A Survey on Efficient Large Language Model Training: From Data-centric Perspectives
-
ArXiv URL: http://arxiv.org/abs/2510.25817v1
-
作者: Jingyang Yuan; Rong-Cheng Tu; Yiqiao Jin; Wei Ju; Yifan Wang; Xiao Luo; Ming Zhang; Nan Yin; Zhiping Xiao; Bohan Wu; 等11人
-
发布机构: Georgia Institute of Technology; HKUST; Nanyang Technological University; Peking University; University of California; University of International Business and Economics; University of Washington
引言
大型语言模型 (Large Language Models, LLMs) 的后训练 (post-training) 已成为释放其领域适应能力和任务泛化潜力的关键阶段。这一阶段有效增强了模型在长上下文推理、人类对齐、指令微调和领域专用适应等方面的能力。
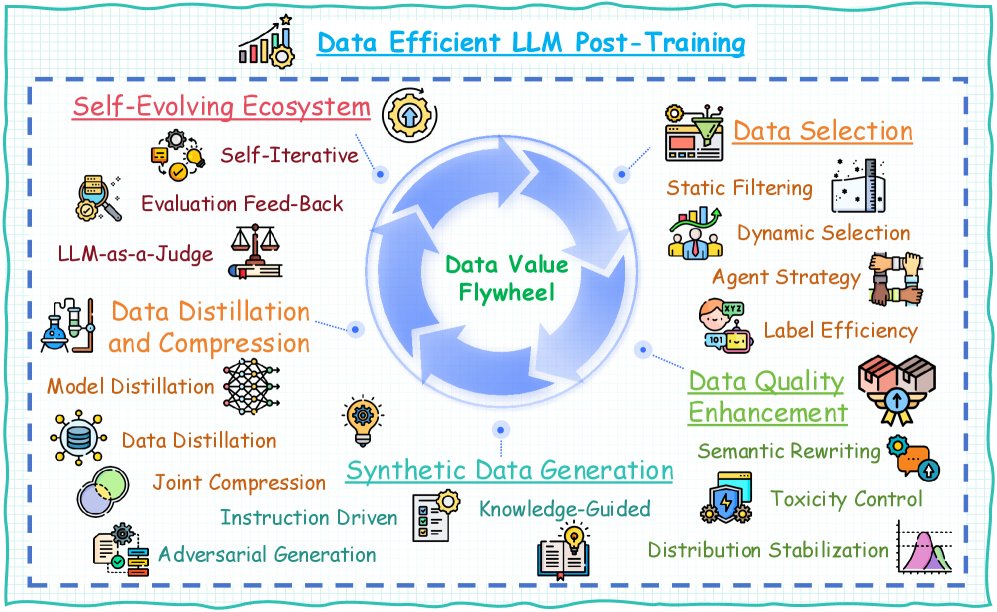
然而,在LLM后训练阶段,数据作为模型演进的核心驱动力,正面临严峻的“数据挑战” (data challenge):手动标注高质量数据的成本迅速增长,而简单地扩大数据规模带来的边际收益却在递减。此外,静态数据集固有地限制了模型适应不断变化的现实世界知识。数据量与模型性能之间的线性依赖关系,根本上源于传统后训练范式中低效的数据利用方式。
研究人员已探索了多种方法来充分挖掘LLM后训练中的数据潜力,但该领域仍缺乏一个全面的综述。本文从数据中心视角对数据高效的LLM后训练进行了首次系统性综述。具体而言,本文提出了一个“数据飞轮” (data flywheel) 的概念(如图所示),它包含五个关键组成部分:数据选择、数据质量增强、合成数据生成、数据蒸馏与压缩以及自进化数据生态系统。基于此框架,本文对现有工作进行了分类,总结了关键组成部分,并指出了未来的研究方向。
与先前综述的区别:虽然已有综述探讨了LLM后训练的某些方面,如数据选择、合成数据生成、模型自反馈、自进化、可信赖性及时间效率,但这些研究主要关注单一环节而非一个整体视角。本综述通过数据效率的镜头系统性地审视了这些方法,填补了空白,并为最大化数据价值提取提供了关键洞见。
分类体系
本节将数据高效的LLM后训练方法分为五大核心类别:
- 数据选择 (Data Selection):❶ 静态过滤:基于数据固有属性进行离线选择;❷ 动态选择:根据模型不确定性调整权重;❸ 智能体策略 (Agent Strategy):多模型投票以实现可靠选择;❹ 标注效率 (Labeling Efficiency):结合主动学习和半监督策略,以低成本覆盖样本。
- 数据质量增强 (Data Quality Enhancement):❶ 语义重写:通过保留语义的转换增强表达多样性,并在保持原意的同时生成变体;❷ 毒性控制:修正有害内容;❸ 分布稳定:调整数据特征以增强鲁棒性。
- 合成数据生成 (Synthetic Data Generation):❶ 指令驱动:模型生成的指令-响应对;❷ 知识引导:结合结构化知识进行生成;❸ 对抗性生成:产生具有挑战性的样本。
- 数据蒸馏与压缩 (Data Distillation and Compression):❶ 模型蒸馏:将大模型的输出分布转移到小模型中,同时保留关键知识;❷ 数据蒸馏:提取高信息密度样本,构建与全量数据等效的紧凑数据集;❸ 联合压缩:结合模型架构压缩与数据选择策略,实现端到端效率优化。
- 自进化数据生态系统 (Self-Evolving Data Ecosystems):❶ 自迭代优化:使用当前模型生成新数据;❷ 动态评估反馈:实时监控和调整;❸ LLM即评判者 (LLM-as-a-Judge):反馈驱动的数据优化。
下表比较了这五类方法在关键维度上的表现,其中“+”越多表示要求越高或性能越好。
| 方法类别 | 数据效率 | 计算需求 | 模型能力依赖 | 质量要求 | 领域适应性 |
|---|---|---|---|---|---|
| 数据选择 | +++ | ++ | + | +++ | ++ |
| 数据质量增强 | ++ | ++ | ++ | ++ | ++ |
| 合成数据生成 | ++ | +++ | +++ | + | +++ |
| 数据蒸馏与压缩 | +++ | ++ | +++ | ++ | ++ |
| 自进化数据生态系统 | ++ | +++ | +++ | + | +++ |
这五个维度相辅相成:选择过滤高质量数据,增强提高数据效用,生成扩大数据覆盖面,蒸馏浓缩知识,而自进化则实现持续改进。它们共同追求以最小化的数据需求实现模型性能最大化的目标。
数据选择
数据选择通过识别高价值数据子集,对提升LLM后训练效率至关重要。如下图所示,本文将现有方法分为四个维度:(1) 基于数据固有属性的静态过滤,(2) 训练过程中自适应的动态选择,(3) 使用协作机制的智能体策略,以及 (4) 通过人机协作实现的标注效率。
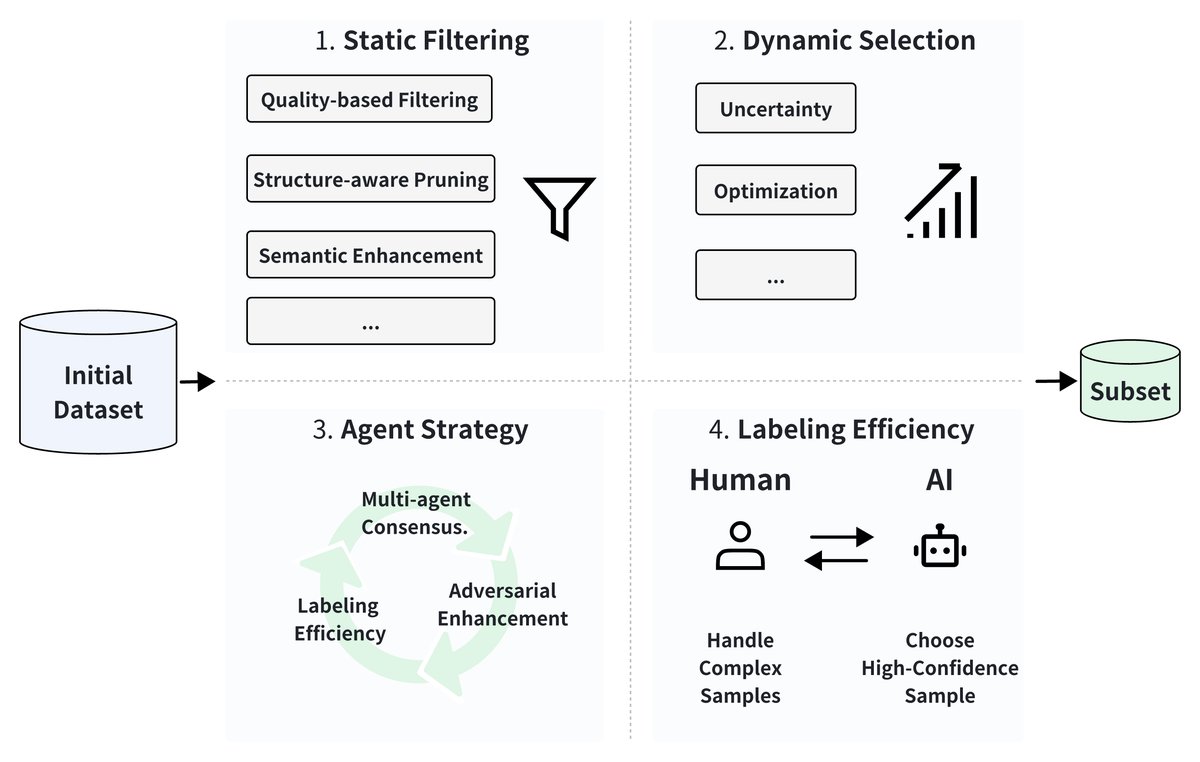
静态过滤
静态过滤通过离线评估数据的固有属性,来识别具有高信息密度和代表性的样本。
- 基于质量的过滤:Alpagasus通过基于复杂度的过滤(指令长度、多样性和困惑度)仅使用17%的原始数据就达到了可比的性能。MoDS采用多维度指标和密度峰值聚类,而其他工作则使用KL散度驱动的选择来对齐领域分布。信息论方法利用熵度量(如负对数似然和逆词频)来识别冗余样本。
- 语义增强:LIFT通过自动修订来提升指令质量。InsTag提出细粒度的指令标记来分析监督微调数据集中的多样性和复杂性,表明模型能力随数据更多样和更复杂而增长。
动态选择
动态方法通过评估样本对模型的重要性来适应性地调整数据权重。
- 不确定性驱动的选择:主动指令微调 (Active Instruction Tuning) 通过预测熵优先选择高不确定性的任务。自引导数据选择 (Self-Guided Data Selection) 使用指令遵循难度 (Instruction Following Difficulty, IFD) 来衡量损失方差,并剔除易于学习的样本。
- 基于优化的选择:样本高效对齐 (Sample-efficient alignment) 使用汤普森采样来最大化样本在偏好对齐任务中的贡献。P3集成了策略驱动的难度评估、步调自适应选择以及通过行列式点过程 (Determinantal Point Process) 促进多样性。
智能体策略
基于智能体的方法利用协作机制进行可靠的数据选择。
- 多智能体共识:多智能体方法如CLUES实现了基于训练动态和梯度相似度指标的多模型投票机制。
- 对抗性增强:DATA ADVISOR使用红队智能体进行安全过滤,而自动化数据策展 (Automated Data Curation) 则通过生成器-判别器框架优化数据。
标注效率
这些方法通过迭代的人机协作来有效优化标注过程。
- 人机协作:LLMaAA等方法利用LLM作为标注者,并结合不确定性采样。CoAnnotating在人类和AI之间实现了基于不确定性的劳动分工。
- 自动化生成:SELF-INSTRUCT使模型能够自主生成指令数据。
- 工作流优化:近期工作通过自适应实验设计和系统化的策展系统建立了可扩展的高效标注工作流。
讨论
当前的数据选择方法在将静态指标与动态模型需求对齐、管理优化过程中的计算复杂性以及实现跨领域泛化方面面临挑战。未来的研究方向指向基于元学习的选择框架、用于样本分析的因果推断以及考虑硬件约束的效率感知优化。
数据质量增强
如下图所示,提升数据质量对于最大化LLM后训练的效果至关重要。通过语义精炼、毒性控制和分布稳定化,研究人员旨在提高训练数据的知识性、安全性和鲁棒性。本文将现有方法归为三个方向。
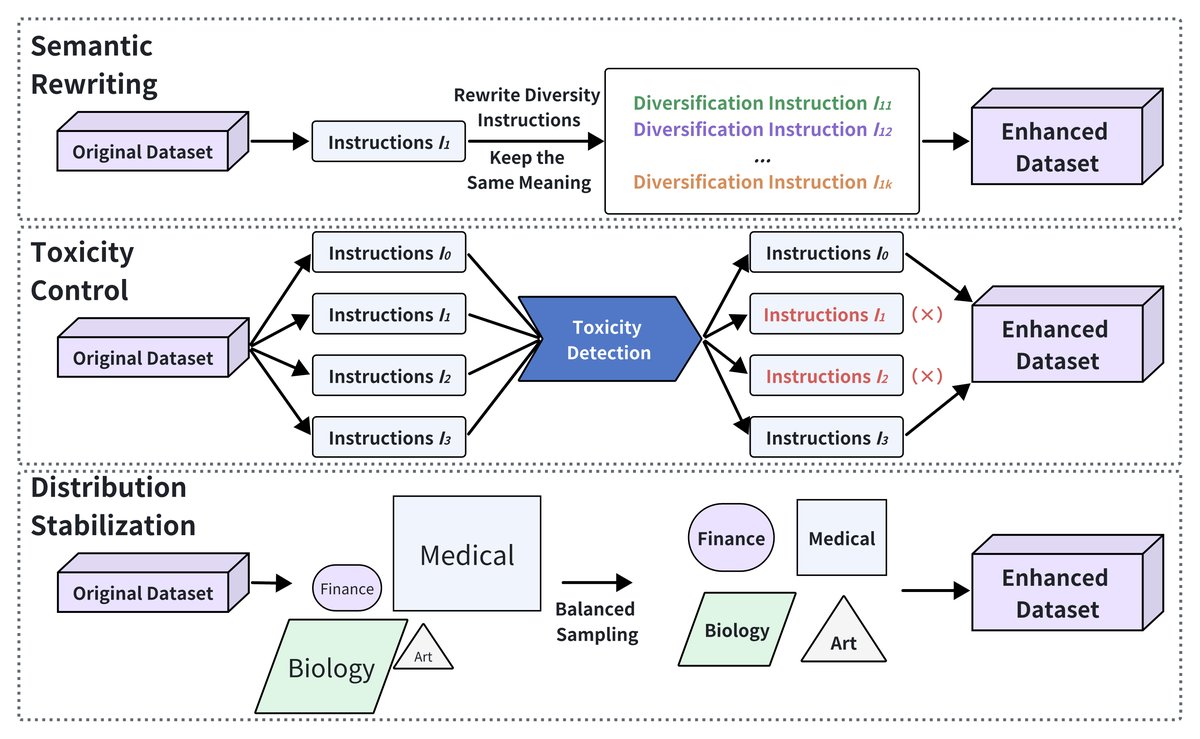
语义重写
语义重写专注于在保持原始意义的同时,通过受控变换来增加数据多样性。
- 指令精炼:CoachLM自动修订复杂指令以减少歧义,而其他工作使用结构化提示链生成释义,增强模型的跨任务泛化能力。
- 领域专用增强:PGA-SciRE等方法为科学关系抽取任务注入结构化知识,使模型适应专门任务。
- 自动化增强:AutoLabel无缝集成了人类反馈以进行高质量重写。LANCE使LLM能够自主生成、清洗、审查和标注数据,充当持续自进化的数据工程师。
毒性控制
减轻有害内容是数据质量增强的关键。
- 检测框架:有方法能有效地将毒性知识蒸馏到紧凑的检测器中,或策略性地利用生成式提示进行零样本毒性分类。
- 对抗性基准测试:TOXIGEN和ToxiCraft等框架生成对抗性数据集以对模型进行压力测试。研究发现,较小的模型通常表现出较低的毒性率。
- 人机协作:研究表明,人类干预,特别是通过反事实数据增强,能显著提高毒性检测的质量。
分布稳定
稳定数据分布确保模型能在不同任务和领域间良好泛化。
- 不平衡缓解:合成过采样 (Synthetic Oversampling) 和“分而治之” (Diversify and Conquer) 等方法通过自适应合成样本生成,有效解决了类别不平衡问题。
- 噪声降低:Multi-News+通过自动标签校正显著减少了标注错误。RobustFT引入了一个综合框架,通过多专家协作噪声检测和上下文增强的重标注策略处理带噪响应数据。
- 领域适应:RADA通过从其他数据集中检索相关实例,并通过LLM提示生成上下文增强的样本,以解决低资源领域的任务。Dynosaur和Optima等先进方法利用课程学习和多源协调。
讨论
语义重写、毒性控制和分布稳定是提升LLM后训练数据质量的关键策略。未来的工作应将这些方法整合到统一的框架中,以最大化数据多样性和模型性能,同时降低成本。
合成数据生成
生成合成训练数据是克服数据稀缺和增强LLM后训练鲁棒性的强大策略。如下图所示,合成数据生成方法可分为三类:指令驱动生成、知识引导生成和对抗性生成。
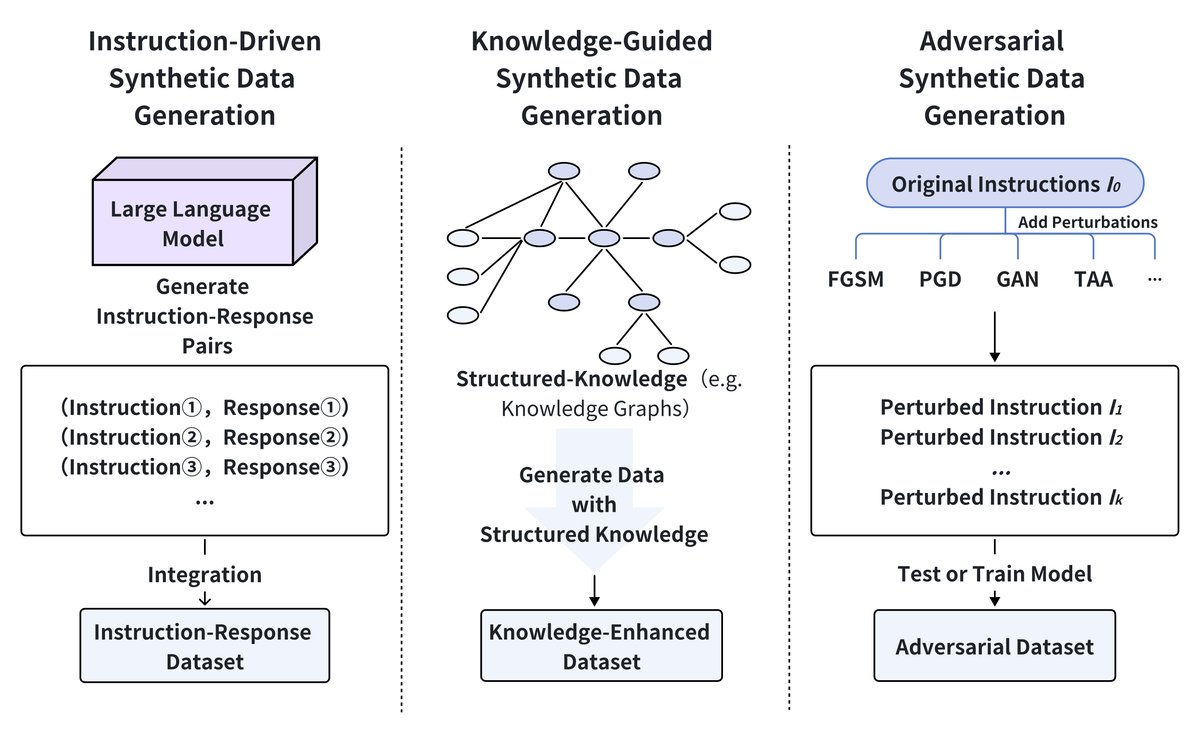
指令驱动的合成数据生成
指令驱动方法利用LLM直接从任务提示生成新样本的能力。例如,SynPO为对齐任务生成偏好对,Magpie实现了无模板的指令生成,而其他工作则合成了证明步骤,显著提升了GPT-4的证明能力。
知识引导的合成数据生成
知识引导方法集成了外部知识来指导数据生成。
- 理论框架:有研究严谨地建立了“反向瓶颈” (reverse-bottleneck) 理论,将数据多样性与增强的模型泛化能力联系起来。
- 结构化数据合成:HARMONIC结合了隐私保护的表格数据生成。其他方法通过模式感知的微调提升了关系一致性。
- 成本效益策略:混合生成方法可将API成本降低70%,同时保持数据效用。Source2Synth通过知识图谱对齐提高了事实准确性。
对抗性生成
对抗性生成方法系统性地探测模型漏洞以增强鲁棒性。例如,有工作使用基于智能体的模拟生成边缘案例,将方言变异的错误率降低了19%;另有工作引入对比性反学习 (contrastive unlearning) 来解决数据缺陷;ToxiCraft则生成了微妙的有害内容,揭示了商业安全过滤器的显著差距。
讨论
每种方法都有其权衡:指令驱动方法可快速扩展但有语义漂移的风险;知识引导方法通过结构化约束保持保真度;对抗性生成则通过暴露漏洞来增强鲁棒性。未来的工作应结合这些方法的优势,并持续关注优化生成成本和发展理论基础。
数据蒸馏与压缩
数据蒸馏与压缩技术通过降低数据复杂性同时保持性能,来提升LLM后训练的效率。如下图所示,这包括三种互补的方法:用于知识迁移的模型蒸馏,用于数据集压缩的数据蒸馏,以及用于统一优化的联合压缩。
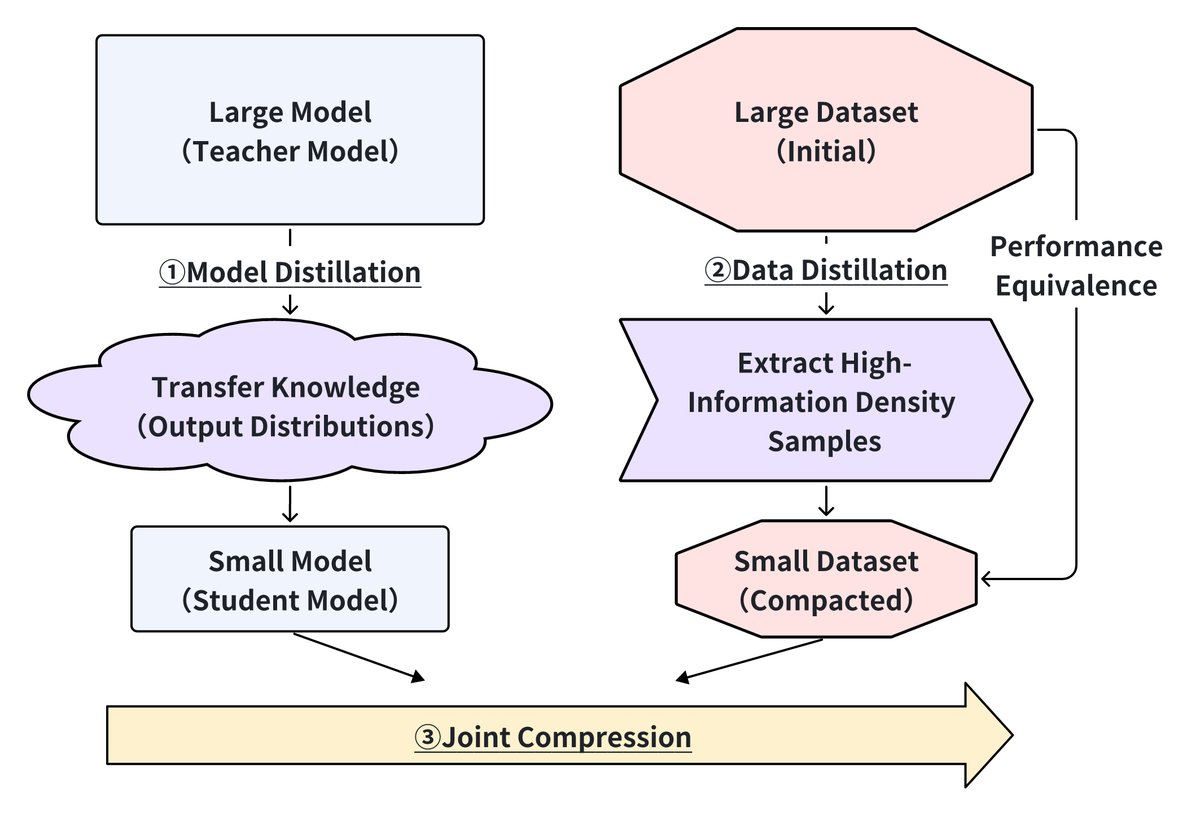
模型蒸馏
模型蒸馏将知识从大型教师模型转移到小型学生模型,同时保持性能。近期进展包括“不可能的蒸馏” (Impossible Distillation),它能从低质量教师模型中创造出高质量学生模型;以及“跨分词器蒸馏” (Cross-Tokenizer Distillation),它通过通用logit蒸馏实现了不同架构间的知识迁移。对于边缘部署,XAI驱动的蒸馏和BitDistiller等技术分别产生了可解释的模型和实现了亚4位精度。
数据蒸馏
数据蒸馏专注于选择高信息密度的样本,以创建紧凑而有代表性的数据集。研究表明,LLM生成的标签可以有效训练与人类标注相媲美的分类器。LLMLingua-2通过Token级别的蒸馏来实现提示压缩。特定领域应用包括用于模型微调的自数据蒸馏 (Self-Data Distillation) 和用于医疗数据整合的多教师蒸馏。
联合压缩
联合压缩将模型压缩与数据选择相结合,以优化整体效率。有工作共同优化了结构化剪枝和标签平滑,将LLaMA-7B压缩至2.8B参数,性能损失极小。“高效边缘蒸馏” (Efficient Edge Distillation) 通过超网训练实现了边缘设备的自适应宽度缩放。在推荐系统中,提示蒸馏 (Prompt Distillation) 旨在对齐ID-based和text-based表示,以减少推理时间。
讨论
这三种方法为提升LLM效率提供了互补的优势:模型蒸馏优化架构,数据蒸馏精选高影响力样本,联合压缩则统一了模型与数据的优化。未来的研究应聚焦于整合这些方法,特别是在边缘AI和低资源应用场景。
自进化数据生态系统
自进化数据生态系统通过自主数据生成、实时反馈和持续学习,策略性地优化LLM后训练。如下图所示,该生态系统形成了一个生成、评估和自适应训练的闭环。本文讨论其三个关键组成部分:自迭代优化、动态评估反馈和LLM即评判者。
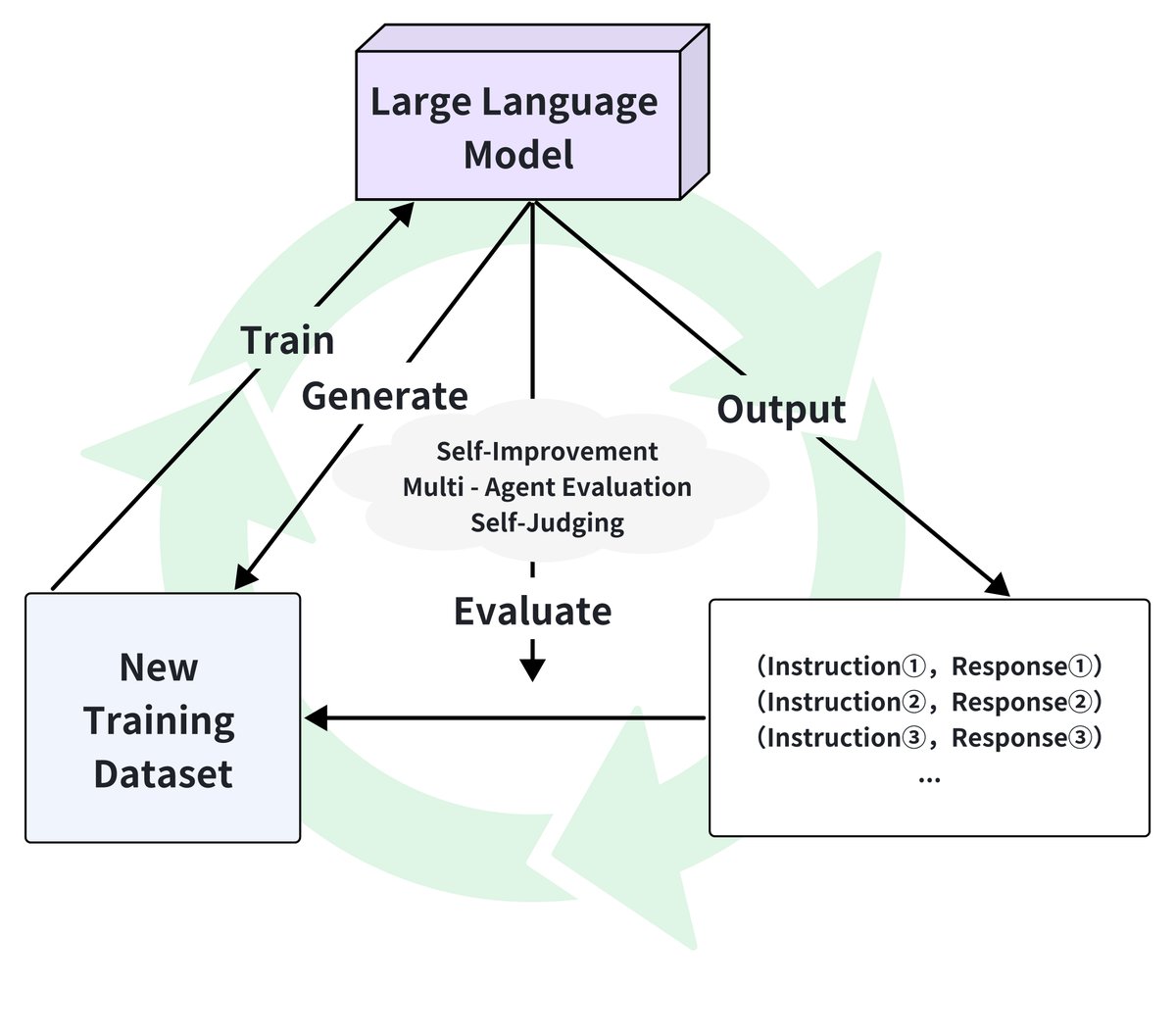
自迭代优化
自迭代优化使LLM能够利用自身输出来生成新的训练数据,从而自主地完善其能力。
- 自提升方法:Self-Rewarding、Self-Refine和Self-Boosting等方法使模型能够通过迭代的自优化来自主提升。自博弈微调 (Self-Play Fine-Tuning) 利用竞争性自我互动,表现优于传统的DPO等方法。
- 半监督自进化:SemiEvol通过一个“传播-选择”框架解决了在有限标记种子数据和大量无标签领域数据场景下的后训练适应问题。
- 知识保留:MemoryLLM在整合新数据的同时,能够保留现有知识,实现了模型的持续更新。
动态评估反馈
动态评估反馈系统允许模型根据其性能进行实时调整,动态优化其输出。
- 多智能体评估:基准自进化框架 (Benchmark Self-Evolving Framework) 和LLM-Evolve利用多智能体系统动态评估和调整LLM性能,确保跨多个基准的持续进化。
- 迭代式精炼:Self-Refine和Self-Log利用反馈循环进行迭代式精炼和日志解析,无需外部重新训练即可优化模型输出。
- 改进决策:Meta-Rewarding和自进化奖励学习 (Self-Evolved Reward Learning) 利用其输出的迭代反馈来改善判断能力,确保在复杂任务中做出更准确的决策。
LLM即评判者
“LLM即评判者” (LLM-as-a-Judge) 系统代表了一种从外部评估到自我评估的范式转变,模型在此范式中评估自己或其他模型的输出。
- 通过评判实现自提升:Self-Taught Evaluators通过生成合成比较数据来训练评判能力,而无需人类数据。JudgeLM则通过在人类偏好上进行微调来创建专门的评估模型。
- 去偏评估系统:CalibraEval通过重新校准预测分布来减轻位置偏差。Crowd Score利用单个模型内的多个AI来模拟多样化的人类判断,通过聚合减少个体偏见。
- 对抗性鲁棒性测试:TOXIGEN和ToxiCraft创造了越来越微妙的有害内容以暴露模型的盲点。R-Judge则专门针对交互环境中的情景性安全风险,而不仅仅是内容本身的危害性。
讨论
自迭代优化、动态评估反馈和LLM即评判者的结合,为LLM的自主改进创造了一个强大的框架。尽管这些方法在减少人工干预方面显示出巨大潜力,但未来的工作应侧重于将它们统一到可扩展的框架中,并使其能泛化到不同任务。
挑战与未来方向
-
领域驱动的数据合成与精炼 尽管通用模型常用于数据生成,但领域专用模型能更好地捕捉专业知识。未来的工作应探索使用领域专用的预训练模型来生成专业化数据,并结合精炼技术来优化数据质量,同时降低标注成本。
-
大规模数据合成的可扩展性 随着LLM预训练对越来越大、越来越高质量数据集的需求,高效的大规模数据生成变得至关重要。当前的数据合成和增强方法面临可扩展性瓶颈。未来的工作应专注于开发并行、经济高效的数据生成框架,以满足大规模预训练的需求,同时在数据多样性和相关性之间保持平衡。
-
可靠的质量评估指标 当前的评估框架缺乏标准化的指标来衡量合成数据的质量。未来的研究需要开发更全面的评估体系,不仅要考虑语法和流畅性,还要评估事实准确性、逻辑一致性和风格多样性,以确保生成的数据能够真正提升模型性能。