Accurate Table Question Answering with Accessible LLMs
Qwen-14B逼近GPT-4!Orchestra多智能体架构让开源模型制霸表格问答

表格问答(Table Question Answering, TQA)一直是企业级AI应用中的“硬骨头”。虽然GPT-4等闭源巨型模型在这一领域表现出色,但昂贵的API成本和数据隐私隐患让许多中小企业望而却步。当我们试图转向更轻量级的开源模型(如Llama-7B或Qwen-14B)时,往往会发现效果惨不忍睹——模型经常因为上下文过长或指令太复杂而“大脑宕机”。
ArXiv URL:http://arxiv.org/abs/2601.03137v1
难道低成本和高性能真的不可兼得吗?
来自阿里巴巴、哈马德·本·哈利法大学等机构的研究团队给出了否定的答案。他们提出了一种名为 Orchestra 的多智能体(Multi-Agent)框架,仅仅使用14B参数量的Qwen2.5模型,就在WikiTQ基准测试上达到了72.1%的准确率,逼近GPT-4的75.3%! 而当配合70B级别的开源模型时,它更是直接打破了所有现有记录,确立了新的SOTA(State-of-the-Art)。
本文将带你深入解读这项让开源小模型“逆天改命”的技术。
核心痛点:小模型为何“消化不良”?
在深入技术细节之前,我们需要理解为什么开源小模型在TQA任务上表现不佳。
现有的主流TQA方案(如ReAcTable)通常采用“单打独斗”的模式:给LLM一个超级复杂的Prompt,里面包含了少样本示例(Few-shot)、表格结构、自然语言问题,甚至要求模型同时进行逻辑推理(CoT)和代码生成(SQL/Python)。
对于参数量巨大的GPT-4来说,处理这种高密度的信息流游刃有余。但对于参数量较小的开源模型(Open-weight LLMs),这就像是让一个小学生同时解微积分和写代码,结果往往是指令遵循失败,或者产生了幻觉。
Orchestra 的核心洞察在于:既然一个模型搞不定复杂的全流程,那就把任务拆解,像管弦乐团(Orchestra)一样分工协作。
Orchestra架构:像乐团一样协作
Orchestra 将复杂的TQA流程解耦为两个核心子任务:逻辑推导和数据处理。并为此设计了专门的智能体角色。
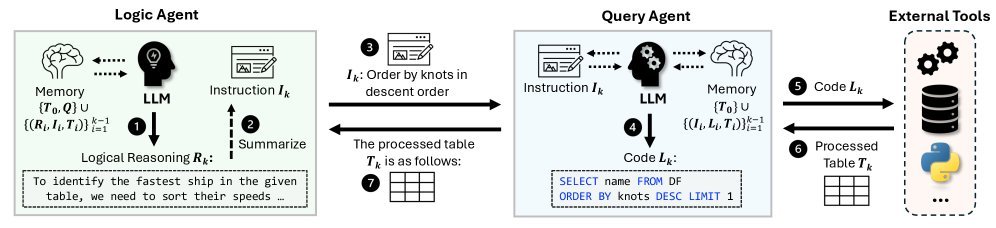
1. 逻辑智能体(Logic Agent)与查询智能体(Query Agent)
这是Orchestra最基础的“双人舞”组合:
-
逻辑智能体(Logic Agent):它是“大脑”。它不直接写代码,而是负责观察表格信息,进行逻辑推理,并决定下一步该做什么。它会将复杂的推理步骤转化为清晰的自然语言指令,发送给查询智能体。
-
查询智能体(Query Agent):它是“手”。它接收来自逻辑智能体的明确指令,专注于生成SQL查询或Python代码,与数据库交互并返回执行结果。
这种设计巧妙地降低了每个智能体面临的Prompt复杂度。逻辑智能体不需要操心SQL语法,查询智能体不需要理解复杂的业务逻辑。
2. 决策智能体(Decision Agent)与蒙特卡洛采样
仅仅有“大脑”和“手”还不够,为了进一步提高答案的可靠性,Orchestra引入了决策智能体和一种基于概率的优化策略。
研究团队发现,直接采用逻辑智能体的最终输出并不总是最优的。因此,Orchestra 引入了蒙特卡洛采样(Monte Carlo sampling)机制:
-
让上述的“双人舞”系统独立运行 $m$ 次,生成多条推理路径 ${r_1, \dots, r_m}$。
-
为每一条路径实例化一个 决策智能体(Decision Agent)。这个智能体会根据推理路径、原始表格和问题,生成一个候选答案。
-
最后,通过多数投票机制选出最终答案。
从数学角度看,这实际上是在近似求解以下最大化概率问题:
\[\arg\max_{a}\frac{1}{m}\sum_{i=1}^{m}\Pr\left[A=a\mid r_{i},T_{0},Q\right]\]这种方法有效地过滤了推理过程中的随机噪声,确保了输出的稳定性。
实验结果:开源模型的逆袭
Orchestra 的效果究竟如何?研究团队在WikiTQ、TabFact和TableBench三个权威基准上进行了广泛测试。
1. 小模型的大爆发
在WikiTQ数据集上,Orchestra + Qwen2.5-14B 取得了令人瞩目的成绩:
-
准确率达到 72.1%。
-
相比同模型的基线方法(ReAcTable),提升了 11.4%。
-
这一成绩已经非常接近 GPT-4 的 75.3%。
这意味着,用户现在可以在消费级显卡(如RTX 3090/4090)上部署本地模型,获得媲美顶尖闭源模型的TQA体验,同时完全不用担心数据隐私泄露。
2. 大模型刷新SOTA
当 Orchestra 搭配更强的开源模型(如Qwen2.5-72B, Llama3.1-70B, DeepSeek-V3)时,它直接超越了GPT-4,刷新了所有榜单的SOTA。
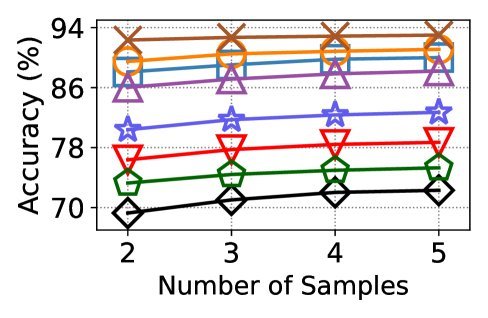
上图展示了在WikiTQ上的对比结果。可以看到,无论是哪个系列的开源模型,在搭载Orchestra框架后,性能都实现了显著跃升。
3. 成本与效率
虽然引入了多智能体和多次采样会增加推理时间,但考虑到开源模型的API成本极低(甚至为零),Orchestra 在性价比上具有压倒性优势。对于不需要毫秒级实时响应的分析场景(如生成财务报表分析),这种时间换精度的策略是非常划算的。
总结与展望
Orchestra 的成功证明了一个重要观点:模型能力的不足,可以通过优秀的系统架构设计来弥补。
通过将复杂的TQA任务解耦为“逻辑推理”和“代码执行”两个简单的子任务,并引入决策层进行结果对齐,Orchestra 成功释放了开源小模型的潜力。这对于那些受限于预算或数据隐私、无法使用GPT-4的企业和开发者来说,无疑是一个巨大的利好消息。
未来,Orchestra 还有望扩展到多表查询(Multi-table)场景,进一步挑战更复杂的数据库问答任务。