Webscale-RL: Automated Data Pipeline for Scaling RL Data to Pretraining Levels
-
ArXiv URL: http://arxiv.org/abs/2510.06499v1
-
作者: Shiyu Wang; Huan Wang; Haolin Chen; Ding Zhao; Zuxin Liu; Silvio Savarese; Weiran Yao; Caiming Xiong; Zhepeng Cen; Zhiwei Liu
TL;DR
本文提出了一种名为 Webscale-RL 的自动化数据流水线,旨在通过从网络文档中自动挖掘和生成数据,将强化学习(RL)数据的规模扩展到与预训练数据相当的水平,从而显著提升大型语言模型的性能。
关键定义
本文的核心是其创新的数据生成流水线,其中包含以下几个关键概念:
- Webscale-RL 数据流水线 (Webscale-RL Data Pipeline):一个全自动化的系统,用于从海量网络文档中生成高质量、大规模的强化学习训练数据。该流水线涵盖了从源文档中创建上下文、生成指令、产出响应到最终验证的全过程。
- 可验证的角色 (Verifiable Personas):流水线首先从源文档中生成特定的“角色”或背景设定。这些角色具有可验证性,意味着它们紧密基于源文档内容,为后续生成的问题和答案提供了事实依据和具体情境,从而提高了数据的真实性和复杂度。
- 正确性验证 (Correctness Verification):流水线中的一个关键质量控制步骤,旨在确保模型生成的答案在事实上是准确的。它通过比对源文档来核实答案的正确性,过滤掉不准确或虚构的内容。
- 泄漏预防 (Leakage Prevention):流水线中的另一个关键质量控制步骤,用于防止生成的指令或问题直接“泄露”源文档中的关键信息,从而避免模型通过简单的复制粘贴来“作弊”。此举确保了模型需要进行真正的推理才能解决问题。
相关工作
当前,大型语言模型的训练主要分为两个阶段:大规模无监督预训练和有监督微调/强化学习对齐。预训练阶段使用了海量的网络文本数据(量级可达数万亿 token),而强化学习(尤其是基于人类反馈的强化学习 RLHF)阶段的数据规模则小得多,通常依赖于昂贵且耗时的人工标注。这种 RL 数据的稀缺性成为了进一步提升模型能力的主要瓶颈。
本文旨在解决的核心问题是:如何自动化地、大规模地生成高质量、多样化且安全的强化学习训练数据,从而克服当前 RL 数据收集的瓶颈,将 RL 数据的规模提升至预训练级别,以充分释放大型语言模型的潜力。
本文方法
本文提出了一种新颖的自动化数据流水线——Webscale-RL,其核心是实现强化学习数据生产的规模化和高质量。该流水线的设计精巧,通过多个阶段将原始网络文本转化为优质的 RL 训练数据。
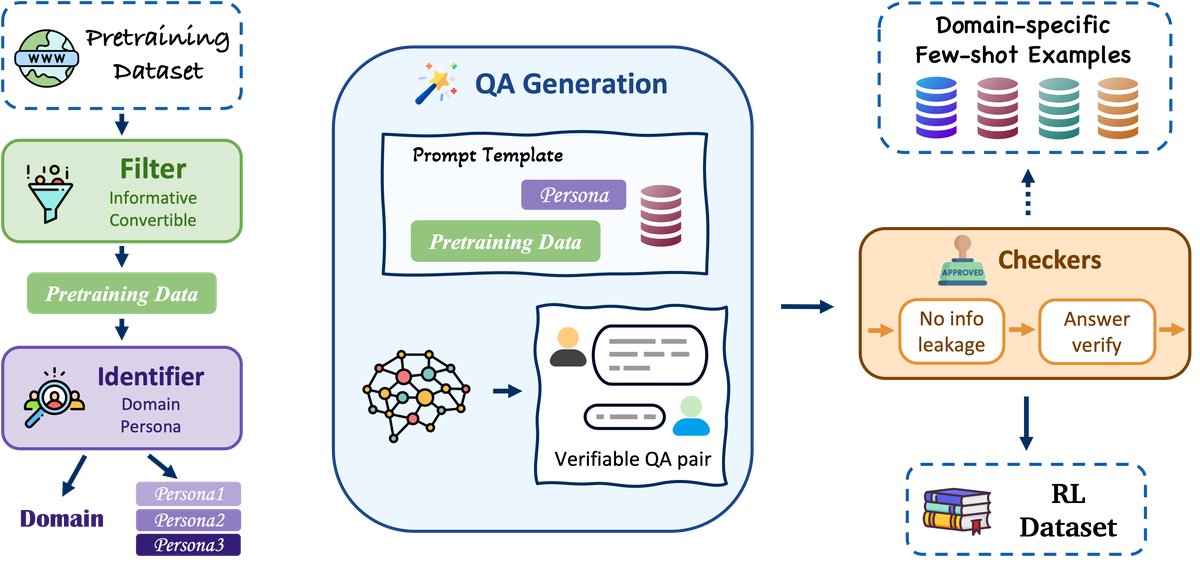
流水线的主要流程如下:
-
可验证角色的创建:流水线从海量的网络文档中采样。对于每个文档,它会生成一个“可验证的角色”(Verifiable Persona)。这个角色为后续的交互提供了具体的上下文和背景,例如“你是一个正在分析莎士比亚戏剧《哈姆雷特》的文学教授”。这使得生成的数据更具深度和真实性,而非泛泛的问答。
-
指令-响应对的生成:基于创建的角色和源文档,系统会自动生成相关的指令(问题),并驱动一个基础模型来产出相应的响应(答案)。
-
多维度质量验证:这是流水线的核心创新之一。为了确保生成数据的质量,系统会进行严格的自动化验证:
- 正确性验证 (Correctness Verification):使用一个独立的验证模型,检查生成的响应是否与源文档中的事实相符,确保答案的准确性和可靠性。
- 泄漏预防 (Leakage Prevention):系统会分析生成的指令,判断其是否包含了过多源文档中的原文片段,以防止模型通过简单的信息复制来回答问题。这迫使模型必须进行推理才能生成正确的答案。
- 安全性与合规性:流水线还包含模块来过滤掉不安全或不符合要求的生成内容。
通过这一系列自动化步骤,Webscale-RL 能够持续不断地从网络中“提炼”出海量的、具有事实依据和推理挑战的优质 RL 数据。
实验结论
本文通过构建大规模数据集和一系列下游任务实验,验证了 Webscale-RL 方法的有效性。
数据集分析
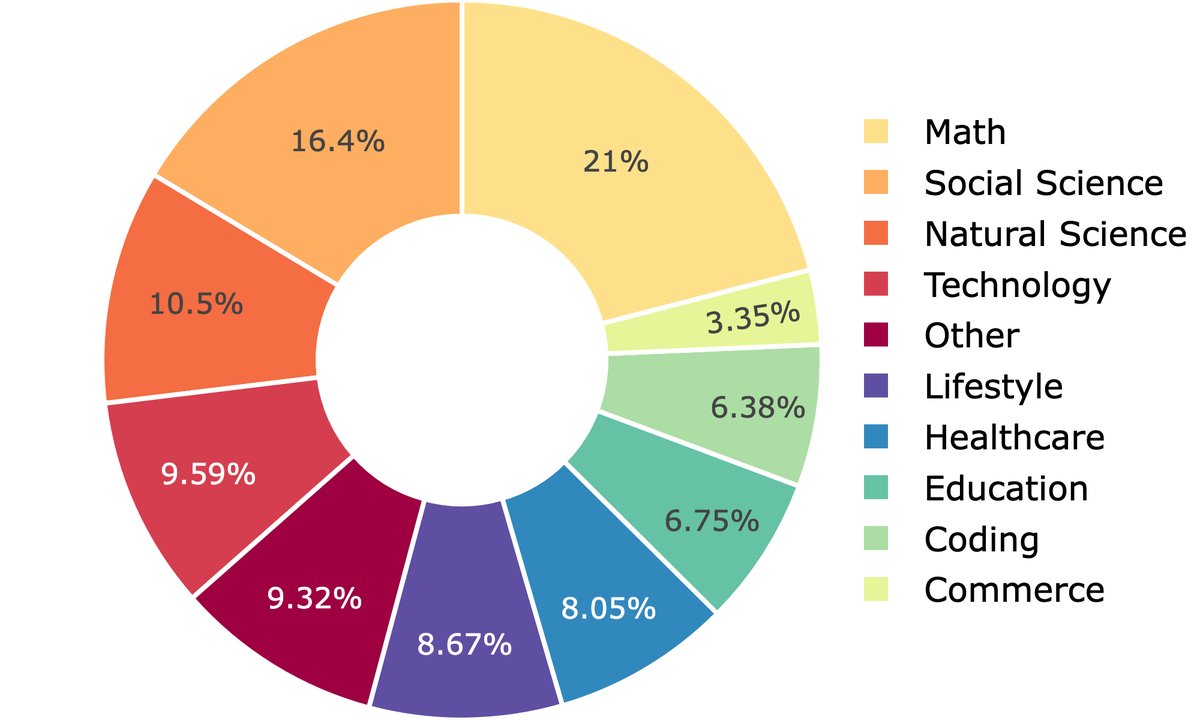
- 本文使用 Webscale-RL 流水线构建了一个包含超过 30 亿 token 的庞大数据集。
- 该数据集在领域分布上非常多样化,覆盖了从科学、技术到人文、艺术等广泛领域。
- 与现有的人类标注数据集相比,Webscale-RL 生成的数据在复杂推理任务上占比更高,例如在代码生成方面占比超过 8.6%,在数学问题方面占比超过 3.3%。
性能评估
实验将使用 Webscale-RL 数据集训练的模型与使用其他高质量人类标注数据集训练的模型进行了对比。
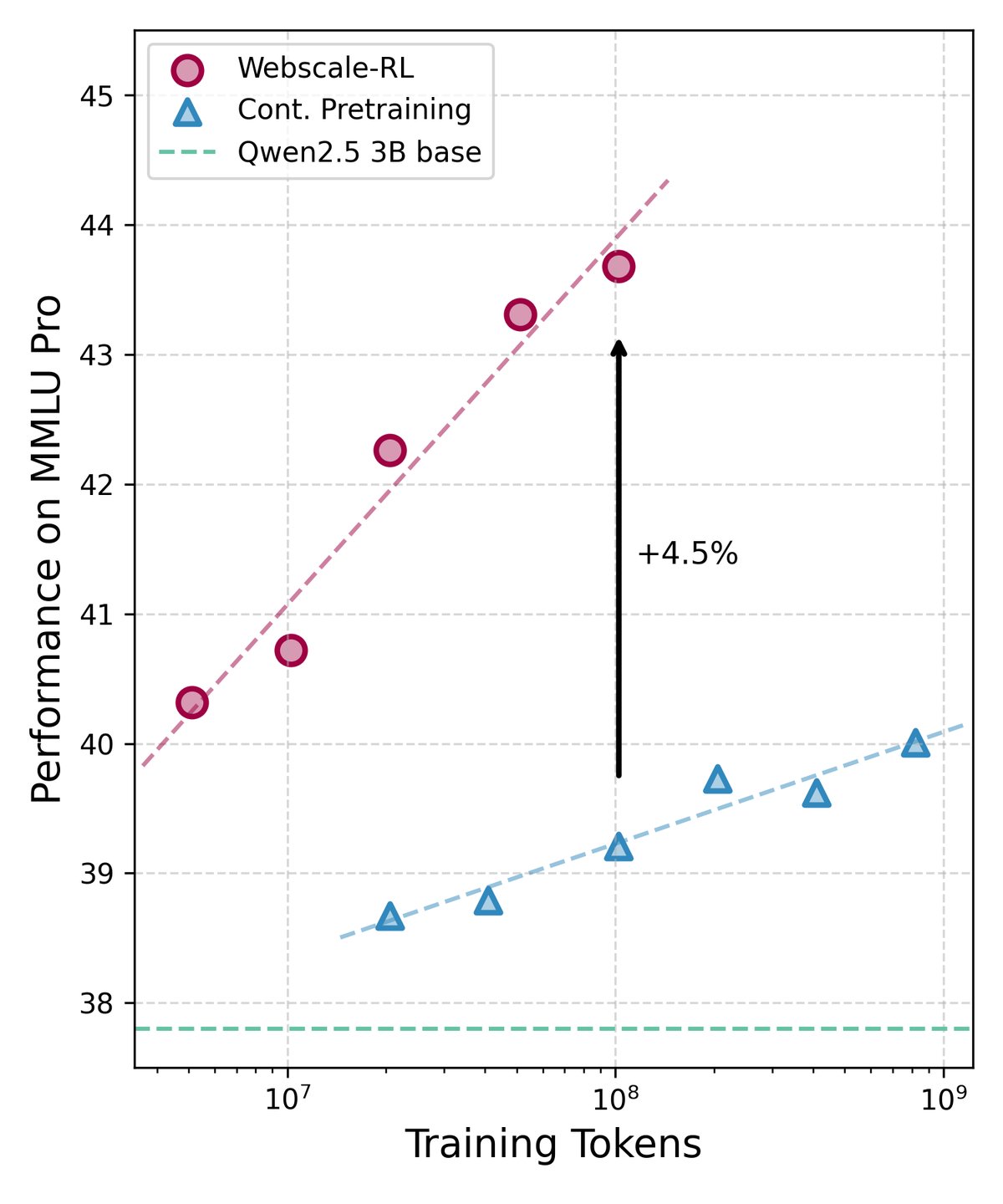
- 主要结果:在多个标准学术基准测试中,使用 Webscale-RL 数据训练的模型表现出显著的性能优势。特别是在需要复杂推理能力的基准(如 MMLU-pro 和 BBH)上,其性能提升尤为明显。
- 规模效应:实验结果清晰地展示了“规模效应”——随着训练中使用的 Webscale-RL 数据量的增加,模型的性能也随之稳步提升。这证明了大规模、高质量的 RL 数据对于模型能力持续增长至关重要。
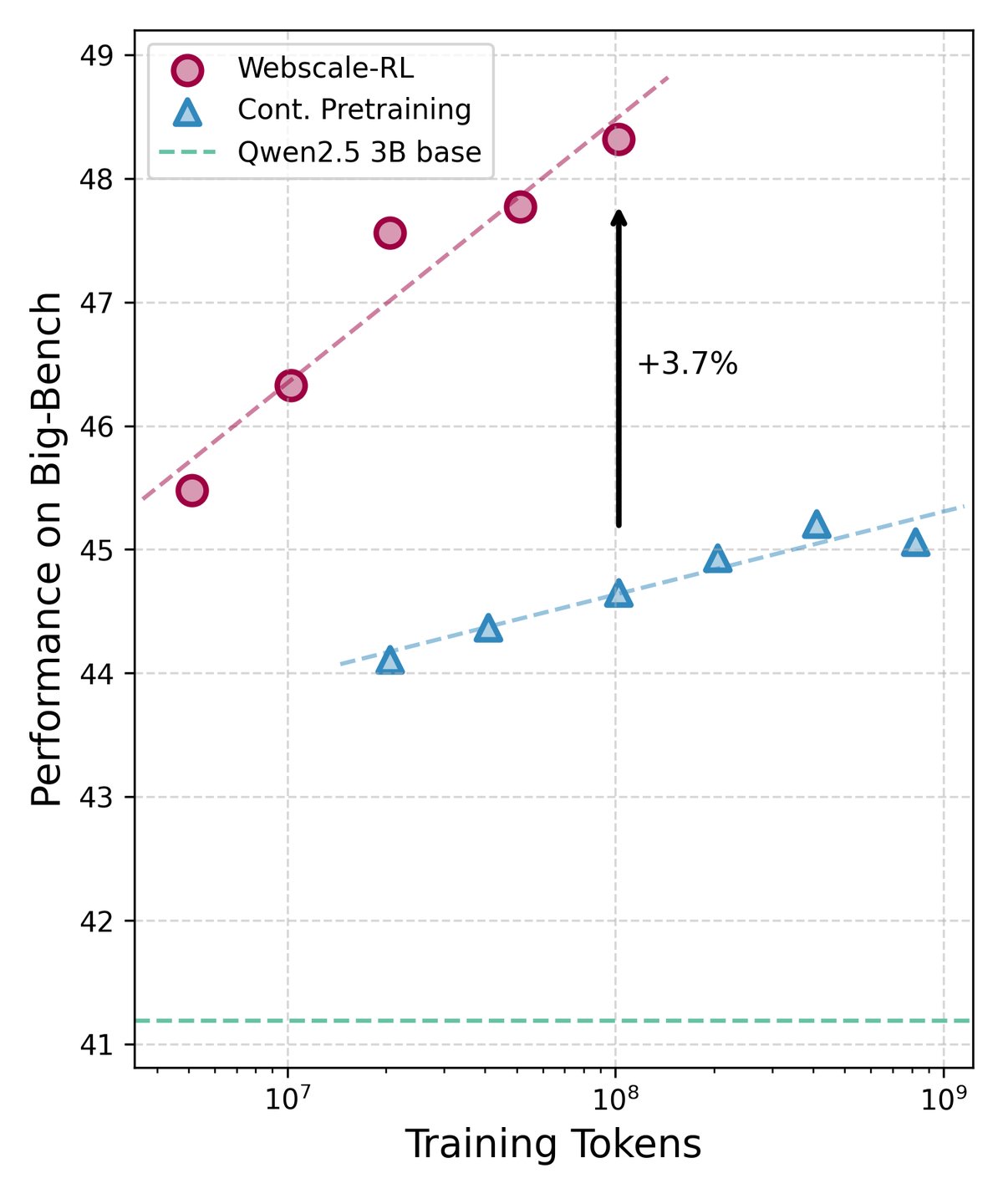
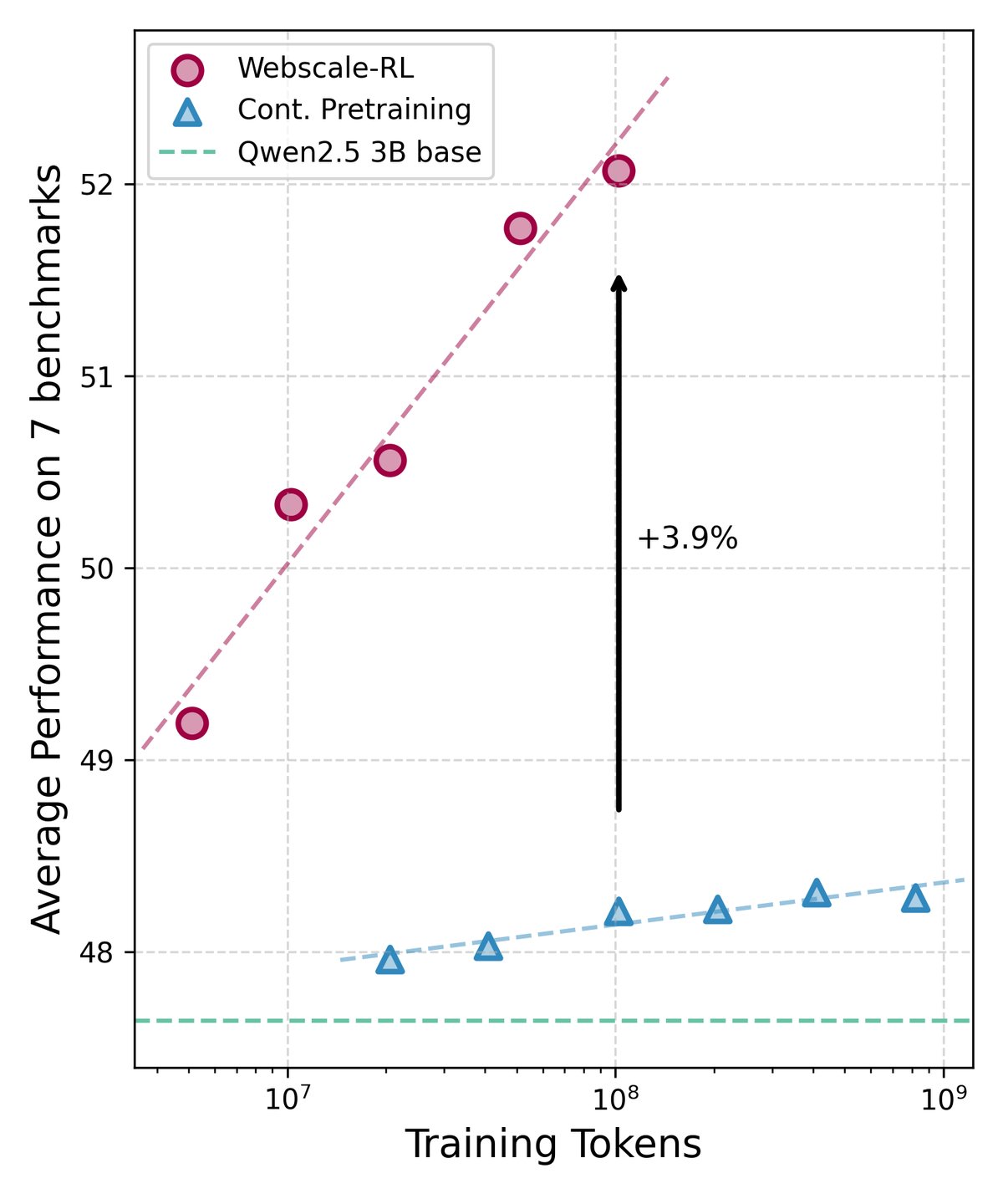
最终结论
本文成功证明了通过 Webscale-RL 自动化数据流水线,可以有效地将 RL 训练数据的规模扩展到前所未有的水平。实验结果表明,利用这种方式生成的“网络规模”的 RL 数据来训练大型语言模型,能够显著提升其在各类任务(尤其是复杂推理任务)上的性能,从而验证了“扩展 RL 数据规模是提升模型能力的关键路径”这一核心假设。