A Definition of AGI
-
ArXiv URL: http://arxiv.org/abs/2510.18212v1
-
作者: Ziwei Liu; Long Phan; Max Tegmark; Andy Zou; Eric Schmidt; Yarin Gal; Matthias Hein; Alexander Pan; Cihang Xie; Erik Brynjolfsson; 等28人
-
发布机构: Beneficial AI Research; CSER; Carnegie Mellon University; Center for AI Safety; Conjecture; Cornell University; Gray Swan AI; HKUST; Hong Kong Baptist University; Institute for Applied Psychometrics; KAIST; LG AI Research; LawZero; Massachusetts Institute of Technology; Morph Labs; Nanyang Technological University; New York University; Stanford University; University of California; University of California, Berkeley; University of Chicago; University of Michigan; University of Oxford; University of Toronto; University of Tübingen; University of Washington; University of Wisconsin–Madison; Université de Montréal; Vector Institute
TL;DR
本文提出了一个可量化的框架来定义和衡量通用人工智能(AGI),即将其定义为在认知通用性(versatility)和熟练度(proficiency)上与受过良好教育的成年人相匹配的系统,并通过借鉴人类心理测量学中的CH-C认知能力理论,将通用智能分解为十个核心认知域进行评估。
关键定义
- 通用人工智能 (Artificial General Intelligence, AGI): 本文将其操作化定义为一个AI系统,它能在广泛的认知任务中展现出与受过良好教育的成年人相当的通用性和熟练度。AGI的实现标准(100% AGI Score)是能够完成人类认知能力测试中的所有任务。
- Cattell-Horn-Carroll (CHC) 理论: 这是心理测量学中关于人类认知能力结构的最具经验验证的理论。它将人的智力描绘成一个层次化的分类图,包含多个广泛能力和众多狭窄能力。本文以此理论为基础,构建了评估AI认知能力的框架。
- AGI分数 (AGI Score): 一个从0%到100%的标准化分数,用于量化AI系统与AGI定义的差距。100%表示AI在所有十个评估维度上都达到了受过良好教育的成年人的水平。
- 锯齿状认知剖面 (Jagged Cognitive Profile): 指当前AI模型在不同认知能力上表现出极不均衡的现象。它们在某些知识密集型领域表现出色,但在其他基础认知能力(如长期记忆)上却存在严重缺陷。
- 能力扭曲 (Capability Contortions): 指AI利用其强大的能力来弥补其薄弱能力的现象。例如,使用巨大的上下文窗口(工作记忆)来弥补长期记忆存储的缺失,或依赖检索增强生成(RAG)来掩盖内部记忆检索的不可靠性。
相关工作
当前,通用人工智能(AGI)领域面临的一个核心瓶颈是缺乏一个明确、具体且可量化的定义。这导致“AGI”成了一个不断移动的靶子,随着专用AI在特定任务上不断取得突破,人们对AGI的标准也在不断变化。这种定义上的模糊性阻碍了对AGI进展的有效衡量、引发了无休止的争论,并掩盖了当前AI与真正AGI之间的实际差距。
本文旨在解决这一核心问题:如何为AGI建立一个具体、可衡量且稳定的定义,从而能够系统地评估当前AI系统的能力,并识别出通往AGI道路上的关键瓶颈。
本文方法
本文的核心创新在于将AGI的抽象概念转化为一个基于人类认知科学的可操作评估框架。其方法本质上是将AI系统置于与人类相同的认知能力测试“跑道”上,系统地进行衡量。
## 方法论基础:借鉴人类智能模型
为了给AGI一个坚实的定义,本文借鉴了心理测量学中最受认可的Cattell-Horn-Carroll (CHC) 理论。该理论将人类智能分解为一系列层级化的、可测量的认知能力。本文采纳并改编了这一模型,构建了一个多维度的AI评估体系。
## AGI的十个核心认知组件
该框架将通用智能分解为十个核心认知组件(或称为广泛能力),并为每个组件分配10%的权重,以强调认知能力的广度。这十个组件覆盖了文本、视觉和听觉等多种模态,共同构成了一个全面的评估体系。
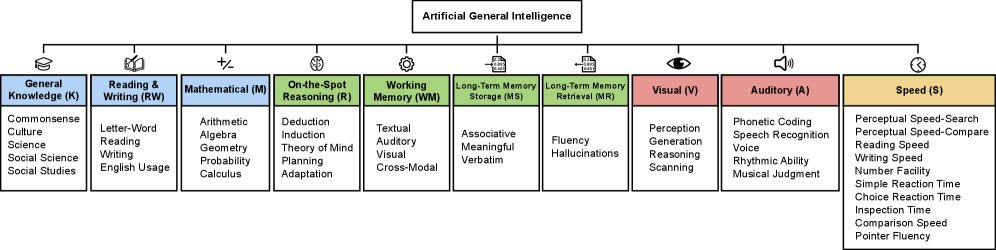
这十个组件分别是:
- 通用知识 (General Knowledge, K): 对世界常识、文化、科学、社科和历史的理解。
- 读写能力 (Reading and Writing Ability, RW): 从解码单词到复杂文本理解与创作的语言能力。
- 数学能力 (Mathematical Ability, M): 涵盖算术、代数、几何、概率和微积分的知识与技能。
- 即时推理 (On-the-Spot Reasoning, R): 在不依赖先验知识的情况下,灵活运用注意力解决新问题的能力,如演绎和归纳推理。
- 工作记忆 (Working Memory, WM): 在文本、听觉和视觉模态中维持和操作信息的能力。
- 长期记忆存储 (Long-Term Memory Storage, MS): 持续学习和巩固新信息的能力(关联、语义、逐字记忆)。
- 长期记忆检索 (Long-Term Memory Retrieval, MR): 流畅、准确地从存储中提取知识,并避免幻觉(confabulation)的能力。
- 视觉处理 (Visual Processing, V): 感知、分析、推理、生成和扫描视觉信息的能力。
- 听觉处理 (Auditory Processing, A): 辨别、识别和创造性地处理语音、节奏和音乐等听觉刺激的能力。
- 速度 (Speed, S): 快速执行简单认知任务的能力,包括感知速度、反应时间和处理流畅性。
## 创新点
- 从模糊到具体:最大的创新是将AGI从一个哲学概念转变为一个可测量的工程目标。它提供了一套具体的、源自成熟学科(心理测量学)的评估标准,而不是依赖于不断变化的单一任务基准。
- 诊断性而非单一分数:该框架不仅给出一个总体的“AGI分数”,更重要的是,它能揭示AI在十个维度上的“锯齿状认知剖面”,从而精确诊断出系统的优势和致命短板,为未来的研发指明方向。
- 强调基础认知机制:与许多只关注复杂任务表现的基准不同,该框架强调构成智能的底层、基础能力(如记忆存储、即时推理)。研究发现,尽管AI在复杂任务上表现优异,但其基础认知机制往往存在严重缺陷。
- 揭示“能力扭曲”:该框架有助于识别AI如何使用其优势能力来“伪装”或“绕过”其弱点。例如,用巨大的上下文窗口(工作记忆)来弥补长期记忆的缺失。识别这些“扭曲”对于准确评估AI的真实能力至关重要。
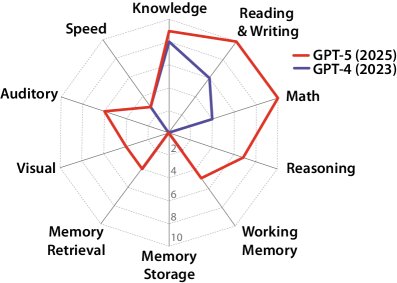
通过对这些能力的系统性测试,该框架最终会得出一个AGI分数,其中GPT-4的估算分数为27%,而一个假想的GPT-5模型分数为58%。
以下是每个认知组件的详细评估和AI系统表现。
## 1. 通用知识 (K)
![[无标题图片]](/images/2510.18212v1/x3.jpg) GPT-4拥有大量的通用知识,GPT-5则部分填补了其剩余的空白。
GPT-4拥有大量的通用知识,GPT-5则部分填补了其剩余的空白。
| 模型 | 常识 | 科学知识 | 社会科学知识 | 历史知识 | 文化知识 | 总分(10%) |
|---|---|---|---|---|---|---|
| GPT-4 | 2% | 2% | 2% | 2% | 0% | 8% |
| GPT-5 | 2% | 2% | 2% | 2% | 1% | 9% |
## 2. 读写能力 (RW)
![[无标题图片]](/images/2510.18212v1/x4.jpg) GPT-4在Token级别的理解、小上下文窗口和不精确的工作记忆方面存在困难,限制了其分析子字符串、阅读长文档和仔细校对文本的能力。GPT-5解决了这些问题。
GPT-4在Token级别的理解、小上下文窗口和不精确的工作记忆方面存在困难,限制了其分析子字符串、阅读长文档和仔细校对文本的能力。GPT-5解决了这些问题。
| 模型 | 解码能力 | 文档级阅读理解 | 写作能力 | 写作规范 | 总分(10%) |
|---|---|---|---|---|---|
| GPT-4 | 0% | 2% | 3% | 1% | 6% |
| GPT-5 | 1% | 3% | 3% | 3% | 10% |
## 3. 数学能力 (M)
![[无标题图片]](/images/2510.18212v1/x5.jpg) GPT-4的数学能力有限,而GPT-5则拥有出色的数学能力。
GPT-4的数学能力有限,而GPT-5则拥有出色的数学能力。
| 模型 | 算术 | 代数 | 几何 | 概率 | 微积分 | 总分(10%) |
|---|---|---|---|---|---|---|
| GPT-4 | 2% | 1% | 0% | 1% | 0% | 4% |
| GPT-5 | 2% | 2% | 2% | 2% | 2% | 10% |
## 4. 即时推理 (R)
![[无标题图片]](/images/2510.18212v1/x6.jpg) GPT-4的即时推理能力可以忽略不计,而GPT-5仅存在一些残留的差距。
GPT-4的即时推理能力可以忽略不计,而GPT-5仅存在一些残留的差距。
| 模型 | 演绎推理 | 归纳推理 | 心智理论 | 规划能力 | 规则学习 | 总分(10%) |
|---|---|---|---|---|---|---|
| GPT-4 | 0% | 0% | 0% | 0% | 0% | 0% |
| GPT-5 | 2% | 2% | 2% | 1% | 0% | 7% |
## 5. 工作记忆 (WM)
![[无标题图片]](/images/2510.18212v1/x7.jpg) 尽管GPT-4和GPT-5在文本工作记忆方面的原始分数相似,但GPT-5在管理长上下文方面的改进也体现在读写能力(RW)中的文档级阅读理解分数上。
尽管GPT-4和GPT-5在文本工作记忆方面的原始分数相似,但GPT-5在管理长上下文方面的改进也体现在读写能力(RW)中的文档级阅读理解分数上。
| 模型 | 文本工作记忆 | 听觉工作记忆 | 视觉工作记忆 | 多模态工作记忆 | 总分(10%) |
|---|---|---|---|---|---|
| GPT-4 | 2% | 0% | 0% | 0% | 2% |
| GPT-5 | 2% | 0% | 1% | 1% | 4% |
## 6. 长期记忆存储 (MS)
![[无标题图片]](/images/2510.18212v1/x8.jpg) GPT-4和GPT-5都缺乏可观的长期记忆存储能力。
GPT-4和GPT-5都缺乏可观的长期记忆存储能力。
| 模型 | 联想学习 | 语义学习和记忆 | 逐字记忆 | 总分(10%) |
|---|---|---|---|---|
| GPT-4 | 0% | 0% | 0% | 0% |
| GPT-5 | 0% | 0% | 0% | 0% |
## 7. 长期记忆检索 (MR)
![[无标题图片]](/images/2510.18212v1/x9.jpg) GPT-4和GPT-5都能从参数中快速检索许多概念,但它们都经常产生幻觉。
GPT-4和GPT-5都能从参数中快速检索许多概念,但它们都经常产生幻觉。
| 模型 | 联想和构想流畅性 | 检索准确性 | 总分(10%) |
|---|---|---|---|
| GPT-4 | 4% | 0% | 4% |
| GPT-5 | 4% | 0% | 4% |
## 8. 视觉处理 (V)
![[无标题图片]](/images/2510.18212v1/x10.jpg) GPT-4没有感知或生成图像的能力,而GPT-5的视觉处理能力虽然可观但非常不完整。
GPT-4没有感知或生成图像的能力,而GPT-5的视觉处理能力虽然可观但非常不完整。
| 模型 | 视觉感知 | 视觉生成 | 视觉空间推理 | 视觉扫描 | 总分(10%) |
|---|---|---|---|---|---|
| GPT-4 | 0% | 0% | 0% | 0% | 0% |
| GPT-5 | 2% | 2% | 0% | 0% | 4% |
## 9. 听觉处理 (A)
![[无标题图片]](/images/2510.18212v1/x11.jpg) GPT-4没有听觉处理能力,而GPT-5的能力虽然可观但不完整。
GPT-4没有听觉处理能力,而GPT-5的能力虽然可观但不完整。
| 模型 | 音位处理 | 语音转文本 | 语音合成 | 节奏感 | 音乐欣赏 | 总分(10%) |
|---|---|---|---|---|---|---|
| GPT-4 | 0% | 0% | 0% | 0% | 0% | 0% |
| GPT-5 | 0% | 4% | 2% | 0% | 0% | 6% |
## 10. 速度 (S)
![[无标题图片]](/images/2510.18212v1/x12.jpg) GPT-4和GPT-5都能快速读写和计算简单表达式,但它们其他多模态处理速度能力要么不存在,要么很慢。
GPT-4和GPT-5都能快速读写和计算简单表达式,但它们其他多模态处理速度能力要么不存在,要么很慢。
| 模型 | … | 阅读速度 | 书写/复制速度 | 计算速度 | … | 总分(10%) | | :— | :—: | :—: | :—: | :—: | :—: | :—: | | GPT-4 | … | 1% | 1% | 1% | … | 3% | | GPT-5 | … | 1% | 1% | 1% | … | 3% | 注:表格仅展示部分速度子项。
实验结论
## 核心发现
应用该框架对当前AI模型进行评估,得出了几个关键结论:
- AI的认知能力极不均衡:当前模型呈现出高度“锯齿状”的认知剖面。例如,估算得出GPT-4的总AGI分数为27%,GPT-5为58%,显示了快速进步,但与100%的人类水平仍有巨大差距。
- 知识渊博但基础薄弱:模型在利用海量训练数据的领域(如通用知识K、读写能力RW、数学能力M)表现出色。然而,在基础认知机制上存在严重缺陷。
- 最大的瓶颈:长期记忆:长期记忆存储 (Long-Term Memory Storage, MS) 是当前最显著的瓶颈,几乎所有模型的得分都接近0%。这意味着AI无法持续学习和积累经验,每次交互都像“失忆”一样需要重新学习上下文。
- 其他关键短板:除长期记忆外,在即时推理 (R)、视觉推理和多模态处理速度 (S) 等方面也存在明显不足。
## 能力扭曲现象
评估揭示了模型普遍存在的“能力扭曲”(Capability Contortions)现象,即利用优势能力来掩盖或补偿弱势能力。
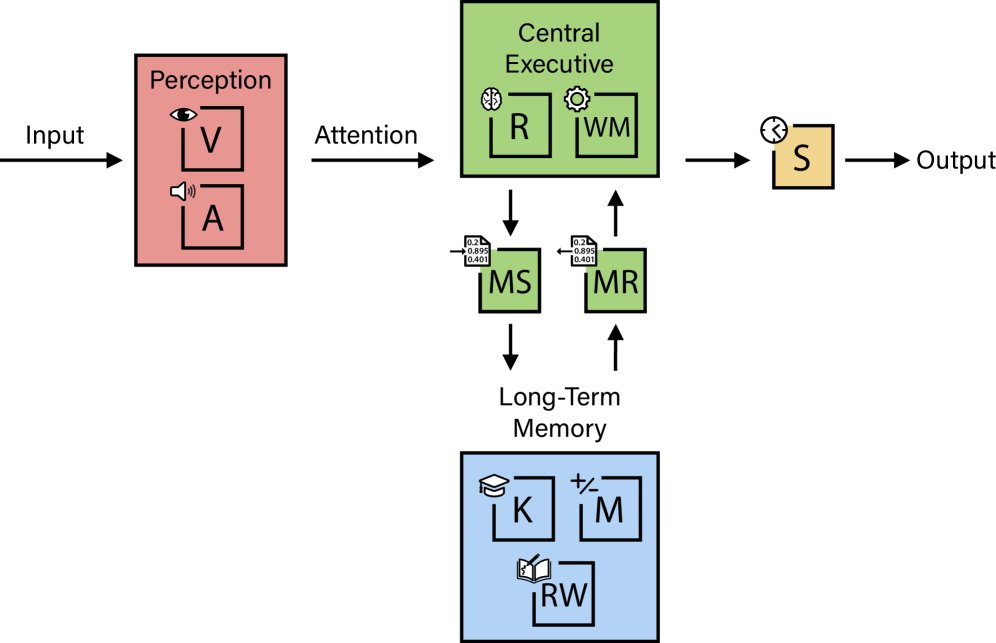
- 长上下文 vs. 长期记忆:模型依赖巨大的上下文窗口(工作记忆)来处理需要长期上下文的任务,但这是一种计算成本高、效率低下且无法扩展的权宜之计,不能替代真正的长期记忆系统。
- RAG vs. 记忆检索:使用检索增强生成(RAG)来提高事实准确性,掩盖了模型自身记忆检索不可靠(易产生幻觉)和缺乏动态经验记忆的根本问题。RAG更像是外部数据库查询,而非真正的内化记忆。
## 总结
本文提出的AGI定义与评估框架,将AI的能力类比为一个引擎。无论某些部件(如知识储备)多么强大,整个系统的“马力”最终受限于其最弱的部件。当前,AI引擎的几个关键部件(如长期记忆存储)存在严重缺陷,极大地限制了其整体性能。
最终结论是,尽管当前AI取得了惊人进展,但距离实现与人类相当的通用智能(AGI)仍有很长的路要走。本框架不仅量化了这一差距,更重要的是,它精确地指出了需要攻克的关键技术瓶颈,为未来AGI的研发提供了清晰的路线图。