What Limits Agentic Systems Efficiency?
-
ArXiv URL: http://arxiv.org/abs/2510.16276v1
-
作者: Song Bian; Anand Jayarajan; Gennady Pekhimenko; Shivaram Venkataraman; Minghao Yan
-
发布机构: NVIDIA; University of Toronto; University of Wisconsin-Madison
TL;DR
本文对基于网络交互的智能体系统效率瓶颈进行了实证研究,并提出一个名为 SpecCache 的缓存框架,该框架利用推测性执行(speculative execution)来重叠模型推理与网络环境交互,从而在不降低任务性能的前提下,显著减少系统延迟。
关键定义
- 智能体系统 (Agentic Systems): 指的是将大型语言模型(LLM)的推理能力与外部工具(如网络浏览器、API)交互相结合的系统,旨在解决复杂任务,减轻知识不足和信息过时等问题。
- LLM API 延迟 (LLM API Latency): 指从向 LLM 服务提供商(如 OpenAI)发送请求到接收到完整响应所花费的时间。这是智能体系统中“思考”步骤的主要时间成本。
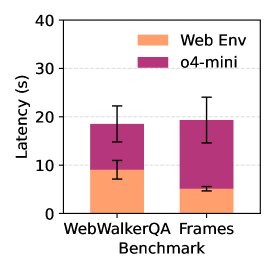
- 网络环境延迟 (Web Environment Latency): 指智能体执行与网络相关的动作(如抓取网页、解析 HTML)所花费的时间。这是智能体系统中“行动”步骤的主要时间成本,本文发现其最高可占总延迟的 53.7%。
- SpecCache: 本文提出的一个缓存框架,旨在减少网络环境延迟。它包含一个动作-观察缓存和一个基于模型的预取机制。
- 推测性执行 (Speculative Execution): SpecCache 的核心机制。它使用一个轻量级的“草稿模型”(draft model)与主要的“目标模型”(target model)并行运行。在目标模型进行推理时,草稿模型预测其可能的下一步动作并提前执行(如预先抓取网页),将结果存入缓存,从而实现模型推理与环境交互时间的重叠。
相关工作
当前,领域内的先进研究主要集中于提升集成网络交互能力的智能体系统的推理性能,例如通过更优的提示工程或强化学习来增强其解决复杂问题的能力。这些系统(如 Search-o1, ReSeaerch)在任务成功率上取得了显著进展。
然而,现有工作普遍忽略了这些系统的系统效率,尤其是端到端延迟问题。高延迟会严重影响用户体验和服务的可靠性,特别是在需要快速响应的应用场景中。本文正是在此背景下,旨在系统性地分析和解决交互式智能体系统的延迟瓶颈,特别是网络环境交互所带来的开销。
本文方法
本文首先通过实证分析,将交互式智能体系统的端到端延迟分解为两大组成部分:LLM API 延迟和网络环境延迟。分析发现,两者都是显著的性能瓶颈,特别是网络环境交互的延迟最高可占总时延的 53.7%。尽管 LLM API 延迟可以通过付费的优先处理(priority processing)等基础设施级优化得到缓解,但网络环境延迟依然是一个棘手的挑战。
为解决网络环境延迟问题,本文提出了 SpecCache,一个结合了缓存与推测性执行的框架。其核心目标是通过重叠模型推理与环境交互来隐藏环境操作的耗时。
设计挑战
设计一个高效的缓存系统面临巨大挑战,主要源于智能体巨大的动作空间。例如,一个网页上可能有数十甚至上百个可点击的链接,这使得精确预测下一个动作变得极为困难。简单的缓存策略(如随机预取)会导致命中率极低,无法有效降低延迟。
SpecCache 框架
SpecCache 框架通过一个精巧的设计来应对上述挑战,其工作流程如下图所示,主要包含两个核心组件:
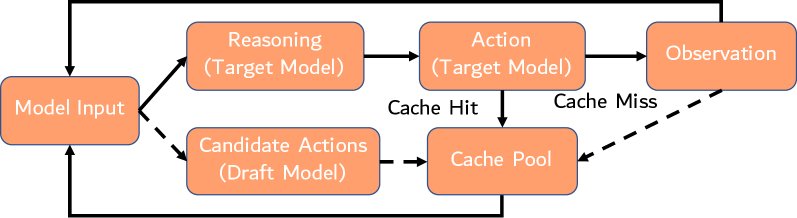
1. 动作-观察缓存 (Action-Observation Cache)
这是一个遵循 LRU (Least Recently Used) 策略的缓存池,用于存储(动作,观察结果)键值对。例如,一个“动作”是点击某个链接,其“观察结果”就是该链接对应页面的内容。当智能体的主模型(目标模型)决定执行一个动作时,它会首先查询该缓存。如果命中,则直接从缓存中获取观察结果,从而避免了与网络环境进行耗时的实时交互。
2. 基于模型的预取 (Model-Based Prefetching)
这是 SpecCache 的创新核心,它采用推测性执行来主动填充缓存。具体实现如下:
- 双模型并行:系统同时运行两个模型——一个强大的目标模型(Target Model,如 GPT-5-mini)负责主要的推理和决策,以及一个轻量、快速的草稿模型(Draft Model,如 GPT-4.1-mini)负责预测。
- 异步预测与执行:当目标模型正在进行耗时的推理(“思考”)时,草稿模型会异步地预测目标模型可能采取的下一个或多个动作。
- 主动缓存:系统会立即执行这些被预测的动作(例如,在后台抓取预测的网页),并将得到的观察结果存入动作-观察缓存中。
- 延迟隐藏:当目标模型完成推理并确定其下一步行动时,如果该行动恰好被草稿模型成功预测,那么所需的数据 уже 在缓存中,智能体可以瞬时获取并继续下一步,从而有效地将网络交互的等待时间隐藏在了模型推理的过程中。
优点
- 效率提升:通过将推理与环境交互并行化,显著减少了智能体等待环境响应的空闲时间,从而降低了端到端延迟。
- 无损性能:SpecCache 是在一个独立的、非阻塞的线程中运行的。即使草稿模型的预测不准确(缓存未命中),它也只会回退到原始的执行路径(即实时执行动作),不会干扰目标模型的推理逻辑或影响最终的任务结果。
- 通用性:该方法基于 ReAct 抽象设计,其原理可推广到任何与外部环境交互且反馈延迟较高的回合制(turn-based)智能体系统。
实验结论
本文通过在 \(WebWalker\) 和 \(MuWC\) 两个基准测试集上的大量实验,验证了所提出方法的有效性。
延迟瓶颈分析
-
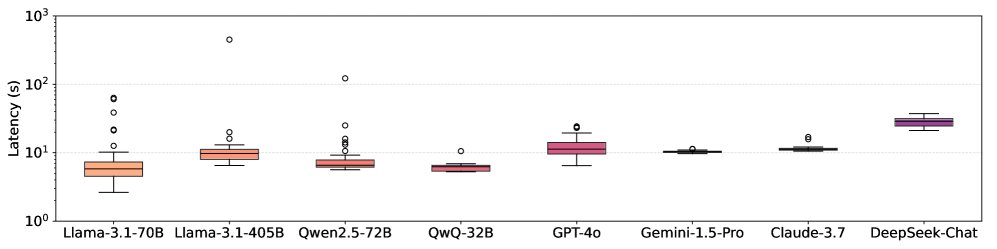
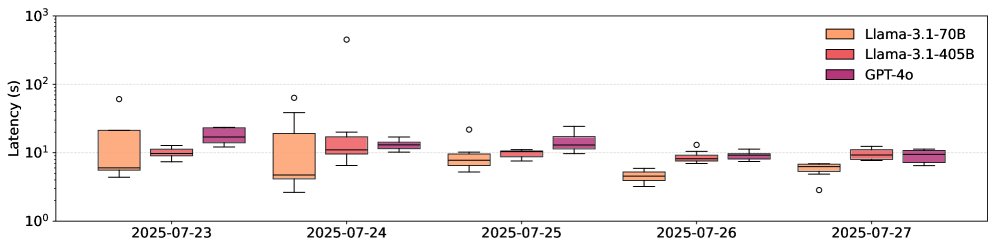
LLM API 延迟高度可变:对来自 5 个提供商的 15 个模型的测试表明,即使是固定长度的请求,API 延迟也可能相差高达 69.21 倍。不同日期和地理位置的延迟差异也很显著。虽然 OpenAI 的优先处理功能有助于降低延迟和方差,但该问题依然存在。
-
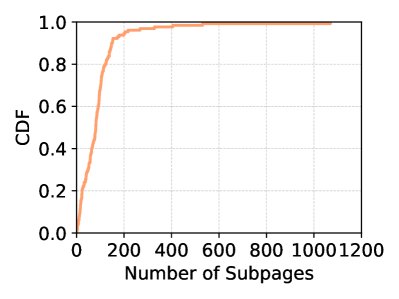
网络环境延迟是主要瓶颈:实验证实,网络抓取和解析的延迟中位数约为 6 秒,在某些情况下占智能体总运行时间的 53.7%。同时,网页的巨大动作空间(子页面数量中位数为 81)给简单缓存带来了挑战。

SpecCache 性能验证
-
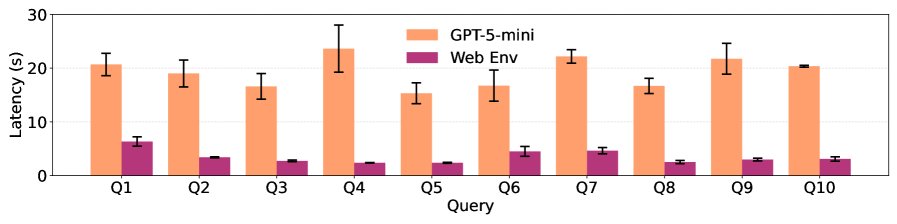
显著降低环境开销:在 \(WebWalker\) 和 \(MuWC\) 基准上,SpecCache 成功将网络环境开销最高减少了 3.2 倍。下图展示了在使用 SpecCache 后,每次迭代的延迟显著降低。


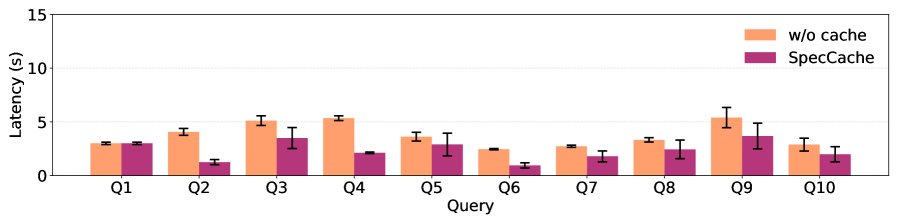
- 缓存命中率大幅提升:与随机采样缓存策略相比,SpecCache 的缓存命中率提升巨大。在 \(WebWalker\) 基准上,SpecCache 实现了 83.3% 的命中率,而随机策略仅为 8.9%;在 \(MuWC\) 基准上,SpecCache 的命中率也达到了 54.0%,远超随机策略的 1.0%,提升高达 58 倍。
- 不影响任务性能:实验证实,SpecCache 在提升效率的同时,不会改变智能体系统的原始执行轨迹,因此不会对任务的最终成功率或结果产生负面影响。
最终结论
本文的实证研究首次量化了交互式智能体系统中的两大延迟来源,并证明网络环境交互是除 LLM API 之外的关键性能瓶颈。提出的 SpecCache 框架通过创新的推测性执行机制,有效地将这一瓶颈的开销隐藏起来,为加速智能体系统开辟了一个新的方向:通过异步的辅助计算来重叠推理与环境交互,从而在保证任务质量的同时,大幅提升系统效率。