WizardCoder: Empowering Code Large Language Models with Evol-Instruct
-
ArXiv URL: http://arxiv.org/abs/2306.08568v2
-
作者: Daxin Jiang; Ziyang Luo; Can Xu; Wenxiang Hu; Qingwei Lin; Jing Ma; Qingfeng Sun; Pu Zhao; Chongyang Tao; Xiubo Geng
-
发布机构: Hong Kong Baptist University; Microsoft
TL;DR
本文提出了一种名为 \(Code Evol-Instruct\) 的方法,通过自动进化和增强编程指令的复杂性,来精调(fine-tune)代码大语言模型,从而创造出在多个基准测试中性能卓越的 \(WizardCoder\) 模型系列。
关键定义
本文的核心是围绕 \(Code Evol-Instruct\) 这一新方法展开的,并由此产生了 \(WizardCoder\) 模型。
-
Code Evol-Instruct: 一种为代码领域专门设计的指令进化(instruction-evolution)方法。它借鉴了通用领域 \(Evol-Instruct\) 的思想,但针对编程任务的特点进行了深度定制。该方法利用一个强大的“进化执行模型”(如 GPT-3.5),根据一套精心设计的启发式规则,自动地将一个简单的初始代码指令(例如,一个编程问题)重写成一个更复杂、更有深度、更具挑战性的版本。
-
WizardCoder: 指通过 \(Code Evol-Instruct\) 方法生成的高复杂度指令数据集,对现有开源代码大语言模型(如 StarCoder, CodeLlama)进行指令精调后得到的新模型系列。本文发布的模型包括 \(WizardCoder-15B\) 和 \(WizardCoder-34B\) 等。
相关工作
-
研究现状: 当前,大型代码语言模型(Code Large Language Models, Code LLMs),如 StarCoder 和 CodeLlama,已在代码理解和生成任务中取得显著成就。然而,与通用大语言模型(LLMs)相比,在代码领域的指令精调技术仍未得到充分研究。这导致了现有最强的开源代码模型在性能上依然显著落后于顶尖的闭源模型(如 GPT-4, Claude)。
-
待解决问题: 本文旨在解决一个核心问题:如何通过指令精调有效提升开源代码大语言模型的性能,以缩小其与闭源模型之间的差距。作者认为,现有指令数据集(如 Code Alpaca)的指令复杂度不足,未能充分挖掘基础模型的潜力。因此,本文的目标是创建一种能够自动生成更复杂、更多样化代码指令的方法,从而更有效地训练代码模型。
本文方法
本文的核心贡献是 \(Code Evol-Instruct\) 方法,它通过迭代进化来提升代码指令的质量,并用此数据训练出 \(WizardCoder\) 模型。
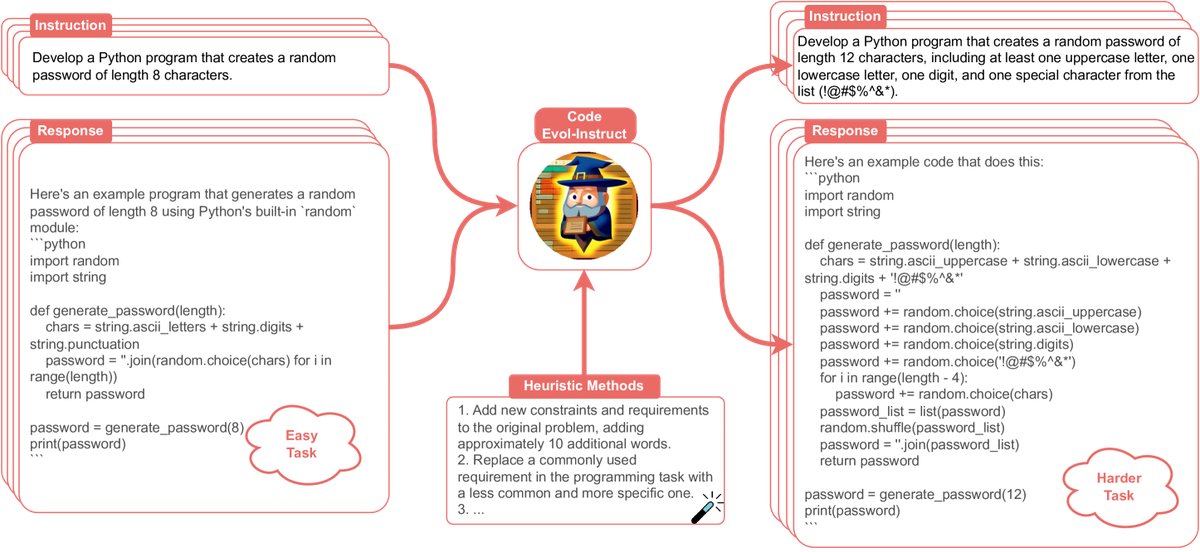 图注:Code Evol-Instruct 方法示意图。
图注:Code Evol-Instruct 方法示意图。
方法流程
整个流程分为两个步骤:
- 指令进化: 首先,以一个基础的代码指令数据集(本文使用 Code Alpaca)作为种子。然后,应用 \(Code Evol-Instruct\) 技术对这些指令进行迭代式进化。
- 模型精调: 使用进化产生的高复杂度指令数据集,对预训练好的开源代码大语言模型(如 StarCoder 和 CodeLlama)进行精调,最终得到 \(WizardCoder\) 模型。
创新点:Code Evol-Instruct 的设计
\(Code Evol-Instruct\) 的创新之处在于其专为代码任务设计的进化策略。它通过一个特定的提示模板,驱动一个大型语言模型(如 GPT-3.5)来增强指令难度。
进化提示词模板: ``\(Please increase the difficulty of the given programming test question a bit. You can increase the difficulty using, but not limited to, the following methods: {method} {question}\)`\(其中,\){question}\(是待进化的原始指令,\){method}$$ 是从以下五种专门设计的代码进化启发式方法中随机选择一种:
- 增加约束: 为原问题增加新的约束和要求(约增加10个词)。
- 替换需求: 将一个编程任务中常用的需求替换为一个不常用且更具体的需求。
- 深化推理: 如果原问题只需少量逻辑步骤即可解决,则增加更多的推理步骤。
- 引入误导: 提供一段错误的代码作为参考,以增加迷惑性(一种对抗性样本思路)。
- 提升复杂度要求: 提出更高的时间或空间复杂度要求(但不频繁使用)。
训练过程
训练数据集的构建始于 Code Alpaca 数据集。通过 \(Code Evol-Instruct\) 对其进行多轮迭代进化,每一轮进化产生的数据都会与之前所有轮次的数据及原始数据合并,用于模型精调。训练过程中会使用一个外部开发集来判断何时停止进化(Evol Stop),以防性能下降。
精调提示词格式: \(`\) Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
Instruction:
{instruction}
Response:
\(`\)
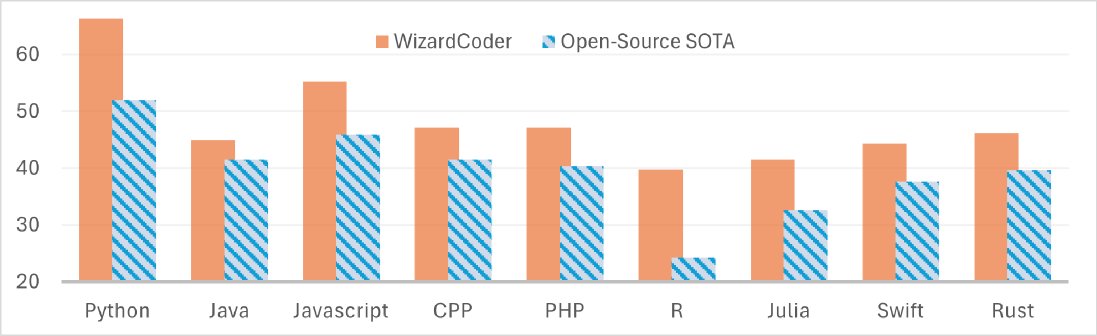 图注:WizardCoder-34B 在多种编程语言上相较于当时的开源SOTA模型(CodeLlama-34B系列)展现出显著优势。
图注:WizardCoder-34B 在多种编程语言上相较于当时的开源SOTA模型(CodeLlama-34B系列)展现出显著优势。
实验结论
本文在 HumanEval、HumanEval+、MBPP、DS-1000 和 MultiPL-E 五大代码生成基准上进行了全面评估,实验结果充分验证了 \(WizardCoder\) 的卓越性能。
核心实验结果
-
超越开源模型: 在所有五个基准测试中,\(WizardCoder\) 系列模型(15B和34B)的性能均大幅超越了所有其他的开源代码大语言模型,成为新的开源 SOTA。
-
媲美甚至超越闭源模型:
- \(WizardCoder-15B\) 在 HumanEval 和 HumanEval+ 基准上的 \(pass@1\) 分数超过了著名的闭源模型 Anthropic Claude 和 Google Bard。
- \(WizardCoder-34B\) 在 HumanEval 上的分数与 GPT-3.5 (ChatGPT) 相当,在测试用例更丰富的 HumanEval+ 上则超越了 GPT-3.5。
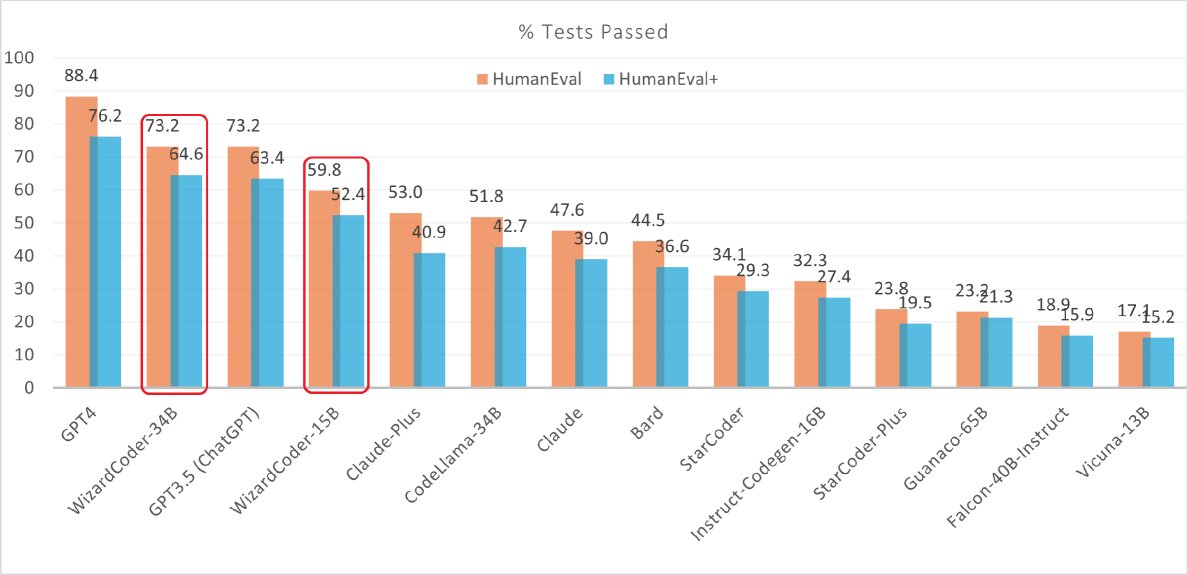 图注:在 EvalPlus 排行榜上,WizardCoder-34B 在 HumanEval+ 上的表现优于 GPT-3.5,仅次于 GPT-4。
图注:在 EvalPlus 排行榜上,WizardCoder-34B 在 HumanEval+ 上的表现优于 GPT-3.5,仅次于 GPT-4。
- 多语言和特定领域能力:
- 在 MultiPL-E 基准上,\(WizardCoder\) 在8种不同的编程语言(如Java, C++, Rust等)中均表现出最强的性能。
- 在数据科学基准 DS-1000 上,\(WizardCoder-15B\) 在代码插入(insertion)任务上同样显著优于其他模型。
| 模型 | 参数 | HumanEval | MBPP |
|---|---|---|---|
| 闭源模型 | |||
| GPT-3.5 (ChatGPT) | 未知 | 48.1 | 52.2 |
| GPT-4 | 未知 | 67.0 | - |
| 开源模型 | |||
| StarCoder-15B | 15B | 33.6 | 43.6* |
| CodeLlama-Python-34B | 34B | 53.7 | 56.2 |
| WizardCoder (本文) | 15B | 57.3 | 51.8 |
| WizardCoder (本文) | 34B | 71.5 | 61.2 |
表注:在 HumanEval 和 MBPP 基准上的 pass@1 (%) 结果对比。
深入分析与结论
-
性能增益来源: 分析实验表明,性能的提升确实来源于指令复杂度的增加,而不是简单的样本数量或 Token 数量的增加。在控制样本或 Token 数量相等的情况下,使用进化后数据训练的模型性能远超使用原始数据的模型。
-
与测试集相似度无关: 分析显示,进化过程并未使训练数据与测试集(HumanEval)的相似度提高。这排除了“数据泄露”或“过拟合测试集”的可能性,证明了模型泛化能力的真实提升。
-
进化轮数的影响: 实验发现,进化并非越多越好。性能通常在进化3轮左右达到峰值,之后趋于平稳或略有下降。
-
最终结论: \(Code Evol-Instruct\) 是一种极其有效的指令微调方法,它通过提升指令复杂度,成功地将开源代码模型的性能提升到了一个新的高度。尽管与 GPT-4 仍有差距,但 $$WizardCoder` 显著缩小了开源与顶尖闭源模型之间的鸿沟。