Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
-
ArXiv URL: http://arxiv.org/abs/2401.09417v3
-
作者: Xinggang Wang; Wenyu Liu; Bencheng Liao; Xinlong Wang; Lianghui Zhu; Qian Zhang
-
发布机构: Beijing Academy of Artificial Intelligence; Horizon Robotics; Huazhong University of Science & Technology
TL;DR
本文提出了一种名为 Vision Mamba (Vim) 的通用视觉骨干网络,它通过将双向状态空间模型 (SSM) 和位置嵌入相结合,在不使用自注意力机制的情况下,实现了与 Vision Transformer 相媲美甚至更优的性能,并显著提升了处理高分辨率图像时的计算与内存效率。
关键定义
-
状态空间模型 (State Space Model, SSM):一种源自经典控制理论的序列模型。它通过一个隐含状态 $h(t) \in \mathbb{R}^{\mathtt{N}}$ 来映射一个一维输入函数或序列 $x(t)$ 到输出 $y(t)$。其连续形式由以下微分方程定义:$h^{\prime}(t)=\mathbf{A}h(t)+\mathbf{B}x(t)$ 和 $y(t)=\mathbf{C}h(t)$。通过离散化,SSM可以高效地处理序列数据,并能以卷积或循环的方式进行计算。
-
Mamba: 一种先进的状态空间模型。其核心创新在于引入了选择性机制,使得SSM的参数 $(\mathbf{A}, \mathbf{B}, \mathbf{C}, \mathbf{\Delta})$ 变为输入依赖 (input-dependent),从而能够根据数据内容动态调整状态转换和输出。同时,它采用了一种硬件感知的并行扫描算法,即使在循环模式下也能实现高效的训练和推理。
-
Vision Mamba (Vim):本文提出的纯SSM视觉骨干网络。它将图像处理为patch序列,并利用Vim模块进行特征提取。Vim旨在保留ViT的序列建模能力和全局感受野,同时克服其二次方复杂度的限制。
-
双向Mamba模块 (Bidirectional Mamba Block):Vim的核心组件。由于图像数据没有固有的单向顺序,该模块通过并行处理前向和后向两个方向的图像patch序列来捕捉全局上下文。它对输入序列分别进行前向和后向的SSM扫描,然后将两个方向的输出结果相加,从而使每个token都能聚合来自整个序列的信息,模拟了自注意力的全局建模能力。
相关工作
当前,视觉骨干网络主要由卷积神经网络(ConvNets)和视觉Transformer(ViTs)主导。ViT通过其自注意力机制,能够为每个图像patch提供数据依赖的全局上下文,这使其在各种视觉任务和多模态应用中表现出色。
然而,ViT的核心瓶颈在于自注意力机制的计算复杂度。其计算量和内存占用随输入序列长度(即图像分辨率)的增加呈二次方增长($O(M^2)$),这极大地限制了其在处理高分辨率图像时的效率和实用性。
为了解决这一问题,本文借鉴了Mamba模型在自然语言处理领域的成功经验,旨在设计一种全新的、高效的纯SSM视觉骨干网络。具体目标是:构建一个既能像ViT一样对整个图像进行全局、数据依赖的上下文建模,又具有线性计算复杂度($O(M)$)的模型,从而能够高效地处理高分辨率视觉任务。
本文方法
整体架构
Vision Mamba (Vim) 的整体架构遵循了Vision Transformer (ViT) 的基本设计范式。
- 图像序列化: 输入图像 $\mathbf{t}\in\mathbb{R}^{\mathtt{H}\times\mathtt{W}\times\mathtt{C}}$ 首先被分割成一系列不重叠的图像块 (patches),并被展平。
- 令牌化 (Tokenization): 每个图像块通过一个线性投影层映射成一个 $\mathtt{D}$ 维的向量,即patch token。与ViT类似,一个可学习的分类token (class token) 可以被拼接到序列的开头(或中间),用于最终的分类任务。
- 位置编码: 为了引入空间位置信息,将位置嵌入 (position embeddings) $\mathbf{E}_{pos}$ 加到token序列中。
- Vim编码器: 得到的token序列 $\mathbf{T}_{0}$ 被送入一个由 $\mathtt{L}$ 个Vim模块堆叠而成的编码器中进行特征提取。
- 任务头: 最后,从编码器输出的分类token经过一个多层感知机 (MLP) 头,得到最终的预测结果。
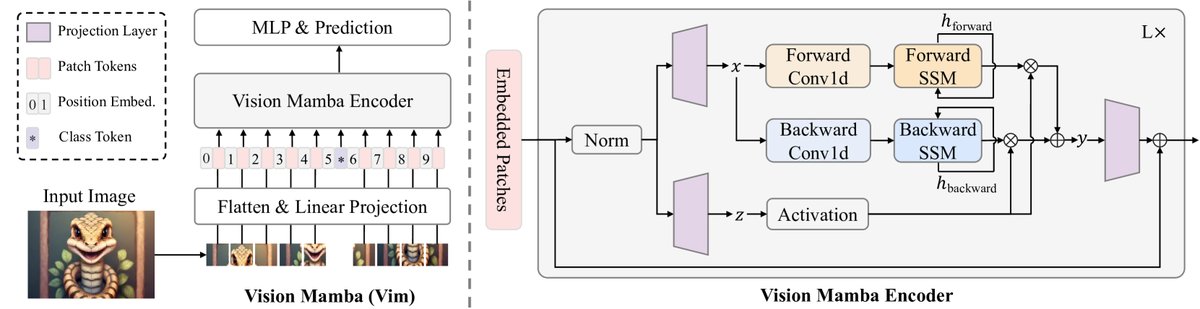
核心创新:双向Mamba模块
标准的Mamba模块是为处理具有明确顺序的1D序列(如文本)而设计的,其单向性不适合需要全局空间理解的视觉任务。为了解决这个问题,本文提出了Vim模块,其核心是双向状态空间建模。
如下图所示,Vim模块的处理流程如下:
- 输入token序列首先经过层归一化 (Layer Normalization)。
- 归一化后的序列通过线性层分别映射为两个中间表示 $\mathbf{x}$ 和 $\mathbf{z}$。
- 双向处理: $\mathbf{x}$ 被送入两个并行的SSM分支,一个处理前向序列,另一个处理反向序列。
- 在每个分支中,序列首先通过一个1D卷积层,然后经过激活函数。接着,通过线性投影生成SSM的动态参数 $\mathbf{B}$, $\mathbf{C}$, และ $\mathbf{\Delta}$。这些参数是输入依赖的,体现了Mamba的选择性机制。
- 利用这些参数和预设的 $\mathbf{A}$ 参数,执行SSM的循环计算,分别得到前向输出 $\mathbf{y}_{forward}$ และ 后向输出 $\mathbf{y}_{backward}$。
- 信息融合: 两个方向的输出 $\mathbf{y}_{forward}$ 和 $\mathbf{y}_{backward}$ 在被门控单元(使用 $\mathbf{z}$)处理后相加。
- 最后,融合后的结果通过一个线性层投影回原始维度,并通过残差连接与输入相加,形成该模块的最终输出。
这一双向设计确保了模型中的每个patch token都能够从序列中所有其他token(无论其前后位置)收集信息,从而有效地模拟了自注意力机制的全局感受野。
``$$ 算法 1 Vim 模块处理流程
输入: token序列 T_{l-1} 输出: token序列 T_{l}
1: /* 归一化输入序列 / 2: T’_{l-1} ← Norm(T_{l-1}) 3: x ← Linear^x(T’_{l-1}) 4: z ← Linear^z(T’_{l-1}) 5: / 分别处理前向和后向 / 6: for o in {forward, backward} do 7: x’_o ← SiLU(Conv1d_o(x)) 8: B_o ← Linear_o^B(x’_o) 9: C_o ← Linear_o^C(x’_o) 10: Δ_o ← log(1+exp(Linear_o^Δ(x’_o) + Parameter_o^Δ)) 11: / … (计算离散化参数 A_bar, B_bar) … / 12: / … (SSM循环计算得到 y_o) … / 13: end for 14: / 门控融合 / 15: y’_forward ← y_forward ⊙ SiLU(z) 16: y’_backward ← y_backward ⊙ SiLU(z) 17: / 残差连接 */ 18: T_l ← Linear^T(y’forward + y’_backward) + T{l-1} 19: 返回 T_l $$``
效率分析
Vim继承了Mamba的硬件感知设计,从而在计算、内存和IO三方面都具有高效率:
-
计算效率: 自注意力机制的计算复杂度为 $O(M^2D)$,对序列长度 $M$ 是二次方关系。而Vim中SSM的计算复杂度为 $O(MDN)$,对序列长度 $M$ 是线性关系($N$为固定的状态维度)。这使得Vim在处理长序列(即高分辨率图像)时具有显著的速度优势。
\[\Omega(\text{self-attention})=4\mathtt{M}\mathtt{D}^{2}+2\mathtt{M}^{2}\mathtt{D}\] \[\Omega(\text{SSM}) = 6\mathtt{M}\mathtt{D}\mathtt{N} + 2\mathtt{M}\mathtt{D}\mathtt{N}\] -
IO效率: 通过将SSM的参数和输入从慢速的HBM(高带宽内存)加载到快速的SRAM中进行计算,Vim减少了昂贵的内存IO操作,从 $O(BMEN)$ 降低到 $O(BME+EN)$。
-
内存效率: 为了处理长序列,Vim采用重计算(recomputation)策略。在反向传播过程中,它不存储庞大的中间状态,而是在需要时重新计算,从而大大降低了显存占用。
实验结论
关键实验结果
本文在图像分类、语义分割和目标检测等多个基准任务上对Vim进行了全面评估。
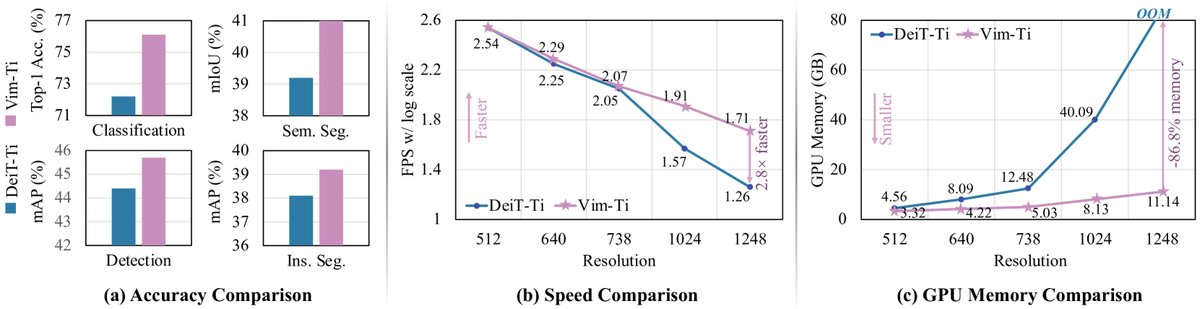
- 图像分类 (ImageNet-1K): Vim在不同模型尺寸上均优于或持平于高度优化的DeiT模型。例如,Vim-S的Top-1准确率达到80.3%,超过DeiT-S的79.8%。经过长序列微调后,Vim-S†的准确率提升至81.4%,接近更大尺寸的DeiT-B。
| 方法 | 尺寸 | 参数量 | ImageNet Top-1 Acc. | | :— | :— | :— | :— | | Transformers | | | | | DeiT-Ti | $224^2$ | 6M | 72.2 | | DeiT-S | $224^2$ | 22M | 79.8 | | DeiT-B | $224^2$ | 86M | 81.8 | | SSMs | | | | | Vim-Ti | $224^2$ | 7M | 76.1 | | Vim-S | $224^2$ | 26M | 80.3 | | Vim-B | $224^2$ | 98M | 81.9 | | Vim-S† | $224^2$ | 26M | 81.4 (+1.1) | | Vim-B† | $224^2$ | 98M | 83.2 (+1.3) | 注:†表示经过长序列微调。
- 语义分割 (ADE20K): 使用UperNet框架,Vim同样表现出色。Vim-Ti比DeiT-Ti高出1.8 mIoU,Vim-S比DeiT-S高出0.9 mIoU。
| Backbone | #param. | $val$ mIoU |
|---|---|---|
| DeiT-Ti | 11M | 39.2 |
| Vim-Ti | 13M | 41.0 |
| DeiT-S | 43M | 44.0 |
| Vim-S | 46M | 44.9 |
-
目标检测 (COCO): 在Cascade Mask R-CNN框架下,Vim-Ti在目标检测和实例分割任务上分别比DeiT-Ti高出1.3 AP$^{\text{box}}$和1.1 AP$^{\text{mask}}$,特别是在中大尺寸物体上优势更明显,证明了其更强的长距离上下文学习能力。
-
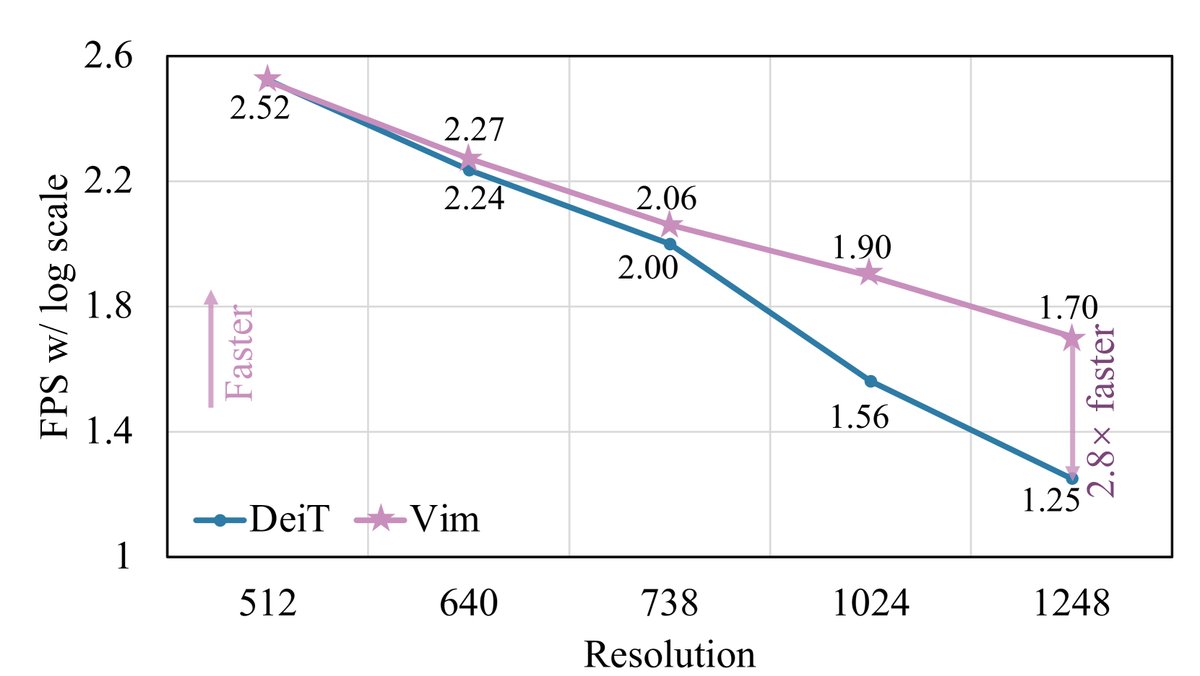
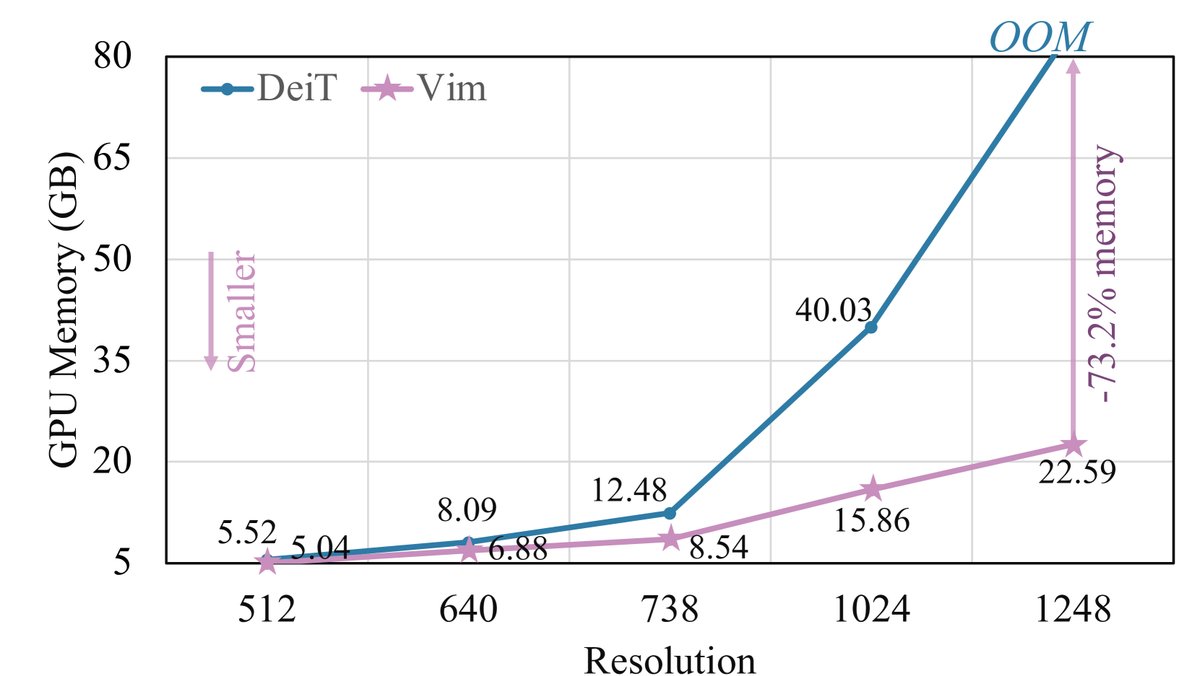
效率验证: 实验明确显示,随着图像分辨率的增加,Vim的效率优势愈发显著。在1248×1248分辨率下进行推理时,Vim的速度是DeiT的2.8倍,同时节省了86.8%的GPU显存。这一线性扩展能力是Vim的核心优势。
结论
实验结果有力地证明,Vim作为一种纯SSM架构,不仅在性能上能够与成熟的Vision Transformer相媲美甚至超越,而且在处理高分辨率图像时具有压倒性的计算和内存效率优势。这表明,依赖自注意力机制进行视觉表征学习并非必要。Vim凭借其出色的性能和可扩展性,展现了成为下一代视觉基础模型骨干网络的巨大潜力。