A Subgoal-driven Framework for Improving Long-Horizon LLM Agents
成功率飙升6倍超GPT-4o!DeepMind发布MiRA,用“里程碑”根治AI智能体“迷路”顽疾

AI智能体(Agent)正被赋予越来越复杂艰巨的任务,从自动操作手机到浏览网页完成预订。然而,当任务流程变长、步骤变多时,即使是最先进的大模型也常常会“迷路”——陷入无效循环,或在任务中途“卡住”不知所措。
ArXiv URL:http://arxiv.org/abs/2603.19685v1
这个问题该如何解决?
来自Google DeepMind的最新研究给出了一个优雅而高效的答案:如果终点太远,那就为它设定清晰的“里程碑”!
该研究提出了一个由子目标驱动的统一框架,不仅在推理时为AI智能体动态规划路径,更通过名为MiRA的创新训练方法,让开源模型在复杂网页任务上的性能实现了惊人的飞跃。
AI智能体为何在长任务中“迷路”?
在设计解决方案之前,我们得先搞清楚问题出在哪。
研究团队开发了一套自动化失败分析器,通过分析海量任务轨迹,精准诊断AI智能体在网页导航等长任务中的主要“死因”。
分析结果直指要害:最主要的失败模式是中途卡住(Get Stuck Midway)。
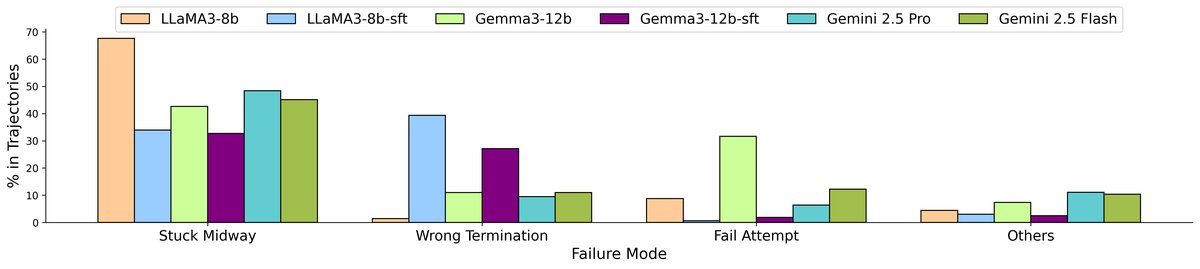
无论是强大的闭源模型Gemini,还是开源的Gemma,都普遍存在这个问题。它们可能成功执行了前面几个步骤,但随后就陷入了重复操作的循环,或者面对新页面手足无措,最终导致任务失败。
这表明,模型缺乏对任务全局的持续理解和稳健的规划能力。
核心思路:子目标驱动的规划与训练
针对“中途卡住”这一核心痛点,研究团队提出了一个简单的原则:
“如果最终目标难以直接一步到位,那么提高达成有意义的中间里程碑的概率会有所帮助。”
基于此,他们设计了一个双管齐下的框架,将复杂的长任务分解为一系列可执行的子目标(或称“里程碑”)。
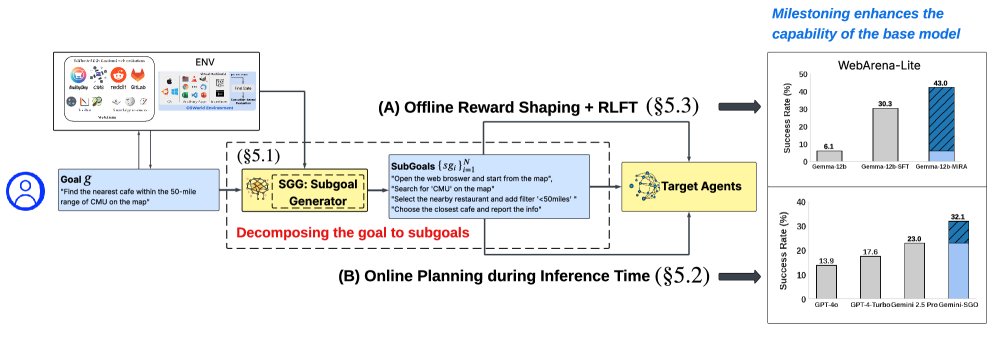
这个框架主要包含两大贡献:
-
推理时规划:在智能体执行任务时,动态生成子目标,像GPS一样实时引导其前进。
-
MiRA训练框架:在模型训练阶段,利用里程碑作为密集的奖励信号,优化其学习过程。
推理时规划:为Gemini等大模型动态导航
对于像Gemini这样能力强大的闭源大模型,研究团队采用了一种轻量级的推理时规划策略。
在任务执行过程中,系统会调用一个更强大的“教师模型”(如Gemini-2.5-pro),根据当前状态和最终目标,动态生成一系列逻辑清晰的子目标。
例如,对于“在维基百科上查找某部电影的导演并导航到导演页面”这个任务,系统会生成如下子目标:
-
在搜索框输入电影名称。
-
点击搜索按钮。
-
在电影页面找到“导演”一栏的信息。
-
点击导演姓名对应的链接。
这些子目标为智能体提供了清晰的行动指南,有效避免了其在复杂页面中迷失方向。实验证明,仅通过这种推理时的动态规划,就能让Gemini在WebArena-Lite基准测试中的成功率绝对提升约10%。
MiRA:用“里程碑”奖励彻底改造开源模型
对于开源模型,研究团队则更进一步,提出了MiRA(Milestoning your Reinforcement Learning Enhanced Agent)——一个基于里程碑的强化学习训练框架。
传统的强化学习(Reinforcement Learning, RL)在网页导航这类任务中面临一个巨大挑战:奖励稀疏。智能体只有在完成所有步骤并最终成功时才能获得正向奖励,中间漫长的步骤无论好坏都没有反馈。这就像让一个学生做一套100道题的卷子,却只在得满分时才告诉他“你做对了”,学习效率可想而知。
MiRA彻底改变了这一点。
它将子目标作为“里程碑”,每当智能体成功完成一个里程碑,就立即给予一次奖励。这种机制借鉴了基于势能的奖励塑造(Potential-Based Reward Shaping, PBRS)的思想,将一个稀疏的最终奖励,转化为一系列密集的中间奖励。
\[\tilde{r}\_{t}=r\_{t}+\gamma\Phi(s\_{t+1})-\Phi(s\_{t})\]这里的 $\Phi(s)$ 就代表了与里程碑相关的“势能函数”。每达成一个里程碑,势能就增加,智能体就能获得一次正反馈。
通过这种方式,智能体能明确知道哪一步走对了,从而更快地学习到完成复杂任务的正确策略,极大地提升了训练效率和最终性能。
惊人效果:开源模型Gemma反超GPT-4o
MiRA框架的效果有多惊人?数据说明了一切。
研究团队将MiRA应用于开源的Gemma3-12B模型,并在高难度的WebArena-Lite基准上进行测试。结果显示:
-
模型的成功率从微调前的6.4%飙升至43.0%,性能提升超过6倍!
-
这一成绩不仅远超之前的开源SOTA模型WebRL(38.4%),甚至超越了强大的闭源商业模型,如GPT-4-Turbo(17.6%)和最新的GPT-4o(13.9%)。
这证明,通过精巧的训练框架设计,中等规模的开源模型完全有潜力在复杂的决策任务上比肩甚至超越顶级的闭源大模型。
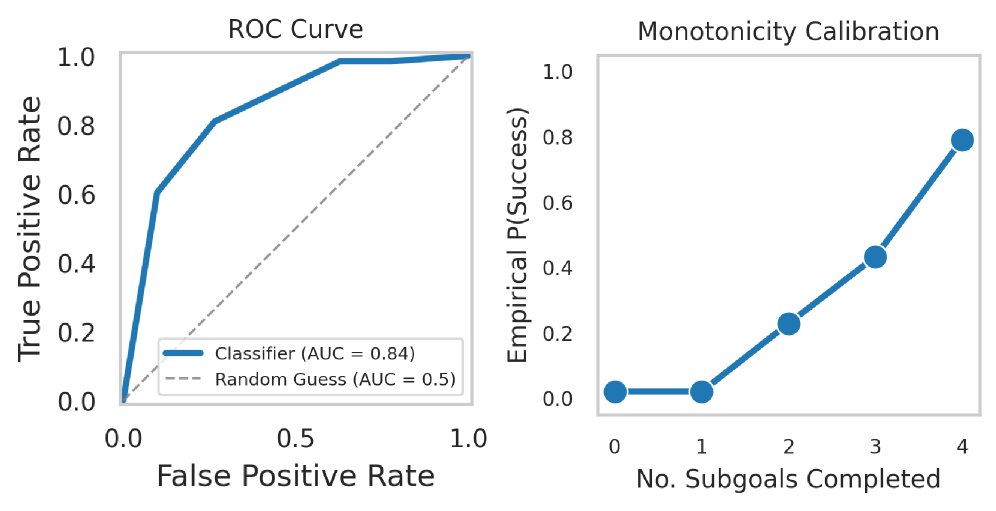
当然,这一切的前提是子目标的质量要足够高。研究也证实,这些由大模型生成的子目标是可靠的进度指标。如下图所示,完成的子目标数量与最终任务成功率呈现出强烈的正相关性(AUROC高达0.84)。
结论
这项研究深刻地揭示了当前AI智能体在长时程任务中的核心瓶颈,并提供了一套行之有效的解决方案。通过将宏大目标分解为明确的“里程碑”,并将其统一应用于推理时规划和离线强化学习训练中,MiRA框架成功地治愈了AI智能体“中途迷路”的顽疾。
这项工作不仅为构建更强大、更可靠的自主系统铺平了道路,也再次证明了通过巧妙的算法设计,我们能够充分释放现有模型的潜力,让它们在真实世界的复杂数字环境中游刃有余。