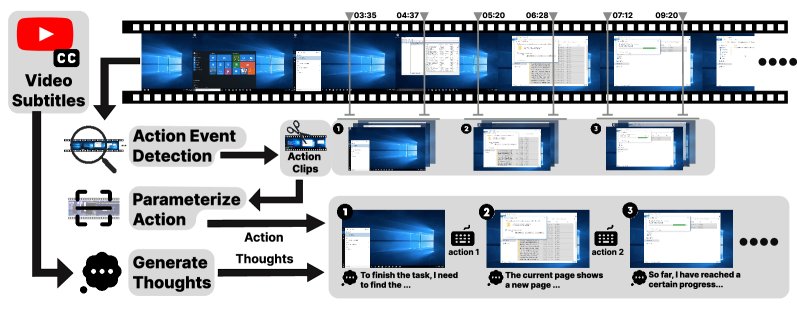 VADM 流程:给定一个屏幕录制视频(可选字幕),该模块 (1) 检测 GUI 动作事件并分割剪辑,(2) 参数化每个动作(类型和参数),以及 (3) 生成步骤级别的思考,最终产出可供训练的 {动作剪辑, 动作, 思考} 序列。
VADM 流程:给定一个屏幕录制视频(可选字幕),该模块 (1) 检测 GUI 动作事件并分割剪辑,(2) 参数化每个动作(类型和参数),以及 (3) 生成步骤级别的思考,最终产出可供训练的 {动作剪辑, 动作, 思考} 序列。
动作事件检测
此阶段的目标是在无标签视频 \(v\) 中进行密集的事件检测,输出一系列带有精确起止时间的动作集合 \(S={(a_k, t_k^s, t_k^e)}_k=1^K\)。
\[f_{\theta}(v) \rightarrow \mathcal{S}=\{(a_{k},t_{k}^{\mathrm{s}},t_{k}^{\mathrm{e}})\}_{k=1}^{K},\quad a_{k}\in\mathcal{A},\ 0\leq t_{k}^{\mathrm{s}}<t_{k}^{\mathrm{e}}\leq T.\]本文利用 OpenCUA 数据集自动生成带有时间戳的 GUI 事件作为监督数据,对 Qwen2.5-VL-7B-Instruct 模型进行全参数微调,使其能够直接从视频中预测出动作类型及其毫秒级的时间边界。
动作参数化
在检测到动作片段 $v_k=v[t_k^s:t_k^e]$ 后,此阶段的目标是识别出具体的动作参数 \(π_k\)。
\[h_{\phi}(v_{k}) \rightarrow (\hat{a}_{k},\pi_{k}).\]例如,对于点击动作,输出 \((click, (x,y))\);对于打字动作,输出 \((type, <content>)\)。同样地,本文利用 OpenCUA 的原始日志生成监督数据,对 Qwen2.5-VL 模型进行微调,使其能从视频片段中直接解码出动作类型和具体参数。
内心独白生成
为了让模型学习动作背后的意图,本文还为每个动作生成了一段简短的“内心独白” \(r_k\)。通过向 GPT-4.5 Medium 提供动作类型、参数、动作前后的屏幕截图以及相关的语音识别(ASR)文本等上下文信息,模型会生成一段描述意图和计划的文本。这使得最终的数据格式成为类似 ReAct 风格的 \((截图, 思考, 动作, 参数)\) 序列,有助于提升模型的规划和推理能力。
计算机使用模型预训练
本文采用一种两阶段训练策略来验证 VideoAgentTrek 数据的有效性。
数据准备
- VideoAgentTrek 数据: 将39,000个视频通过上述流程处理,生成了约152万个交互步骤(约260亿 tokens)。
- 人工标注数据: 整合了 OpenCUA 和 AGUVIS 等公开数据集中的人工标注轨迹,约80亿 tokens。
- GUI 定位数据: 引入了 OSWorld-G 数据集中的定位数据对,以增强模型对界面元素的感知能力,约10亿 tokens。
训练策略
- 第一阶段:持续预训练: 使用 VideoAgentTrek 生成的大规模、多样但可能含噪的数据,对 Qwen2.5-VL-7B 模型进行一轮预训练。此阶段的目标是让模型学习广泛的 GUI 交互模式和视觉基础。
- 第二阶段:监督微调 (SFT): 在一小部分高质量、人工标注的数据集上进行微调。此阶段的目标是磨练模型在具体任务上的策略执行能力和遵循指令的能力。
这种“先广泛学习,后精细打磨”的策略,旨在充分利用大规模视频数据的广度来构建稳健的底层能力,再利用高质量标注数据的精度来优化上层策略。
实验结论
本文在两个主流计算机使用智能体基准上验证了方法的有效性:OSWorld-Verified(在线真实环境)和 AgentNetBench(离线评估)。
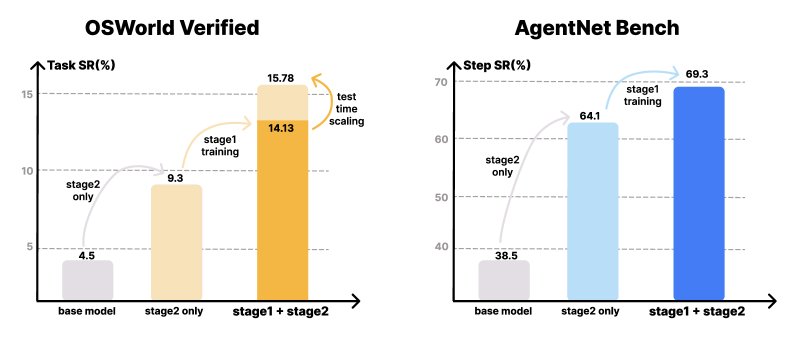 在 OSWorld-Verified 和 AgentNetBench 上的实验结果。VideoAgentTrek 相较于基线模型展现出显著提升,测试时扩展步数能带来额外性能增益。
在 OSWorld-Verified 和 AgentNetBench 上的实验结果。VideoAgentTrek 相较于基线模型展现出显著提升,测试时扩展步数能带来额外性能增益。
主要结果:
- 在线与离线性能显著提升: 在 AgentNetBench 上,加入视频预训练后,模型的单步成功率从基线的 64.1% 提升至 69.3%。在更具挑战性的在线环境 OSWorld-Verified 上,任务成功率从仅SFT的 9.3% 大幅提升至 15.8%(在50步预算下),相对提升了 70%。这证明了视频预训练带来的知识迁移是有效的,尤其是在需要应对真实世界视觉变化的在线环境中。
- 数据规模与性能成正比: 实验表明,随着预训练阶段使用的视频数据量从0%增加到100%,模型的最终性能在两个基准上都获得了持续提升,验证了 VideoAgentTrek 方法的可扩展性。
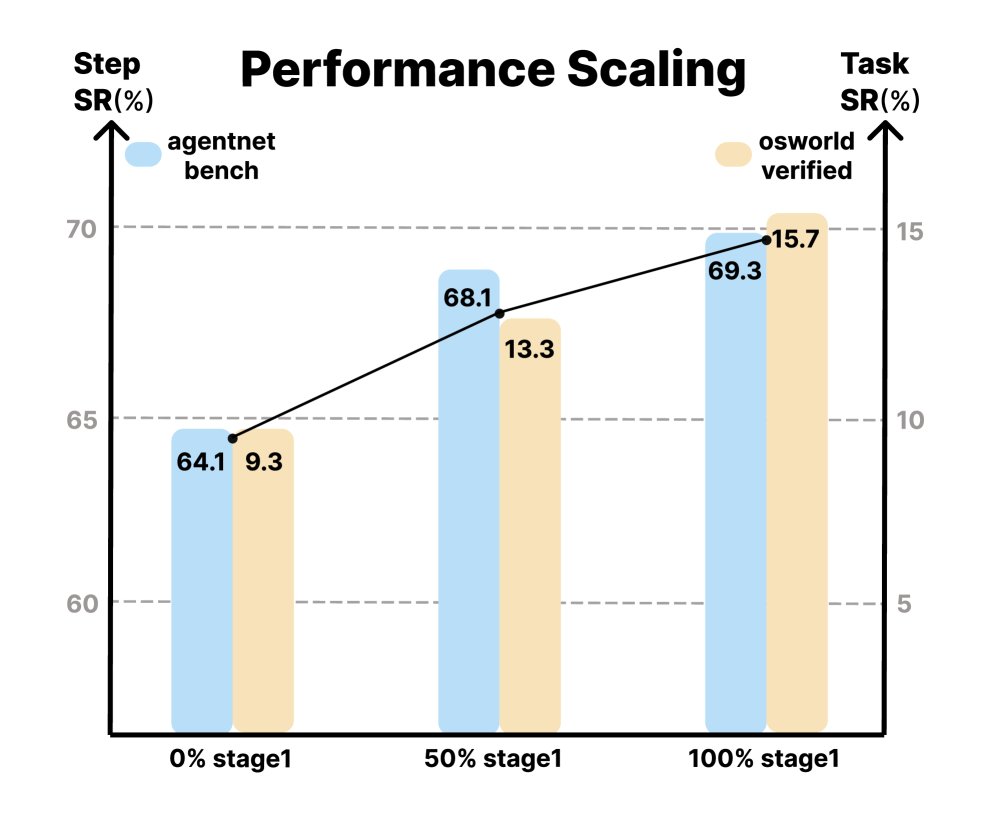 性能扩展图
性能扩展图
- 改善长时程规划能力: VideoAgentTrek 生成的轨迹平均长度为39.25步,远超现有数据集。这种长轨迹的预训练带来了显著优势:在 OSWorld-Verified 测试中,当允许的交互步数从20步增加到50步时,经过视频预训练的模型任务成功率从14.13%提升到15.78%,表现出有效的测试时扩展能力。相比之下,仅经过 SFT 训练的模型性能则停滞不前,表明其缺乏利用额外步骤进行探索和纠错的能力。
- VADM 模块性能可靠: VADM 的动作事件检测器在留出测试集上表现出色,整体精确率达到0.88,召回率为0.71,尤其对于点击、滚动等视觉特征明显的动作识别效果好。动作参数化模块虽然难以自动化评估,但通过人工盲审发现,其预测的参数在多数情况下是准确且可执行的,足以构建有效的训练轨迹。
| 动作事件检测器评估 (留出测试集) | ||
|---|---|---|
| 动作类型 | F1分数 | 精确率 |
| 点击 (Click) | 0.817 | 0.949 |
| 拖拽 (Drag) | 0.449 | 0.583 |
| 按压 (Press) | 0.449 | 0.596 |
| 滚动 (Scroll) | 0.840 | 0.985 |
| 输入 (Type) | 0.771 | 0.902 |
| Micro Avg. | 0.784 | 0.879 |
| 动作参数化评估 (人工盲审) | ||
|---|---|---|
| 动作类型 | 评估数量 | 正确率 |
| 点击 | 324 | 0.713 |
| 拖拽 | 22 | 0.366 |
| 按压 | 47 | 0.362 |
| 滚动 | 34 | 0.735 |
| 输入 | 73 | 0.671 |
最终结论: 本文的实验结果有力地证明,互联网上大量存在的被动屏幕录制视频可以被成功转化为高质量的监督信号,为训练更强大、更鲁棒的计算机使用智能体提供了一条可扩展且有效的路径,是昂贵人工标注的一种可行替代方案。