A Survey of Weight Space Learning: Understanding, Representation, and Generation
模型即数据!英伟达领衔,三大维度解读AI新前沿:权重空间学习

当今的AI世界,我们仿佛置身于一个由海量预训练模型构成的“模型动物园”(Model Zoo)。从GPT系列到Stable Diffusion,无数强大的模型被创造和分享。
ArXiv URL:http://arxiv.org/abs/2603.10090v1
我们通常将这些模型的权重(weights)视为训练的终点。但你是否想过,如果把视角颠倒一下会怎样?
如果这些数以亿计的参数本身,就是一种全新的、蕴含丰富信息的数据呢?
最近,一篇由英伟达、加州大学圣迭戈分校等顶尖机构联合发布的综述,首次为这个新兴领域描绘了一幅完整的蓝图。它提出了一个颠覆性的概念:权重空间学习(Weight Space Learning, WSL),主张将模型权重本身作为一个可学习的、结构化的领域进行研究。
这篇综述系统地梳理了该领域的现状,并将其划分为三大核心维度,为我们打开了通往“模型即数据”新世界的大门。
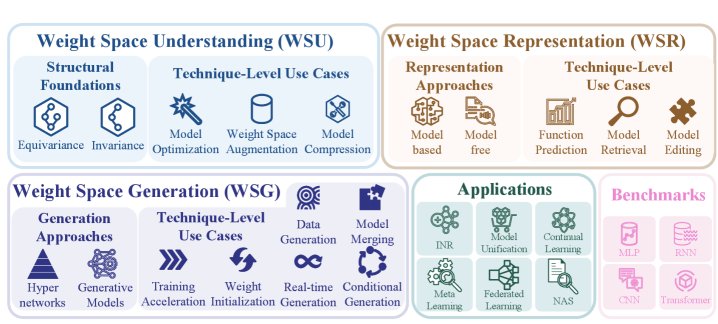
图1:权重空间学习(WSL)综述概览
什么是权重空间学习 (WSL)?
简单来说,WSL不再仅仅关注数据、特征或模型架构,而是将机器学习的镜头直接对准了模型参数(权重)本身。
它试图回答一个根本性问题:
我们能否直接对成千上万个训练好的模型进行学习,从而分析、比较、甚至生成全新的模型?
这篇综述将这一新兴范式归纳为三个相互关联的维度:
-
权重空间理解 (WSU):研究权重空间的内在几何结构与对称性。
-
权重空间表示 (WSR):为模型权重学习紧凑的、有意义的“嵌入”表示。
-
权重空间生成 (WSG):通过辅助模型直接合成全新的网络权重。
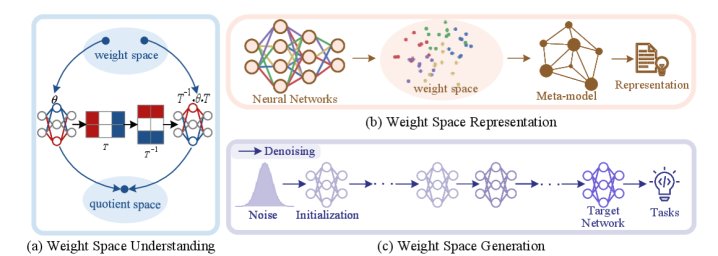
图2:WSL三大核心维度的概念图
接下来,让我们逐一深入这三个迷人的维度。
权重空间理解 (WSU): 破译模型参数的“语法”
WSU旨在揭示神经网络权重空间固有的“物理定律”。它发现,权重空间并非一盘散沙,而是充满了精妙的结构,其中最重要的就是对称性(Symmetry)。
这主要体现在两个方面:
1. 函数不变性 (Functional Invariance)
想象一下,用两种不同的措辞表达同一个意思。在权重空间里,也存在类似现象。
由于网络结构的冗余,许多不同的权重配置($\theta$)实际上会产生完全相同的模型功能($f$)。
\[f(\rho_{in}(\theta);x)=f(\theta;x)\]最典型的例子就是神经元置换不变性:在一个全连接层中,交换任意两个神经元的位置及其对应的连接权重,网络的最终输出保持不变。
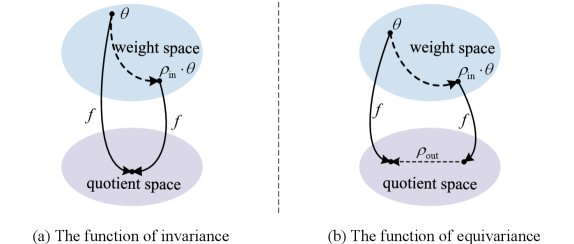
图4:权重空间对称性示意图
理解这种不变性,让我们能够识别并剔除模型中的冗余参数,为模型压缩提供了理论依据。同时,这也解释了为什么优化器总能在损失平面上找到宽阔的“最优解谷底”,因为最优解并非一个点,而是一个由等效权重构成的流形。
2. 函数等变性 (Functional Equivariance)
如果说不变性是“变了但没完全变”,那么等变性就是“按规律变”。
它指的是,对权重进行一种结构化的变换,会导致模型的功能也发生一种可预测的、对应的变化。
\[f(\rho_{in}(\theta);x)=\rho_{out}(f(\theta;x))\]这种特性揭示了模型家族之间的内在联系。通过利用等变性,我们可以设计出能够跨架构进行模型编辑或推理的元模型(meta-models),为模型宇宙的导航提供了“几何地图”。
权重空间表示 (WSR): 给每个模型一张“数字身份证”
理解了权重的内在结构后,我们自然会问:能否将一个完整的神经网络压缩成一个低维向量,就像给每个模型办一张“数字身份证”?
这就是权重空间表示(WSR)的目标。它学习一个映射函数 $\phi$,将高维的权重 $\theta$ 映射到一个紧凑的嵌入向量 $z$。
\[z=\phi(\theta)\]有了这个嵌入向量 $z$,我们就可以在不访问原始训练数据的情况下,直接预测模型的性能、检索功能相似的模型,甚至对模型进行编辑。
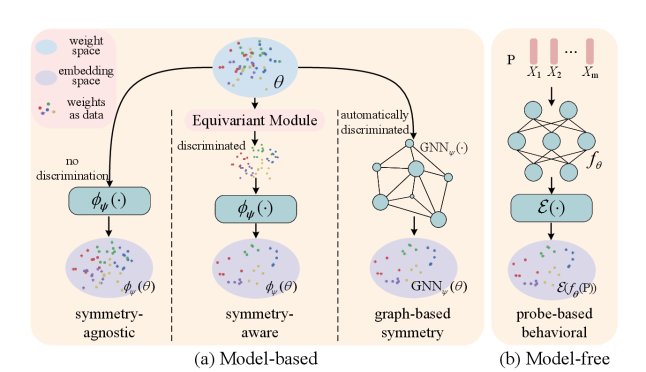
图5:权重空间表示(WSR)的主要方法
实现WSR主要有两大类方法:
1. 基于模型的方法 (Model-based)
这类方法直接将权重张量作为输入,通过一个编码器模型来学习其表示。其发展历程体现了对权重对称性的逐步深化理解:
-
对称性不可知:早期方法直接将权重“拉平”成一个向量,忽略了其结构信息。
-
对称性感知:后续工作开始设计特殊的网络结构(如处理集合的Deep Sets),来手工编码神经元置换不变性等先验知识。
-
基于图的方法:最新的趋势是将神经网络本身看作一个计算图,然后利用图神经网络(GNN)自动学习其结构对称性,实现了更强的泛化能力。
2. 免模型的方法 (Model-free)
这类方法独辟蹊径,它不直接看模型的权重,而是通过观察模型的“行为”来为其画像。
具体来说,它通过向模型输入一组精心设计的“探针”(probes),并记录其输出响应,从而构建一个行为签名。
\[z=\mathcal{E}\big(\{f\_{\theta}(x\_{i})\}\_{x\_{i}\in\mathcal{P}}\big)\]这种方法的优势在于,它天然地绕过了所有与权重相关的对称性问题,并且对模型架构不可知,甚至可以用于分析那些无法访问权重的“黑箱”模型。
权重空间生成 (WSG): 从“理解”到“创造”新模型
WSL最激动人心的方向,莫过于权重空间生成(WSG)。它不仅要理解和表示模型,更要直接“凭空”生成全新的模型权重。
这听起来像是科幻,但已经有了切实的技术路径:
-
超网络 (Hypernetworks):训练一个小型网络(超网络)来生成另一个大型网络(主网络)的权重。这在神经架构搜索(NAS)和模型个性化方面展现了巨大潜力。
-
生成式模型:借鉴图像生成领域的成功,研究者开始使用扩散模型(Diffusion Models)或GAN来学习整个模型动物园的权重分布,然后从中采样生成全新的、可用的模型。
WSG为我们描绘了一个未来:我们或许不再需要从零开始、耗费大量资源去训练每一个模型,而是可以像生成图片一样,高效地“合成”出满足特定需求的模型。
WSL的应用与未来
权重空间学习不仅仅是理论上的探索,它已经为许多实际应用打开了新的大门:
-
模型检索:在庞大的模型市场中,快速找到最适合特定任务的预训练模型。
-
持续学习与联邦学习:通过在权重空间进行模型融合或编辑,有效缓解灾难性遗忘,或在保护数据隐私的同时聚合知识。
-
无数据模型分析:在没有原始数据的情况下,仅通过模型权重就能预测其性能、鲁棒性甚至公平性。
这篇综述为我们系统地梳理了“权重空间学习”这一前沿阵地。它标志着一个重要的范式转变:将AI研究的重心从“学习数据”扩展到“学习学习者(模型)本身”。
当然,WSL仍处于起步阶段,尤其是在如何将其扩展到拥有数万亿参数的巨型模型上,还面临诸多挑战。但它无疑为我们提供了一套全新的、强大的认知工具,去探索和驾驭日益复杂的AI模型宇宙。
感兴趣的读者可以访问该综述维护的资源库,获取更多相关论文和代码:
https://github.com/Zehong-Wang/Awesome-Weight-Space-Learning