Accelerate Speculative Decoding with Sparse Computation in Verification
打破投机采样瓶颈:美团提出“稀疏验证”框架,Attention与MoE全面瘦身

在大模型推理加速的赛道上,投机采样(Speculative Decoding)无疑是近年来最耀眼的明星技术之一。它通过一个小巧的“草稿模型”快速生成多个候选 Token,再由大模型(目标模型)一次性并行验证,从而在不损失精度的情况下显著提升推理速度。
ArXiv URL:http://arxiv.org/abs/2512.21911v1
然而,随着上下文长度的不断增加以及 混合专家模型(MoE)的普及,一个新的瓶颈浮出水面:验证阶段(Verification Stage)太慢了。
当草稿长度变长,或者输入变成长文本时,目标模型需要对多个 Token 进行全量的 Attention 计算、密集的 FFN 运算以及多专家的评估。这使得“验证”这一步反而成了拖累整体速度的罪魁祸首。
为了解决这一痛点,来自美团和苏州大学的研究团队提出了一种全新的稀疏验证框架(Sparse Verification Framework)。该研究系统性地在验证阶段引入了稀疏计算,针对 Attention、FFN 和 MoE 三大组件进行了“联合瘦身”,在保持模型判断力(即接受率)几乎不变的前提下,大幅降低了计算开销。
为什么“验证”成了拦路虎?
在投机采样中,验证阶段本质上是一次并行的前向传播。虽然是并行,但计算量依然庞大。
传统的稀疏推理(Sparse Inference)方法,通常是为标准的“逐个 Token 生成”设计的。但在投机采样的验证阶段,模型面对的是多个草稿 Token。这就带来了一个新问题:现有的稀疏方法(如 KV Cache 淘汰)如果直接套用,可能会因为不同草稿 Token 对上下文关注点的差异,导致验证准确率下降,进而导致草稿被大量拒绝,加速变成了减速。
该研究通过分析发现,验证阶段在多个维度上都存在结构性的冗余:
-
Attention 冗余:并非所有历史 KV Cache 对当前验证都重要。
-
FFN 冗余:前馈网络中存在大量的低激活神经元。
-
MoE 冗余:对于 MoE 模型,并非所有激活的专家都对最终结果有显著贡献。
基于此,研究团队设计了一套三位一体的稀疏验证策略。
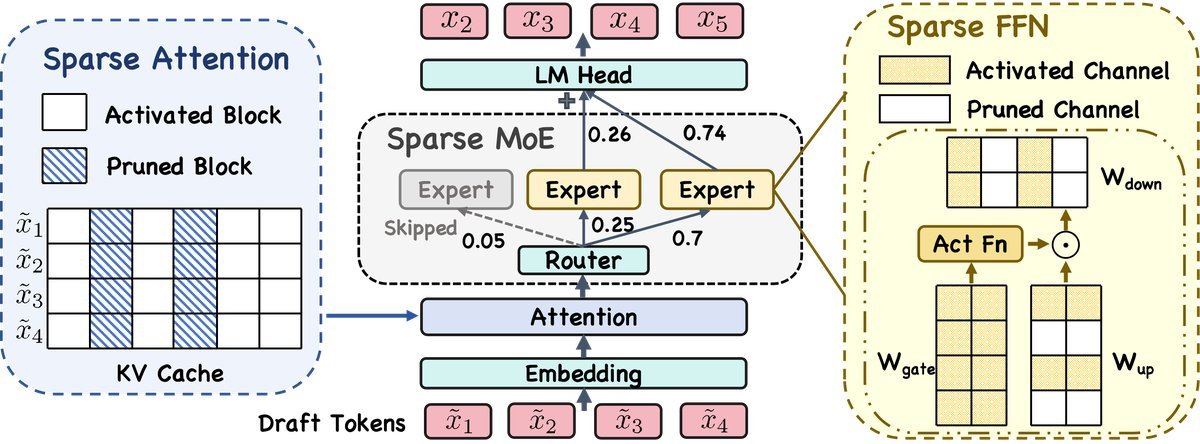
核心技术一:面向多 Token 的稀疏 Attention
传统的稀疏 Attention 往往只考虑当前这一个 Token 需要关注哪些历史信息。但在验证阶段,我们需要同时考虑多个草稿 Token 的需求。
该研究提出了一种基于重要性的稀疏 Attention机制。它通过计算草稿 Token 的 Query 与 KV Block 代表值之间的点积,来动态选择最相关的 KV Block 进行计算。
为了解决短文本的不稳定性,研究引入了分段预算控制(Piecewise Budget Control)。简单来说,当上下文较短时,保留较多的计算预算以确保稳定;当上下文变长时,则更激进地进行稀疏化,从而实现平滑的性能过渡。
此外,研究者还发现了一个有趣的现象:相邻的 Transformer 层往往关注相似的历史信息。基于此,他们设计了层间检索复用(Inter-layer Retrieval Reuse)策略。不是每一层都重新去计算“我要关注哪些 Block”,而是让某些层直接复用上一层的检索结果。这进一步减少了冗余计算。
核心技术二:即插即用的稀疏 FFN
在 Transformer 的 FFN 层中,激活值通常是高度稀疏的。也就是说,对于特定的输入,只有少部分神经元会被激活。
该研究借鉴了训练阶段的稀疏化思想,但在推理时动态进行。具体做法是:根据中间激活值的大小,动态剪枝掉那些激活值低于阈值 $\tau$ 的通道。
这种稀疏 FFN(Sparse FFN)策略不需要重新训练模型,完全是在推理时根据输入动态决定的,能够有效减少矩阵乘法的计算量。
核心技术三:自适应的稀疏 MoE
对于像 DeepSeek-V3 或 Mixtral 这样的 MoE 模型,每个 Token 通常会激活 $k$ 个专家(例如 $k=8$)。但实际上,这 $k$ 个专家的贡献是不均等的。
该研究提出了一种广义的动态专家跳过策略。在验证阶段,如果某些被选中的专家权重占比过低(低于某个动态阈值),系统就会果断“跳过”这些专家的计算。
\[\frac{\sum_{j=1}^{k-i}w_{j}}{\sum_{j=1}^{k}w_{j}}<\beta_{m}\]通过这种方式,模型可以在不显著改变输出分布的情况下,减少每个 Token 实际计算的专家数量。
实验结果:效率与准确率的完美平衡
研究团队在长文本摘要、问答以及数学推理等多个数据集上进行了广泛实验。实验对象包括 Llama3.1-8B 和 Qwen3-30B-MoE 等模型。
结果显示,这种混合稀疏验证方法在大幅降低 FLOPs(浮点运算次数)的同时,平均接受长度(Mean Acceptance Length) 保持了惊人的稳定性。
-
在长文本任务中:稀疏 Attention 发挥了巨大作用,有效缓解了 KV Cache 带来的计算压力。
-
在 MoE 模型上:稀疏 MoE 策略在减少专家计算量的同时,几乎没有损失验证的准确性。
值得注意的是,在数学推理等对精度要求极高的任务上,过度稀疏化可能会导致性能下降,这提示我们在实际应用中需要根据任务类型灵活调整稀疏度阈值。
总结
这项工作为大模型的推理加速提供了一个新的视角:加速不仅仅是生成得更快,验证得更快同样重要。
通过在验证阶段引入结构化的稀疏计算,该框架成功打破了投机采样的计算瓶颈。更重要的是,这是一套无需训练(Training-free) 的解决方案,可以直接应用于现有的开源大模型,为追求极致推理效率的开发者们提供了一把新的利器。