A model of errors in transformers
DeepMind重磅:仅需2个参数,精准预测LLM错误率!物理学“有效场论”立大功

你是否遇到过这种情况:一个在写诗、编程上表现惊人的大模型,却在做简单的多位数加法、或者玩“汉诺塔”游戏时,随着步骤变长而突然“智商掉线”?
ArXiv URL:http://arxiv.org/abs/2601.14175v1
通常,我们会把这种现象归结为“推理崩溃”(Reasoning Collapse)或者模型缺乏“组合泛化能力”。但 Google DeepMind 和塔塔基础研究院的一项最新研究提出了一个颠覆性的观点:这可能只是简单的“噪声累积”罢了。
这项研究借鉴了物理学中有效场论(Effective Field Theory)的视角,发现尽管 LLM 拥有数千亿个参数,但决定其在长任务中错误率的,竟然只有两个有效参数。
物理学视角的降维打击
在物理学中,虽然流体由无数个微观分子组成,但在宏观层面,我们只需要“密度”和“粘度”几个参数就能描述它的行为。
研究团队认为,LLM 也是如此。虽然模型内部参数如恒河沙数,但在处理确定性任务(如算术、逻辑推理)时,其错误行为可以被简化为一个双参数模型。
研究者提出,LLM 的错误并非源于“逻辑不懂”,而是源于注意力机制中的微小误差。这些微小的误差在长序列生成的过程中不断累积,一旦超过某个阈值,模型就会预测出一个错误的 Token。
核心公式:仅需两个参数
基于上述假设,论文推导出了一个简洁优美的公式,用来描述模型准确率($a$)与任务复杂度($c$)之间的关系:
\[a={1\over\Gamma({q\over 2})}\gamma({q\over 2},{q\over 2rc^{2\alpha}})\]这个公式看着复杂,但核心变量只有两个:
-
$r$(噪声率):这是一个很小的数,代表每个 Token 产生的基本“噪声”。
-
$q$(错误方向数):这是一个数量级为 1 的数,代表在预测时可能偏离的“错误方向”的数量。
这个公式告诉我们:随着任务复杂度 $c$(例如加法位数、推理步数)的增加,噪声会以 $c^{2\alpha}$ 的速度累积,导致准确率呈现特定的衰减曲线。
实验验证:惊人的拟合度
为了验证这个理论,研究团队在 Gemini 2.5 Flash、Gemini 2.5 Pro 以及 DeepSeek R1 上进行了广泛测试。测试任务包括列表反转、嵌套线性变换、动态规划、汉诺塔、加法乘法等 8 种任务,涉及 20 万个不同的 Prompt。
结果令人震惊:理论预测曲线与实际观测数据高度重合!
无论是 DeepSeek R1 还是 Gemini 系列,在绝大多数任务中,其错误率随任务长度的变化都完美遵循上述公式。
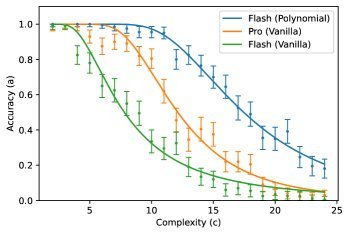
图:不同模型在乘法任务上的准确率随复杂度变化的曲线,实线为理论预测,点为实际数据。可以看到拟合度极高。
有趣的发现:Gemini Pro 的“异常”
在“普通加法”任务中,Gemini 2.5 Pro 最初并不符合这个公式。为什么?
研究人员推测,这是因为 Gemini Pro 过于“聪明”,它可能针对不同长度的数字使用了不同的内部算法,破坏了模型的前提假设(即参数不变)。
为了验证这一点,研究人员设计了一个 Prompt,强制模型使用特定的步骤分解算法(Algorithm)来进行加法。结果,Gemini Pro 的表现立刻回归了理论曲线。这反向证明了:只要算法路径是确定的,噪声累积理论就是成立的。
结论与启示
这项研究不仅为我们提供了一个量化评估 LLM 可靠性的工具,更重要的是它为“长文本推理”祛魅了。
模型在长任务中失败,不一定是因为它“变笨了”或“推理能力崩溃”,很可能只是因为注意力机制中的“热噪声”累积到了不可忽视的程度。这意味着,通过精心设计的 Prompt(例如强制模型使用更稳健的中间步骤来“重置”噪声),我们可以显著降低错误率。
物理学的思维方式,再一次在 AI 领域展现了其化繁为简的魔力。