A Circular Argument : Does RoPE need to be Equivariant for Vision?
颠覆RoPE核心信仰:等变性不再神圣?Spherical RoPE性能持平甚至反超
大模型时代,旋转位置编码 (Rotary Positional Encodings, RoPE) 无疑是Transformer架构中的明星技术。从LLaMA到DeepSeek,几乎所有顶尖语言模型都依赖它来感知Token的顺序。
论文标题:A Circular Argument : Does RoPE need to be Equivariant for Vision? ArXiv URL:http://arxiv.org/abs/2511.08368v1
人们普遍认为,RoPE的成功秘诀在于其优雅的“相对位置”特性,即位移等变性(shift-equivariance)。这意味着模型关注的是Token间的相对距离,而非其绝对位置。
然而,当我们将目光从一维文本转向二维图像时,一个根本性的问题浮出水ar面:这种对“等变性”的执着,是否只是一个“循环论证”?我们之所以构建保持等变性的视觉RoPE,仅仅是因为我们假设等变性是其性能的关键?
一篇新论文对这一AI领域的“常识”发起了直接挑战。研究者们通过严谨的数学推导和实验,得出了一个颠覆性的结论:在视觉任务中,RoPE的等变性可能并非其成功的关键因素。
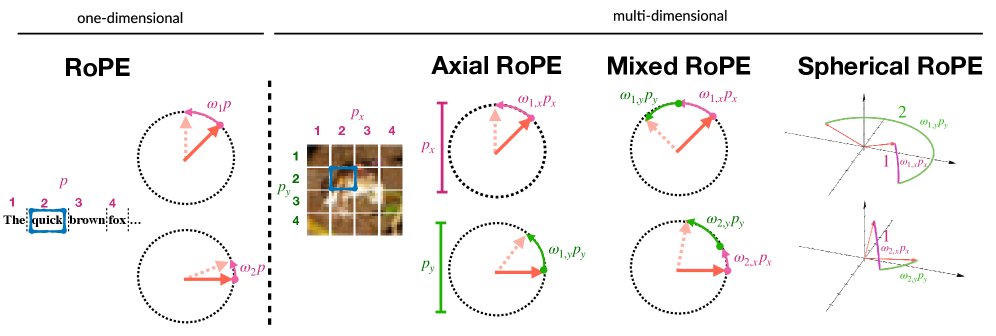
从1D到2D:RoPE的视觉窘境与演进
RoPE最初是为一维文本序列设计的。它通过在embedding的不同维度上应用旋转矩阵来编码位置信息,其巧妙之处在于,两个位置的Attention得分仅与它们的相对距离 $p_i-p_j$ 有关。
但图像是二维的。如何将RoPE扩展到二维空间,同时保持等变性,成了一个棘手的问题。社区为此提出了几种方案:
- Axial RoPE:最直接的方法。将embedding维度一分为二,一半用于编码 $x$ 轴位置,另一半编码 $y$ 轴位置。但这种方法无法捕捉对角线方向上的“混合”信息。
- Mixed RoPE:为了解决Axial RoPE的局限,Mixed RoPE允许每个维度对同时受到 $x$ 和 $y$ 位置的影响,通过学习不同的旋转频率组合,来表达更丰富的空間關係。
- LieRE:从李代数的视角出发,将RoPE推广到更高维的旋转。它在数学上最为通用,但却不保证一定满足等变性。
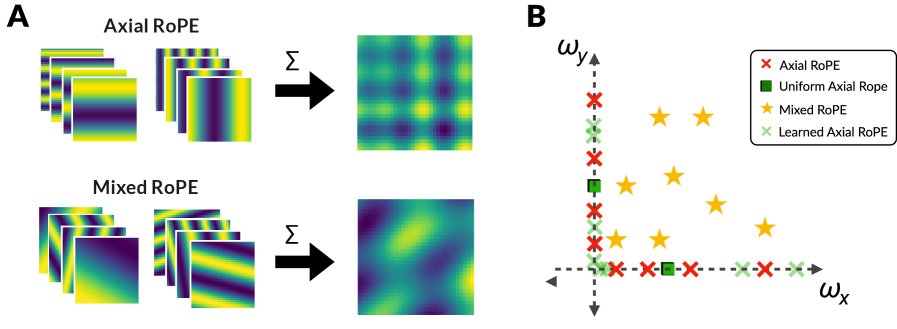
重新审视等变性:一个数学洞察
本文首先从理论上剖析了上述方法的内在联系。研究者证明:
- 在一维情况下,最通用的LieRE其实等价于带有可学习频率的RoPE。
- 在多维情况下,要让LieRE保持等变性,其 underlying 的生成器矩阵 (generators) 必须满足可交换性(commutative)。
- 当满足这个可交换性约束时,LieRE就退化成了Mixed RoPE。
这个推导得出了一个关键结论:Mixed RoPE是所有保持等变性的多维旋转位置编码中最通用的形式。
然而,这也暴露了问题的核心:为了维持“等变性”这一我们 preconceived 的優点,我们必须给模型加上“可交换性”的枷Lock。但如果这个前提本身就不那么重要呢?
打破循环:Spherical RoPE登场
为了打破这个“性能好因为等变,新设计要等变因为性能好”的循环,研究者设计了一场精妙的对照实验。
他们提出了Spherical RoPE,一种故意打破等变性的新方法。
与Mixed RoPE在二维平面上操作向量对不同,Spherical RoPE在三维空间中操作向量三元组。它先后围绕两个不同的轴(分别由 $p_x$ 和 $p_y$ 控制)进行旋转。
\[\varphi(\mathbf{z}_{d},\mathbf{p})=\mathcal{Y}_{\omega_{dx}x}\mathcal{R}_{\omega_{dy}y}\mathbf{q}_{d}\]关键在于,三维空间中的旋转通常是不可交换的。先绕x轴转再绕y轴转,与先绕y轴转再绕x轴转,结果完全不同。这种设计在保留旋转特性的同时,精准地破坏了严格的等变性。
通过比较Mixed RoPE(最通用的等变版本)和Spherical RoPE(精心设计的非等变版本),研究者可以直接检验等变性本身究竟有多大贡献。
实验结果:等变性真的重要吗?
研究者在CIFAR100和ImageNet数据集上,使用标准的ViT-S架构对多种位置编码方法进行了评估。结果令人惊讶:
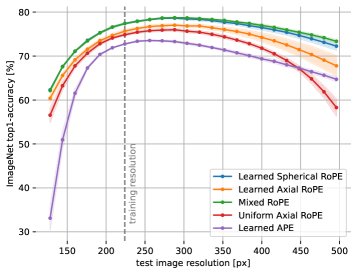
从上图可以看出:
- Spherical RoPE(非等变,橙色/绿色) 的性能与 Mixed RoPE(等变,蓝色) 不相上下,甚至在某些情况下略微超出。
- 这两种方法都显著优于Axial RoPE(等变但受限,紫色)。这表明,能否捕捉斜向信息(oblique directions)比是否保持等变性更重要。
- 在数据量较小的情况下,非等变的Spherical RoPE甚至表现最佳,这进一步削弱了“等变性作为一种有效的归纳偏置(inductive bias)”的说法。
这些结果共同指向一个结论:在视觉Transformer中,RoPE的性能优势可能主要源于其旋转机制本身,而非严格的位移等变性。
结论与启示
这项研究有力地挑战了AI社区关于RoPE位置编码的一个核心信念。它告诉我们,在将NLP中的成功经验迁移到CV领域时,必须审慎地验证其背后的基本假设。
对于视觉任务而言,我们或许不必再执着于构造复杂的、满足严格等变性的位置编码方案。像Spherical RoPE这样更简单、甚至非等变的设计,可能同样有效,甚至更优。
这一发现为未来视觉Transformer的位置编码研究打开了新的大门,鼓励研究者们摆脱“等变性”的束缚,探索更高效、泛化能力更强的模型架构。也许,最好的位置编码,就是那个不再“循环”的编码。