Voyager: An Open-Ended Embodied Agent with Large Language Models
-
ArXiv URL: http://arxiv.org/abs/2305.16291v2
-
作者: Yuke Zhu; Guanzhi Wang; Yunfan Jiang; Chaowei Xiao; Yuqi Xie; Anima Anandkumar; Linxi (Jim) Fan; Ajay Mandlekar
-
发布机构: Caltech; NVIDIA; Stanford; University of Texas at Austin; University of Wisconsin-Madison
TL;DR
本文提出了一种名为 Voyager 的具身智能体,它首次利用大型语言模型(LLM)实现了在《我的世界》(Minecraft) 开放世界中的无干预终身学习,通过自动课程、可不断增长的技能库和迭代提示机制,持续探索、获取技能并做出新发现。
关键定义
本文的核心是 Voyager 智能体,其能力由以下三个创新的关键组件定义:
- 自动课程 (Automatic Curriculum): 一个由 GPT-4 驱动的模块,根据智能体的当前状态(如物品栏、位置)、已完成和失败的任务以及“尽可能发现多样事物”的总体目标,自动提出探索性的、难度适中的新任务。
- 技能库 (Skill Library): 一个不断增长的、存储可执行代码(即技能)的数据库。每个技能都通过其自然语言描述的嵌入向量进行索引,以便在未来遇到相似任务时能够被检索和复用。这使得技能可以组合,能力可以快速累积,并有效缓解灾难性遗忘。
- 迭代提示机制 (Iterative Prompting Mechanism): 一种用于代码生成和自我完善的闭环流程。该机制执行生成的代码,并从三个来源获取反馈:环境反馈(如游戏内事件)、执行错误(来自代码解释器)和自我验证(由另一个 GPT-4 实例扮演的批评家),然后将这些反馈整合到下一次的提示中,以迭代地修正代码直至任务成功。
相关工作
目前,构建能在开放世界中持续探索、规划和学习新技能的通用具身智能体仍是人工智能领域的一大挑战。传统的强化学习 (Reinforcement Learning, RL) 和模仿学习方法在系统性探索、可解释性和泛化方面存在困难。
近年来,基于大型语言模型 (Large Language Model, LLM) 的智能体利用其蕴含的世界知识来生成高级规划或可执行策略,在游戏和机器人等领域取得了进展。然而,这些智能体通常缺乏终身学习 (lifelong learning) 的能力,即它们无法在一个很长的时间跨度内持续地获取、更新、积累和迁移知识。
本文旨在解决这一核心问题:创建一个能够在像《我的世界》这样没有预定目标的开放世界中,像人类玩家一样自主学习的智能体。具体来说,本文要解决的挑战是:如何让智能体能 (1) 根据自身能力和环境状况提出合适的任务;(2) 从环境反馈中学习并优化技能,将掌握的技能存入记忆以便复用;(3) 以自我驱动的方式持续探索世界。
本文方法
Voyager 作为一个由 LLM 驱动的具身终身学习智能体,其核心工作流程不依赖于模型微调,而是通过与黑盒 LLM (GPT-4) 的交互实现。整个系统由以下三个协同工作的组件构成。
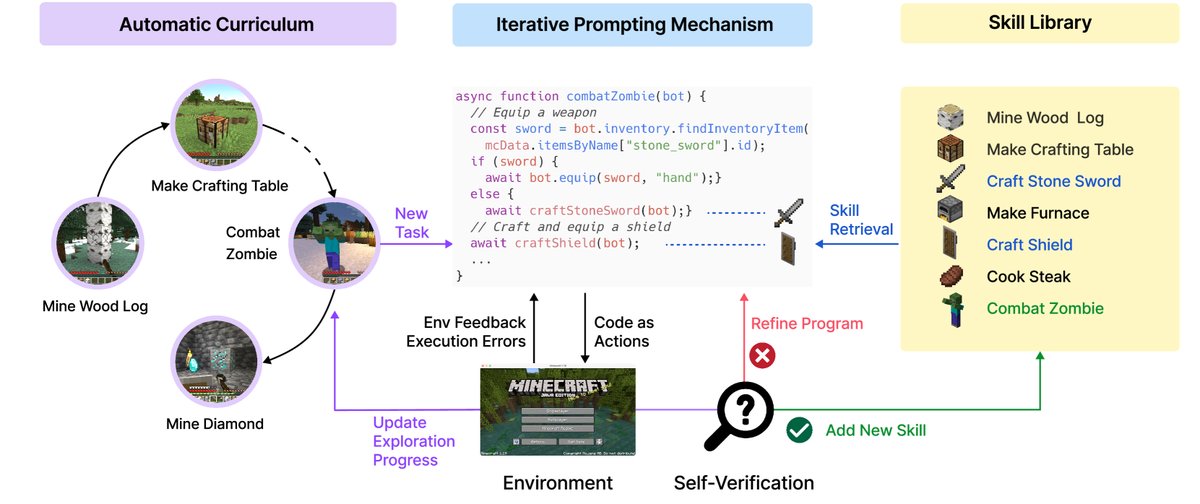 图2: Voyager 包含三个关键组件:用于开放式探索的自动课程,用于实现日益复杂行为的技能库,以及使用代码作为动作空间的迭代提示机制。
图2: Voyager 包含三个关键组件:用于开放式探索的自动课程,用于实现日益复杂行为的技能库,以及使用代码作为动作空间的迭代提示机制。
自动课程
在开放世界中,智能体需要面对难度各异的任务。一个自动化的课程能够确保学习过程具有挑战性又易于管理,并激发智能体的好奇心。Voyager 的自动课程利用 GPT-4 的海量知识,以自下而上的方式生成任务流,使其能够灵活适应探索进度和智能体的当前状态。
该课程的生成提示包含以下部分:
- 指令: 鼓励多样性行为,并设定约束,例如“我的最终目标是发现尽可能多的不同事物……下一个任务不应该太难”。
- 智能体状态: 包括物品栏、装备、周围环境、生物群系、健康状况等。
- 历史任务: 已完成和失败的任务列表,反映智能体的能力边界。
- 额外上下文: 由 GPT-3.5 基于当前状态进行自我提问和回答,以丰富上下文信息。
 图3: 自动课程提出的任务示例。为简洁起见,仅展示部分提示。
图3: 自动课程提出的任务示例。为简洁起见,仅展示部分提示。
技能库
为了应对自动课程提出的日益复杂的任务,一个能够累积和进化能力的技能库至关重要。本文选择使用代码来表示技能,因为程序天然具有时间扩展性和组合性,非常适合《我的世界》中的长时程任务。
- 技能存储: 当一个新技能(一段JavaScript代码)通过迭代提示机制被成功生成和验证后,它会被添加到一个向量数据库中。该数据库的“键”是技能描述文本的嵌入向量,“值”是技能代码本身。
- 技能检索: 当智能体面对新任务时,系统会用任务规划和环境反馈共同构成的查询上下文,在技能库中进行语义搜索,检索出最相关的 Top-5 技能。这些检索到的技能将作为上下文示例(in-context learning)提供给 LLM,以辅助生成新的、更复杂的技能代码。
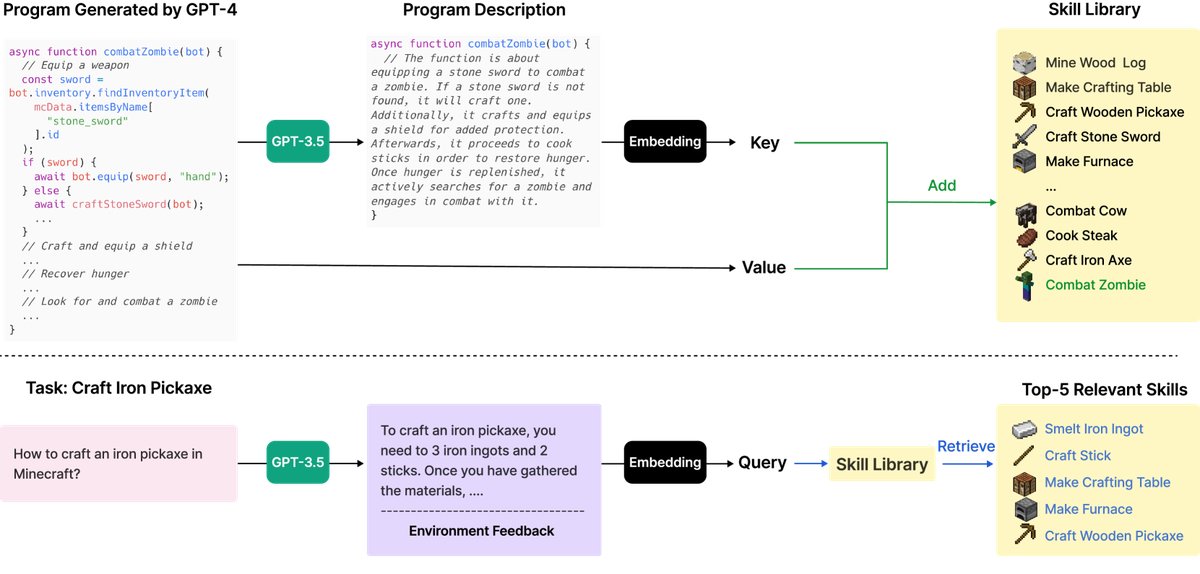 图4: 顶部: 添加新技能。GPT-4 生成并验证一个新技能后,将其添加到技能库(一个向量数据库)中。键是程序描述的嵌入向量,值是程序本身。底部: 技能检索。面对新任务时,系统首先生成解决任务的通用建议并结合环境反馈作为查询,然后检索出 Top-5 相关技能。
图4: 顶部: 添加新技能。GPT-4 生成并验证一个新技能后,将其添加到技能库(一个向量数据库)中。键是程序描述的嵌入向量,值是程序本身。底部: 技能检索。面对新任务时,系统首先生成解决任务的通用建议并结合环境反馈作为查询,然后检索出 Top-5 相关技能。
迭代提示机制
LLM 难以一次性生成完全正确的复杂代码。为解决此问题,本文提出了一种通过三类反馈进行自我改进的迭代提示机制。
- 环境反馈 (Environment Feedback): 描述程序执行中间状态的文本。例如,游戏返回信息“我无法制造铁胸甲,因为我还缺少7个铁锭”,这指明了失败的原因。
- 执行错误 (Execution Errors): 来自代码解释器的标准错误信息,如语法错误或无效函数调用,为修复 Bug 提供了直接线索。
- 自我验证 (Self-verification): 为了检查任务是否成功,本文引入另一个 GPT-4 实例作为“批评家”。它根据智能体当前状态和任务目标,判断任务是否完成。如果任务失败,它还会提供改进建议。这种方式比简单的自我反思更全面,因为它既能判断成功,也能对失败进行反思。
这个迭代过程会持续进行,直到自我验证模块确认任务完成。此时,新技能被存入技能库,并向自动课程请求下一个目标。如果智能体在4轮代码生成后仍卡住,则会请求一个新任务。
 图5: 左: 环境反馈示例。GPT-4 意识到在制作木棍前还需要2块木板。右: 执行错误示例。GPT-4 意识到它应该制作木斧而不是金合欢斧,因为游戏中没有金合欢斧。
图5: 左: 环境反馈示例。GPT-4 意识到在制作木棍前还需要2块木板。右: 执行错误示例。GPT-4 意识到它应该制作木斧而不是金合欢斧,因为游戏中没有金合欢斧。
 图6: 自我验证示例。
图6: 自我验证示例。
实验结论
本文在一系列实验中系统评估了 Voyager 的性能,包括探索表现、技术树掌握、地图覆盖范围和零样本泛化能力。
核心性能评估
- 显著更优的探索能力: Voyager 在160次提示迭代中发现了63种独特物品,是基线方法(ReAct, Reflexion, AutoGPT)的3.3倍。基线方法由于缺乏有效的课程引导,在开放式探索目标下难以取得进展。
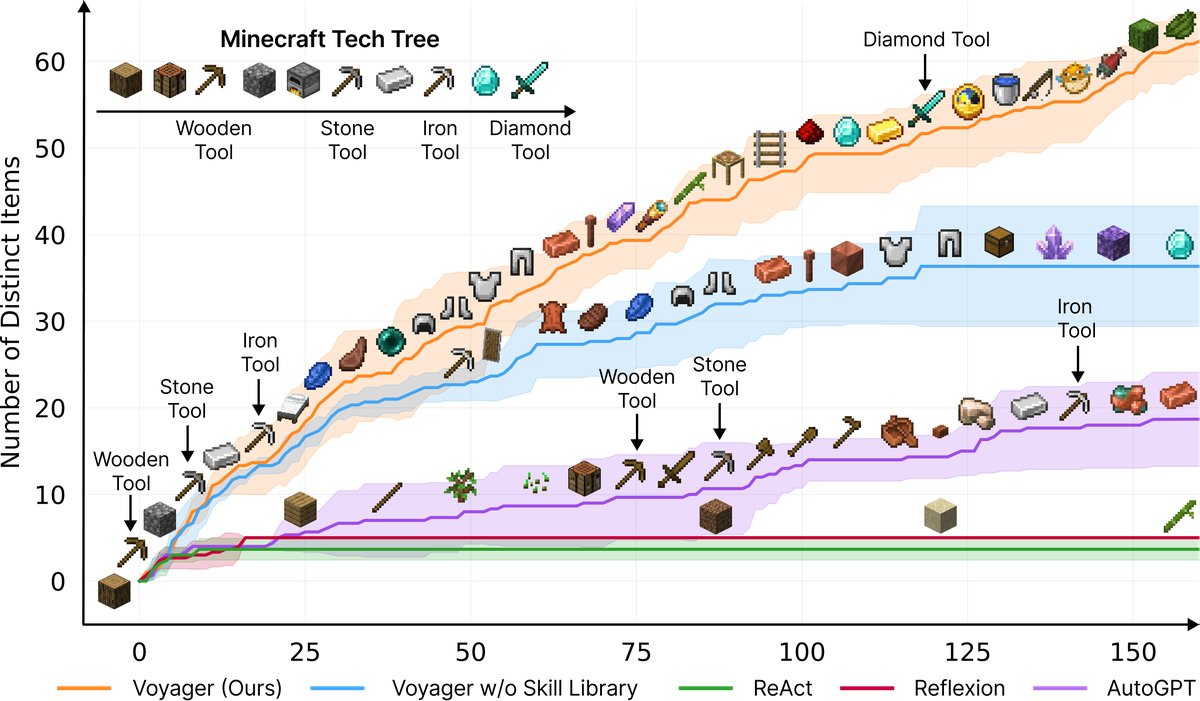 图1: Voyager 持续发现新物品和技能,显著优于基线。X轴表示提示迭代次数。
图1: Voyager 持续发现新物品和技能,显著优于基线。X轴表示提示迭代次数。
- 持续的技术树掌握: 在《我的世界》技术树(木制工具 → 石制工具 → 铁制工具 → 钻石工具)解锁上,Voyager 展现了压倒性优势,解锁木、石、铁工具的速度分别比基线快15.3倍、8.5倍和6.4倍,并且是唯一成功解锁钻石级工具的智能体。
表1: 技术树掌握情况 分数表示在三次独立运行中成功的次数。0/3意味着该方法未能在最大迭代次数(160)内解锁该等级。数字是三次试验的平均提示迭代次数,越少越好。
| 方法 | 木制工具 | 石制工具 | 铁制工具 | 钻石工具 |
|---|---|---|---|---|
| ReAct | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| Reflexion | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| AutoGPT | $92\pm 72$ (3/3) | $94\pm 72$ (3/3) | $135\pm 103$ (3/3) | N/A (0/3) |
| Voyager (无技能库) | 7±2 (3/3) | 9±4 (3/3) | $29\pm 11$ (3/3) | N/A (0/3) |
| Voyager (本文方法) | 6±2 (3/3) | 11±2 (3/3) | 21±7 (3/3) | 102 (1/3) |
- 广阔的地图遍历: Voyager 的移动距离是基线的2.3倍,成功穿越了多样的地形。而基线智能体常常被困在局部区域。
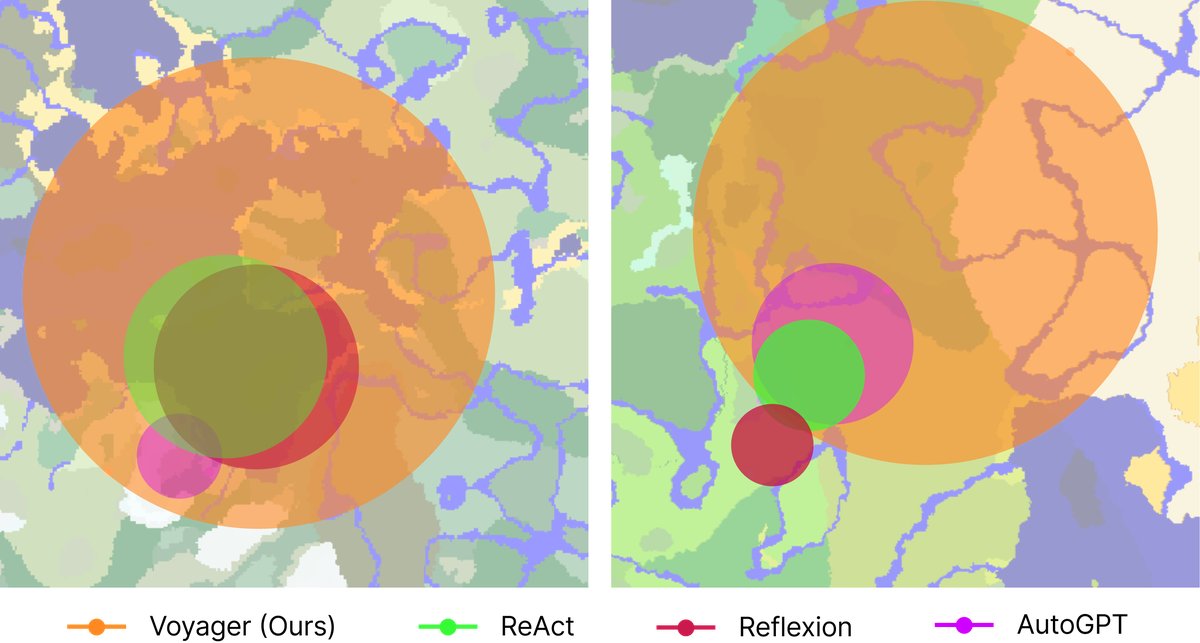 图7: 地图覆盖范围:鸟瞰图。Voyager 穿越了多样的地形,移动距离是基线的2.3倍。
图7: 地图覆盖范围:鸟瞰图。Voyager 穿越了多样的地形,移动距离是基线的2.3倍。
- 高效的零样本泛化: 在一个全新的世界中,面对从未见过的任务(如制作钻石镐),Voyager 能够利用其在先前学习中构建的技能库,稳定地完成所有任务。相比之下,基线方法无法完成任何一项任务。有趣的是,即使是 AutoGPT,在接入了 Voyager 的技能库后性能也得到提升,证明了该技能库的通用性和即插即用价值。
表2: 对未见任务的零样本泛化能力 分数表示在三次独立尝试中成功的次数。0/3表示该方法未能在最大迭代次数(50)内解决任务。数字是三次试验的平均提示迭代次数,越少越好。
| 方法 | 钻石镐 | 金剑 | 熔岩桶 | 指南针 |
|---|---|---|---|---|
| ReAct | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| Reflexion | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| AutoGPT | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| AutoGPT (使用本文技能库) | 39 (1/3) | 30 (1/3) | N/A (0/3) | 30 (2/3) |
| Voyager (无技能库) | 36 (2/3) | $30\pm 9$ (3/3) | $27\pm 9$ (3/3) | $26\pm 3$ (3/3) |
| Voyager (本文方法) | 19±3 (3/3) | 18±7 (3/3) | 21±5 (3/3) | 18±2 (3/3) |
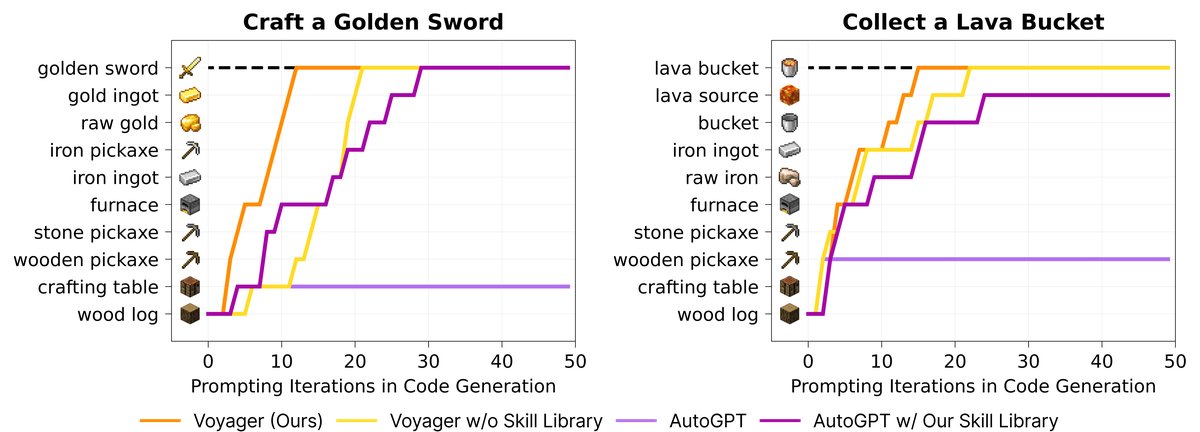 图8: 对未见任务的零样本泛化。可视化了两种任务中各方法的中间进展。
图8: 对未见任务的零样本泛化。可视化了两种任务中各方法的中间进展。
消融研究
- 自动课程至关重要,移除后发现的物品数量下降了93%。
- 技能库对于避免后期性能停滞、构建复杂行为至关重要。
- 自我验证是所有反馈类型中最重要的,移除后性能下降73%。
- 使用 GPT-4 进行代码生成远优于 GPT-3.5,发现的物品数量多5.7倍,证明了 GPT-4 在编码能力上的代际飞跃。
 图9: 消融研究。左图展示了自动课程、技能库和GPT-4的重要性。右图展示了迭代提示机制中每种反馈的必要性。
图9: 消融研究。左图展示了自动课程、技能库和GPT-4的重要性。右图展示了迭代提示机制中每种反馈的必要性。
与人类反馈的结合
尽管 Voyager 目前不具备视觉感知能力,但实验证明它可以通过整合人类反馈来完成更复杂的任务,例如建造一个下界传送门或一栋房子。人类可以扮演“批评家”(提供视觉修正)或“课程设计者”(分解复杂任务)的角色,增强 Voyager 在三维空间结构建造方面的能力。
 图10: 在人类输入下建造设计的进展展示。
图10: 在人类输入下建造设计的进展展示。
总结
本文提出的 Voyager 是首个由 LLM 驱动的具身终身学习智能体。实验证明,它能够在无需人工干预的情况下,持续探索世界、发展日益复杂的技能,并在发现新物品、解锁技术树、探索地图和泛化到新任务方面表现出卓越的性能。Voyager 的成功为开发无需微调模型参数的通用智能体提供了一个有力的起点和范例。