xLLM Technical Report
-
ArXiv URL: http://arxiv.org/abs/2510.14686v1
-
作者: Weizhe Huang; Liangyu Liu; Guyue Liu; Jun Zhang; Ziyue Wang; Yunlong Wang; Ke Zhang; Hailong Yang; Keyang Zheng; Yifan Wang; 等35人
-
发布机构: BUAA; JD.com; Peking University; Tsinghua University; USTC
TL;DR
本文提出了一种名为 xLLM 的智能高效的大语言模型推理框架,其采用创新的服务-引擎解耦架构,通过智能调度与系统级协同优化,专为高性能、大规模的企业级服务而设计,解决了混合负载、资源利用率低和硬件适配性差等核心挑战。
关键定义
本文提出或深度应用了以下几个核心概念:
- PD分离 (Prefill-Decode Disaggregation):一种推理架构,将处理提示(Prefill阶段)和生成Token(Decode阶段)的计算任务分配到不同的实例组中,以避免长时Prefill任务阻塞对延迟敏感的Decode任务,从而优化整体性能。
- 动态PD分离 (Dynamic PD Disaggregation):本文提出的一种自适应调度策略。它不再静态划分Prefill和Decode实例,而是根据实时工作负载(如请求队列、TTFT/TPOT指标)动态调整处理Prefill和Decode任务的实例比例,并支持实例角色的快速切换,以应对流量波动。
- EPD分离 (Encode-Prefill-Decode Disaggregation):本文专为多模态请求设计的创新分离策略。它将多模态输入的处理过程分解为三个独立的阶段:编码(Encode)、预填充(Prefill)和解码(Decode),并根据性能分析结果智能地选择最佳的组合或分离执行方式(如EP-D, ED-P, E-P-D),以实现吞吐量和延迟的最佳平衡。
- xTensor内存管理:一种创新的KV Cache管理方案,其核心思想是“逻辑连续,物理离散”。它为每个请求按需分配物理离散的内存页来存储KV Cache,但在逻辑上维持其连续性,从而解决了动态内存分配需求与高效访存之间的矛盾。
- 在离线混合部署 (Online-Offline Co-location):一种调度策略,将对延迟敏感的在线推理任务和非实时的离线批量任务部署在共享的资源池中。通过在线任务抢占和离线任务利用空闲资源,最大限度地提高集群整体资源利用率。
相关工作
当前主流的大语言模型推理框架在企业级服务场景中面临严峻挑战。
- 服务层面的挑战:
- 混合负载处理效率低:现有调度系统难以在保障在线服务SLO(服务等级目标)的同时,有效利用其流量低谷期的空闲资源来处理离线任务,导致集群资源利用率不高。
- 静态资源分配不灵活:传统的PD分离架构通常静态配置资源,无法适应真实应用中请求负载(如输入输出长度)的动态剧烈变化,导致硬件利用率低和SLO违规风险增加。
- 多模态请求支持不足:缺乏针对多模态输入(如图像、文本)的高效服务策略,特别是对编码(Encode)阶段的并行处理和细粒度资源分配。
- 大规模集群稳定性差:随着集群规模扩大,如何实现快速的节点故障检测和服务恢复,以保障推理服务的高可用性,成为一个关键问题。
- 引擎层面的挑战:
- 硬件算力利用不充分:现有推理引擎难以完全榨干现代AI加速器的计算单元性能。
- MoE模型扩展性受限:混合专家(MoE)模型中的All-to-All通信开销和专家负载不均衡问题,限制了系统的推理可扩展性。
- KV Cache管理效率瓶颈:随着模型上下文窗口不断扩大,高效的KV Cache管理成为影响性能的关键。
- 数据并行负载不均:在数据并行(DP)部署中,由于请求的不可预测性,静态调度策略难以有效平衡各计算单元的负载。
本文提出的 xLLM 框架旨在系统性地解决上述服务层和引擎层的挑战,实现高效、智能、可靠的企业级LLM推理服务。
本文方法
xLLM框架的核心设计是服务-引擎解耦架构 (service-engine decoupled design)。xLLM-Service负责智能调度和资源管理,而xLLM-Engine则负责高效执行推理计算。
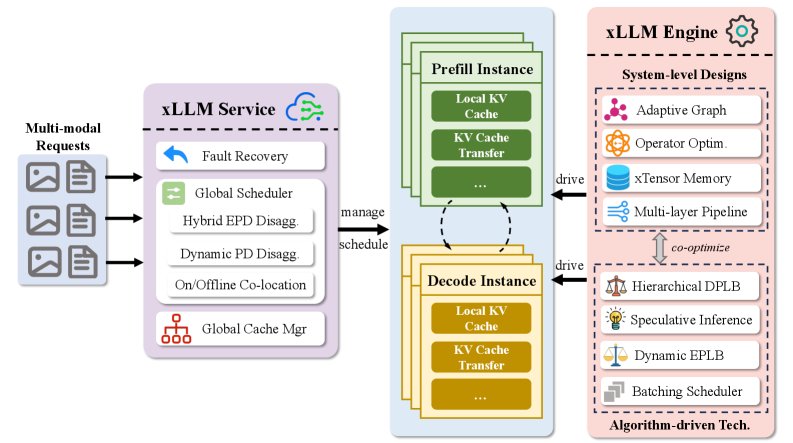
xLLM-Service
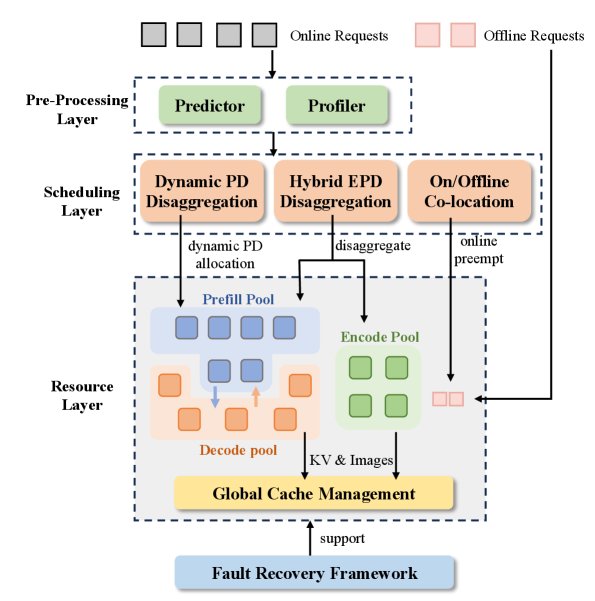
xLLM-Service 旨在实现高效、弹性和高可用的请求调度与资源管理。其工作流程如下图所示,主要包括请求预处理、智能调度和资源层。
其主要创新点包括:
弹性实例池 (Elastic Instance Pools)
集群中的实例被划分为三个弹性的逻辑池:Prefill池、Decode池和为多模态设计的Encode池。实例本身是无状态的(stateless),可以根据处理的请求类型在不同角色(如处理Prefill或Decode任务)之间灵活切换,而无需物理迁移或重启,实现了资源的动态调度。
智能调度策略
调度层包含三个核心策略,以应对不同场景:
-
在离线混合部署调度策略 (Online-Offline Co-location Policy):该策略采用抢占式调度。在线请求拥有高优先级,可在流量高峰期抢占离线任务的资源。在流量低谷期,离线任务则充分利用空闲资源。特别地,本文提出一种延迟约束解耦架构 (latency-constrained decoupled architecture),允许离线任务的Decode阶段在Prefill池或Decode池中执行,通过灵活调度来平衡两类池的负载,最大化集群利用率。
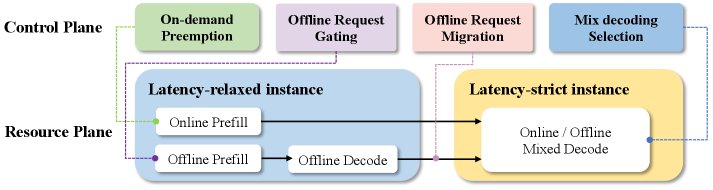
-
动态PD分离调度策略 (Dynamic PD Disaggregation Policy):为解决静态PD分离的低效问题,该策略引入了实时监控和自适应调整机制。它通过监控TTFT(首Token时间)、TPOT(每Token输出时间)等性能指标,并结合一个TTFT预测器,来动态评估Prefill和Decode阶段的负载。当检测到瓶颈时(如TTFT不满足SLO),它会触发实例的角色切换,例如将部分Decode实例临时转为Prefill实例,反之亦然。这种基于无状态实例的“零等待”角色切换,避免了传统方案中重启实例带来的高昂延迟。
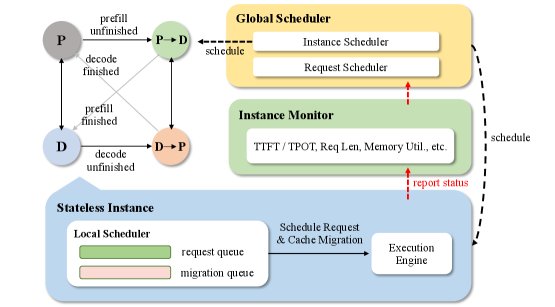
-
混合EPD分离策略 (Hybrid EPD Disaggregation Policy):针对多模态请求,该策略首先通过一个EPD分析器(Profiler)离线搜索出最优的阶段分离配置(例如,是将Encode和Prefill合并执行,还是三阶段完全分离)。然后,调度器根据此配置将任务分派到对应的实例池中。该设计使得多模态请求也能受益于动态PD分离的弹性调度能力。
其他关键设计
- 以KV为中心的存储架构 (KV-centric Storage Architecture):采用HBM-DRAM-SSD混合存储架构来缓存KV值和图像Token。在全局层面,实现了跨实例的KV Cache路由和复用,从而扩大了KV缓存容量并提高命中率。
- 高效的容错机制 (Efficient Fault-tolerant):框架支持对E、P、D三类实例池的故障检测和快速恢复。对于失败实例上的请求,系统能自动决策最优的KV Cache重计算或迁移策略,保障服务的高可用性。
xLLM-Engine
xLLM-Engine负责执行具体的推理计算,通过系统和算法层面的协同优化,充分压榨硬件性能。
系统层优化
- 多层流水线执行引擎 (Multi-layer Pipeline Execution Engine):
- 框架层:通过CPU任务与AI加速器计算的异步调度,形成流水线,减少计算空泡。
- 模型图层:将单个批次拆分为微批次(micro-batch),利用双流并行机制使计算和通信重叠。
- 算子层:在不同计算单元间实现流水线操作,让计算和内存访问重叠。
- 面向动态输入的图优化 (Graph Optimization for Dynamic Inputs):将解码阶段的多个小算子(kernel)融合成一个统一的计算图,通过一次性下发来大幅减少算子启动开销。同时,通过参数化输入维度和多图缓存方案来适应动态变化的序列长度和批量大小。
- xTensor内存管理:采用“逻辑连续,物理离散”的KV存储结构。在Token生成过程中按需分配物理内存页,同时异步预测并智能映射下一Token所需的物理页。请求结束后,物理内存被立即复用,有效解决了内存碎片和分配冲突问题。
算法层优化
- 推测解码 (Speculative Decoding):集成并优化了推测解码算法,通过一次生成多个Token来提升吞吐量。在架构上通过异步CPU处理和减少数据传输等方式进一步优化。
- 专家并行负载均衡 (EP Load Balance):对于MoE模型,根据历史专家负载统计数据来动态更新专家权重,实现有效的推理时动态负载均衡。
- 数据并行负载均衡 (DP Load Balance):在数据并行部署中,通过感知KV Cache的实例分配、跨DP实例的请求迁移以及DP内部计算单元的分配,实现细粒度的负载均衡。
实验结论
- 性能优势显著:在相同的TPOT(每Token输出时间)约束下,xLLM在Qwen系列模型上的吞吐量最高可达MindIE的1.7倍和vLLM-Ascend的2.2倍。在Deepseek系列模型上,其平均吞吐量是MindIE的1.7倍。
- 场景优化效果:针对京东的核心业务之一——生成式推荐场景,通过主机-算子操作重叠等特定优化,xLLM实现了23%的性能提升。
- 最终结论:大量的评估结果证明,xLLM在性能和资源效率方面均表现出显著的优越性。该框架已成功在京东内部署,支持了AI聊天机器人、营销推荐、商品理解、客服助手等一系列核心业务场景,验证了其在企业级大规模应用中的有效性和稳定性。