WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
-
ArXiv URL: http://arxiv.org/abs/2509.13312v1
-
作者: Yong Jiang; Pengjun Xie; Shaopeng Lai; Houquan Zhou; Xin Guan; Jun Zhang; Ming Yan; Jingren Zhou; Fei Huang; Bo Zhang; 等12人
-
发布机构: Alibaba Group; Tongyi Lab
TL;DR
本文提出了 WebWeaver,一个模仿人类研究过程的双智能体框架,其中规划器(Planner)通过迭代优化大纲并搜集证据,构建动态且有来源依据的报告结构,而写作者(Writer)则分章节、有针对性地从记忆库中检索信息进行写作,有效解决了传统方法的静态规划缺陷和长上下文处理失败问题,在开放式深度研究任务中实现了业界领先水平。
关键定义
- 开放式深度研究 (Open-Ended Deep Research, OEDR):一项复杂的AI挑战,要求智能体独立探索和消化海量信息(如超过100个网页和PDF),并综合形成一份包含独特、合成观点的深度研究报告。这类任务没有唯一的标准答案。
- WebWeaver: 本文提出的核心框架,由一个规划器(Planner)智能体和一个写作者(Writer)智能体组成的双智能体系统,旨在模拟人类专家的研究工作流。
- 动态研究循环 (Dynamic Research Cycle):规划器智能体的核心工作模式。它并非一次性生成固定大纲,而是在“证据获取”和“大纲优化”之间进行迭代循环。新发现的证据会持续地重塑和优化研究大纲,使研究路径能够动态适应。
- 记忆驱动的合成 (Memory-Grounded Synthesis):写作者智能体的核心工作机制。为避免长上下文问题,写作者采用“分而治之”的策略,按章节撰写报告。在撰写每个章节时,它仅从一个集中的证据记忆库中,根据大纲中的引文标记,检索并关注与该章节最相关的证据。
相关工作
当前处理开放式深度研究(OEDR)的方法主要存在两大瓶颈。
第一类是简单的“先搜索后生成”(search-then-generate)范式,即一次性搜集所有信息,然后直接生成报告。这种方法由于缺乏一个清晰的结构化大纲来指导内容合成,往往导致输出质量低下、逻辑混乱。
第二类是更复杂的方法,它会先生成一个静态的研究大纲,然后针对大纲的每个部分进行定向搜索。这种方法的致命缺陷在于,大纲在研究开始前就已完全固定,严重依赖大语言模型(LLM)内部可能过时或不全面的知识。这种僵化的流程“固化”了研究过程,阻碍了智能体探索在搜索过程中发现的意外但有价值的信息。此外,在生成最终报告时,将所有检索到的材料一次性输入模型,极易引发“中间内容丢失”(loss in the middle)等长上下文处理难题,并增加内容幻觉的风险,从而损害报告的准确性和深度。
本文旨在解决上述问题,即现有方法中“规划与证据获取相脱节”以及“一次性生成模式导致的长上下文失败”两大核心挑战。
本文方法
本文提出的 WebWeaver 是一个创新的双智能体框架,包含一个规划器(Planner)和一个写作者(Writer),旨在模仿人类研究者的认知工作流程。
概述
WebWeaver 的完整工作流如下图所示。首先,规划器在一个动态研究循环中运作,它交替执行网页搜索以获取证据,并持续优化报告大纲。这个探索阶段的最终产物是一个全面、结构良好且带有来源引用的研究大纲,其中每个章节都通过引文明确链接到一个存储证据的记忆库。
随后,写作者接管合成阶段。为了规避一次性生成和长上下文处理的陷阱,写作者采用一种基于章节、由记忆库驱动的合成方法。它针对大纲中的每一个章节,从记忆库中进行精准、小范围的证据检索,然后完成该章节的撰写。这种劳动分工确保了最终报告不仅连贯、组织良好,而且具有坚实的证据基础,忠实地模拟了人类深度研究的严谨性。
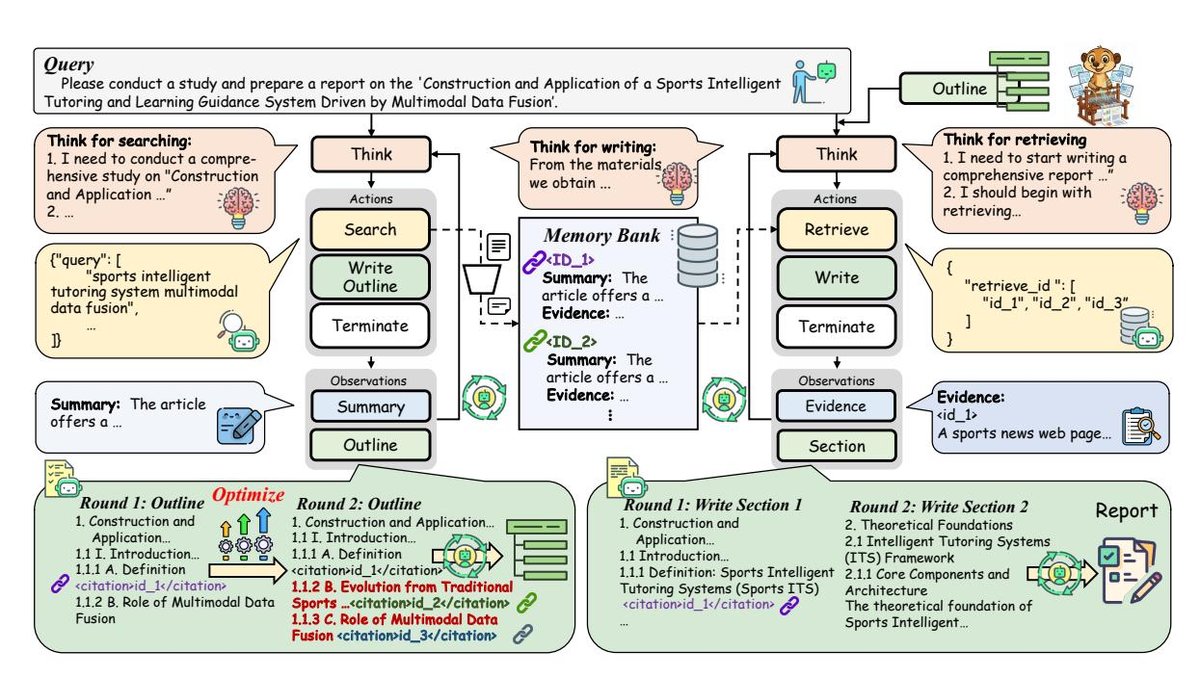
研究循环:迭代式证据获取与大纲优化
传统的深度研究智能体通常遵循一个“大纲指导搜索”的刚性流程,即在收集任何证据之前就生成一个静态大纲,这限制了研究的深度和广度。本文提出了一种动态研究循环,让大纲和搜索策略协同进化,使智能体能够适应和探索新的发现。
规划器的核心是一个在证据获取和大纲优化之间不断迭代的循环。在每一步中,规划器会选择三种动作之一:搜索、优化大纲或终止。
-
证据获取 (Evidence acquisition):当证据不足以构建一个完整大纲时,规划器会执行搜索动作。它首先查询网络搜索引擎,获取包含URL、标题和摘要的搜索结果。为了减少上下文噪声和处理开销,它采用两阶段过滤:首先,利用LLM根据标题和摘要筛选相关URL;然后,对每个解析后的页面,LLM会(1)提炼出与查询相关的摘要,反馈给规划器以指导后续搜索,以及(2)提取可验证的详细证据(如引言、数据点),存入一个结构化的证据记忆库中,供后续写作阶段使用。
-
大纲优化 (Outline optimization):在获取新证据后,规划器会重新审视和优化报告大纲。这不是一次性的生成步骤,而是一个持续的改进过程。规划器利用新信息来扩展章节、添加子节,甚至重构整个大纲,以更好地反映对主题的全面理解。至关重要的是,它会在大纲中填充引文(citations),将每个章节映射到记忆库中特定的证据ID。这个引文机制保证了报告的来源可追溯性,并为下一阶段的分层写作提供了基础。这个循环会一直持续,直到大纲足够全面且有充分证据支持,规划器便输出一个终止动作。
记忆驱动的合成:分层检索与写作
生成长篇报告的一个关键挑战是注意力管理,而非简单的信息获取。将所有证据强行塞入单个上下文窗口进行一次性生成的“暴力”方法存在根本缺陷,容易导致“中间内容丢失”和“上下文滲透”(contextual bleeding),即不相关部分的信息错误地影响当前内容的生成。本文认为,成功的合成过程必须模仿人类认知,将复杂的长文写作任务分解为一系列注意力集中的子任务。因此,本文采用了分层、分而治之的策略。
在规划阶段完成后,写作者会获得结构化的、带有引文的大纲以及对证据记忆库的访问权限。它按以下步骤分章节撰写报告:
- 识别子任务:写作者首先确定当前任务,例如“现在开始写第一节”。
- 定向检索:执行 \(retrieve\) 动作,根据大纲中的引文,从记忆库中仅提取与当前章节相关的证据。
- 内部思考:在接收到证据后,写作者执行一个 \(think\) 动作。在这个思考步骤中,它分析检索到的内容,综合关键见解,选择最有力的证据,并为该节内容构思一个连贯的叙事结构。
- 撰写内容:在形成内部写作计划后,执行 \(write\) 动作,撰写该章节的文本。
- 上下文剪枝:一个章节完成后,其对应的源材料会从上下文窗口中被明确移除。这种动态的“检索-剪枝”机制是该方法的核心,它确保写作者的上下文始终高度相关,减轻了上下文溢出的风险,并防止了章节间的干扰。
整个过程在所有章节上分层重复进行,直到写作者输出最终的终止符,标志着报告全部完成。
实验结论
主要成果
如表1和表2所示,WebWeaver在三个主流的OEDR基准测试(DeepResearch Bench, DeepConsult, DeepResearchGym)上均取得了SOTA(state-of-the-art)表现,全面超越了现有的开源和专有系统。
-
在DeepResearch Bench上:该框架在报告质量(如全面性、洞察力)和事实性(如引文准确率)上均表现出色。高达93.37%的引文准确率证明了规划器与写作者的协同作用:规划器将引文ID嵌入大纲,写作者通过分层合成进行靶向检索,大大减少了内容幻觉。
-
在DeepConsult和DeepResearchGym上:该框架同样展示了强大的泛化能力。在DeepConsult上,它以66.86%的胜率取得第一;在DeepResearchGym上,它在深度、广度和支持度等指标上接近满分,最终平均分达到96.7分。这证明了其动态研究循环和分层合成策略的鲁棒性。
| Agent systems | Overall | Comp. | Insight | Inst. | Read. | Eff. c. | C. acc. |
|---|---|---|---|---|---|---|---|
| … (部分基线系统) | … | … | … | … | … | … | … |
| Gemini-2.5-pro-deepresearch | 49.71 | 49.51 | 49.45 | 50.12 | 50.00 | 165.34 | 78.3 |
| WebWeaver (qwen3-30b…) | 46.77 | 45.15 | 45.78 | 49.21 | 47.34 | 26.74 | 25.00 |
| WebWeaver (gpt-oss-120b) | 48.11 | 48.03 | 47.20 | 48.94 | 48.11 | 64.88 | 66.14 |
| WebWeaver (qwen3-235b…) | 50.62 | 51.29 | 51.00 | 49.98 | 48.89 | 166.73 | 78.25 |
| WebWeaver (Claude-sonnet-4…) | 50.58 | 51.45 | 50.02 | 50.81 | 49.79 | 200.75 | 93.37 |
| Agent systems | DeepConsult | DeepResearchGym | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| win | tie | lose | Avg. score | Cla. | Depth | Bal. | Brea. | Sup. | Ins. | Avg. score | |
| … (部分基线系统) | … | … | … | … | … | … | … | … | … | … | … |
| Gemini-2.5-pro-deepresearch | 61.27 | 31.13 | 7.60 | 6.70 | 90.71 | 99.90 | 93.37 | 99.69 | 95.00 | 97.45 | 96.02 |
| WebWeaver (gpt-oss-120b) | 65.31 | 11.22 | 23.47 | 6.64 | 89.78 | 100.00 | 91.91 | 99.66 | 94.94 | 95.06 | 95.0 |
| WebWeaver (Claude-sonnet-4…) | 66.86 | 10.47 | 22.67 | 6.96 | 90.50 | 99.87 | 94.30 | 100.00 | 98.73 | 97.22 | 96.7 |
分析与验证
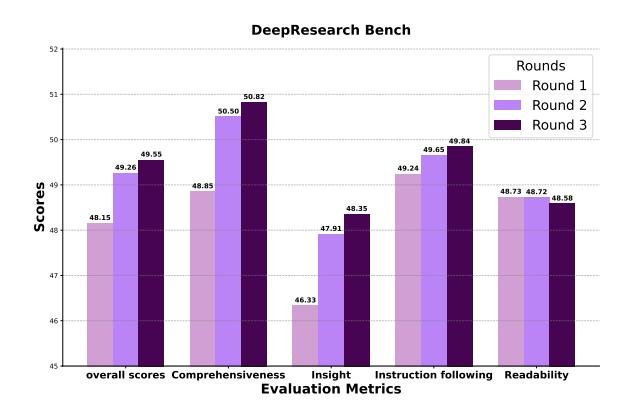
大纲优化的有效性:消融实验表明,随着大纲优化轮次的增加(从1轮到3轮),报告的最终得分(尤其在全面性和洞察力方面)显著提升。这直接证明了迭代优化过程并非冗余,而是提升报告深度和结构的关键机制。
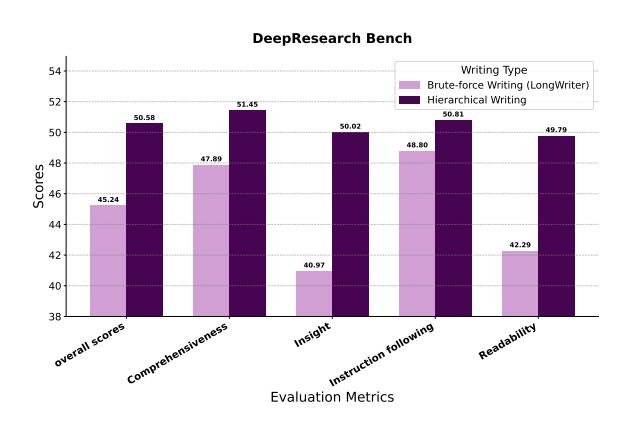
分层写作的优越性:通过与将所有证据一次性输入的“暴力”写作基线(类似LongWriter)进行对比,本文的分层写作方法在所有评估维度上都取得了压倒性优势,特别是在洞察力(40.97 → 50.02)和可读性(42.29 → 49.79)指标上。这证实了“分而治之”的注意力管理策略对于生成高质量长篇报告至关重要。
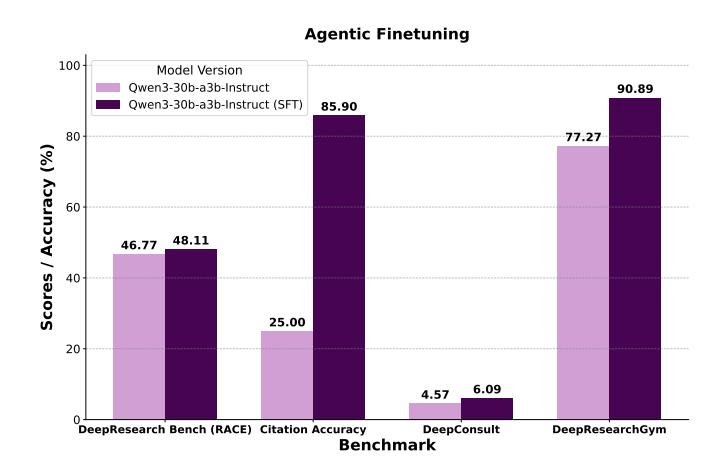
智能体微调(Agentic Finetuning):为了提升小型模型(如30B规模)的性能,本文使用一个强大的教师模型在WebWeaver框架内生成了3.3k条高质量的规划和写作轨迹数据,构成\(WebWeaver-3k\)数据集。在这些数据上对Qwen3-30B模型进行微调后,其性能得到巨大提升,引文准确率从25%跃升至85.90%。这证明了WebWeaver框架的复杂技能(如思考、搜索、写作)是可被“蒸馏”和学习的,使得更小、更易于部署的模型也能达到专家级的性能。
最终结论
本文的WebWeaver框架通过模拟人类认知过程,即规划器的动态研究循环和写作者的分层检索与写作,成功克服了当前深度研究智能体的核心缺陷。实验证明,该方法不仅性能卓越,更重要的是,它为处理信息密集型任务提供了一个新的范式:将棘手的长上下文推理问题,解构为一个由一系列精确动作协调的、系统级的信息管理问题。这项工作为构建能够通过深思熟虑的行动(而非暴力注意力)来驾驭复杂知识的智能体系统提供了新的蓝图。