终结AI幻觉:全面剖析大模型“胡说八道”的根源与应对策略

你是否曾被AI一本正经的胡说八道给惊到?当它为你生成一篇看似完美的文章,却在关键事实上张冠李戴;或者在回答问题时,自信满满地编造出一个不存在的概念。这种现象,正是当前大型语言模型(LLM)面临的最大挑战之一——幻觉(Hallucination)。
ArXiv URL:http://arxiv.org/abs/2512.02527v1
它如同一片阴影,笼罩在人工智能的光环之上,严重影响了模型的可靠性。那么,AI幻觉究竟从何而来?我们又该如何应对?今天,就让我们跟随一篇最新的综述论文,一探究竟。
什么是AI幻觉?
简单来说,AI幻觉指的是模型生成了看似合理、流畅,但实际上与事实不符、逻辑不通或无中生有的内容。
研究人员将幻觉大致分为两类:
-
事实性幻觉(Factual Hallucination):这是最常见的一种,即模型提供了虚假或错误的信息。比如,它可能会说“爱因斯坦在2001年获得了诺贝尔物理学奖”。
-
逻辑性幻觉(Logical Hallucination):指模型生成的内容在内部存在矛盾或逻辑不连贯。比如,在一段文字中,它可能先说A大于B,后面又说B大于A。
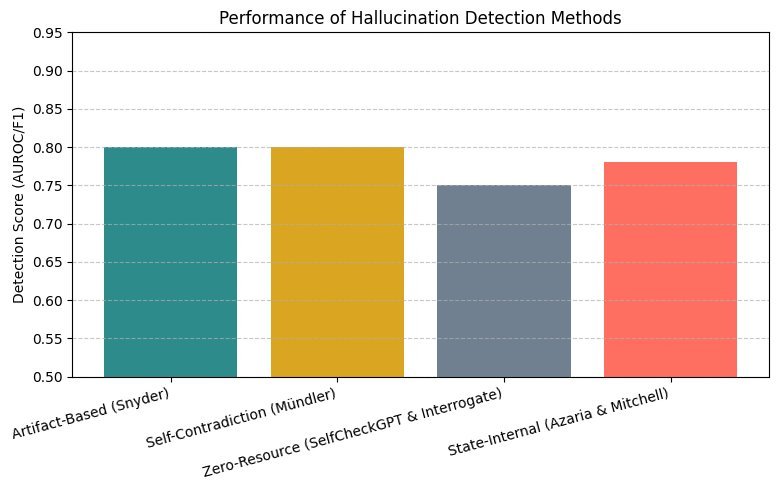
这些幻觉不仅会误导用户,更在医疗、金融等高风险领域埋下巨大隐患。想象一下,如果一个用于医疗诊断的AI模型产生了幻觉,后果将不堪设想。
为什么LLM会产生幻觉?
幻觉并非AI“有意为之”,而是其底层机制和训练数据共同作用的结果。其根源主要有以下几点:
-
训练数据的“原罪”:LLM的学习材料来自广阔的互联网,其中包含了大量错误、过时甚至矛盾的信息。模型在学习过程中,不可避免地会将这些“噪声”也一并吸收。
-
模型架构的局限:像GPT系列这样的生成式模型,其核心任务是预测下一个最有可能出现的词(Token)。它更关心文本的流畅性和相关性,而非事实的准确性。这使得它有时会为了“凑”出一个通顺的句子而“创造”事实。
-
知识的静态性:模型一旦训练完成,其内部知识就被固定下来。对于训练截止日期之后的新知识或动态变化的事实,模型无法感知,从而导致信息过时。
-
指令的模糊性:当用户提出的问题(Prompt)含糊不清或存在歧义时,模型为了给出答案,只能进行猜测和推断,这极大地增加了产生幻觉的风险。
有趣的是,不同的模型产生幻觉的倾向也不同。例如,GPT系列模型在生成流畅、连贯的文本方面表现出色,但也更容易“自由发挥”而产生事实性幻觉。相比之下,采用双向训练的BERT模型在特定任务上幻觉率较低,但其生成新内容的能力也相对受限。
对抗幻觉:我们有哪些武器?
为了驯服这头“幻觉猛兽”,研究者们开发出了一系列精密的策略。这些方法可以概括为四大类,形成了一个多层次的防御体系。
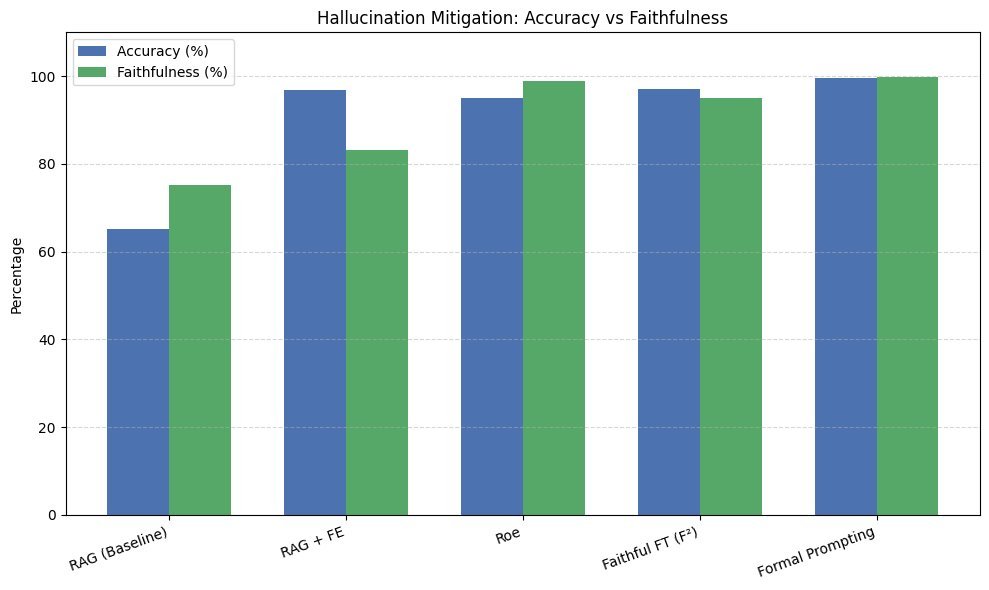
1. 优化训练与微调(Fine-tuning)
这是从模型自身入手的方法。通过在高质量、经过事实核查的数据集上进行微调,可以“教导”模型更注重事实准确性,从而减少幻觉。
2. 引入外部知识(Knowledge Grounding)
既然模型内部知识有限,何不让它学会“查资料”?这就是检索增强生成(Retrieval-Augmented Generation, RAG)的核心思想。当模型接收到一个问题时,它首先从一个可靠的知识库(如企业内部文档、权威数据库)中检索相关信息,然后基于这些信息来生成答案。这大大降低了模型凭空捏造的可能性。
3. 强化学习与反馈(Reinforcement Learning)
通过人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF),我们可以让模型学会分辨“好答案”和“坏答案”。当模型产生幻觉时,人类评估者会给予负反馈,模型通过不断试错和调整,逐渐学会生成更真实、可靠的内容。
4. 精心设计提示(Prompt Engineering)
这是用户端最直接有效的方法。通过设计清晰、具体、信息量充足的提示,可以极大地引导模型走向正确的方向。例如,在提示中提供背景信息、明确回答格式、或要求模型引用信源,都能有效抑制幻觉的产生。
这四种方法相辅相成,共同构筑起对抗AI幻觉的坚固防线。
如何衡量幻觉的严重程度?
要解决问题,首先得能衡量问题。目前,学术界正在建立更全面的幻觉评估框架。这不仅仅是简单地检查事实对错,还包括:
-
一致性分析:评估模型生成内容的内在逻辑是否自洽。
-
事实性检查:将模型输出与可信的知识源进行比对。
-
用户体验评估:通过真人评估,判断生成内容的可信度和实用性。
通过这些多维度的评估,我们可以更准确地了解一个模型在控制幻觉方面的能力。
实践建议与未来展望
那么,在实际应用中我们该如何选择和使用LLM呢?
研究给出的建议是:具体任务,具体分析。
-
对于通用聊天或创意写作等对事实性要求不高的场景,GPT-4或PaLM等模型因其出色的流畅性和创造力而成为首选。
-
对于信息检索、知识问答等需要高度事实准确性的应用,基于BERT或T5架构、并结合了RAG等技术的模型可能更为可靠。
未来,研究的重点将转向更智能的幻觉检测与修复机制,以及开发更具透明度的AI系统。例如,让用户可以轻松地质疑和核实模型的回答,甚至参与到纠正幻觉的过程中。
结语
AI幻觉是大型语言模型发展道路上一个无法回避的挑战。它既是技术局限的体现,也是我们通往更可靠、更值得信赖的通用人工智能的必经之路。
正如这篇综述所展示的,学术界和工业界正从模型、数据、算法到应用等多个层面,全方位地向幻觉“宣战”。这场战斗远未结束,但每一点进步,都意味着我们离那个能够真正信赖AI的未来更近了一步。