Adaptation of Agentic AI
13所顶尖名校联手:Agentic AI 适配的 4 大核心范式与未来路线图
当前的 AI Agent(智能体)开发正处于一个尴尬的“青春期”:虽然基于 GPT-4 或 Claude 3.5 等基础模型构建的 Agent 展现出了惊人的潜力,但在面对复杂的现实任务时,它们依然经常“掉链子”——工具调用错误、规划路径迷失、甚至在特定领域一本正经地胡说八道。
ArXiv URL:http://arxiv.org/abs/2512.16301v1
核心症结在于:通用的基础模型(Foundation Models)并不等同于专业的智能体系统。
为了填补这一鸿沟,“适配”(Adaptation)成为了连接通用模型与特定任务的关键桥梁。近日,来自加州理工、斯坦福、伯克利、佐治亚理工等 13 所顶尖机构的研究人员联合发表了一篇重磅综述,首次系统性地提出了 Agentic AI 适配 的统一框架。这篇论文不仅理清了当前混乱的研究版图,更为构建更强大、更可靠的智能体指明了方向。
为什么我们需要“适配”?
如果把基础模型比作一个刚刚毕业的“高材生”,那么 Agentic AI 系统就是一个需要解决具体问题的“职场专家”。高材生虽然博学,但不懂公司的具体业务流程(工具使用),也不了解行业的潜规则(领域知识)。
适配(Adaptation),就是让这位高材生通过“岗前培训”(Fine-tuning)或“配备专属助手”(Tool Adaptation),进化为专家的过程。
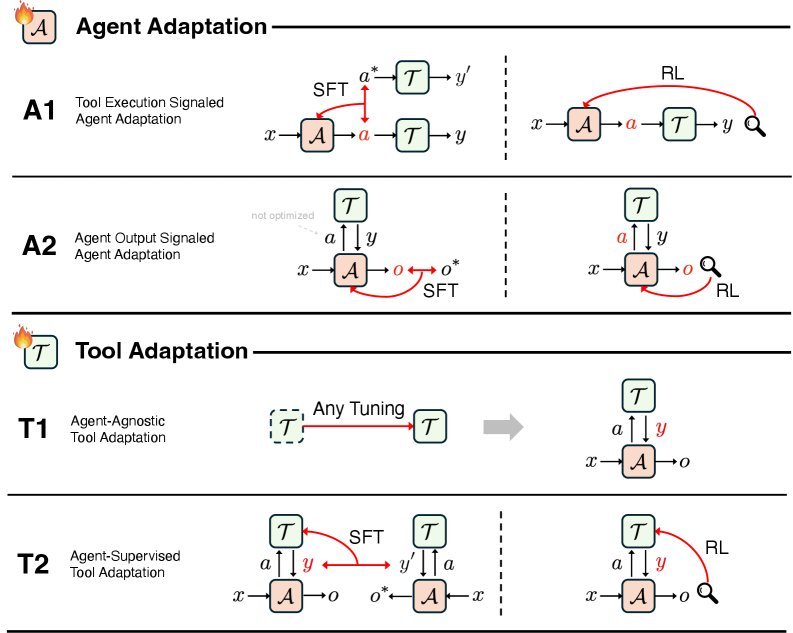
为了系统化这一过程,论文提出了一个基于 适配对象(Agent vs. Tool) 和 信号来源 的 $2 \times 2$ 核心框架,将现有的适配策略划分为四大范式:A1、A2、T1、T2。
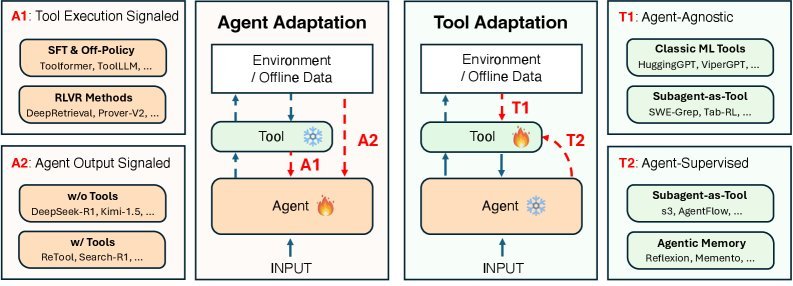
A1 & A2:改造“大脑”(Agent Adaptation)
这一类策略的核心是修改智能体本身的参数,使其更适应任务。这就像是让员工通过学习和复盘来提升自己的能力。
A1:基于工具执行信号的适配 (Tool Execution Signaled)
这是目前最直观的适配方式。智能体 $\mathcal{A}$ 发出一个动作 $a$(例如写一段 Python 代码),工具 $\mathcal{T}$ 执行后返回结果 $y$(例如报错信息或运行结果)。
-
核心逻辑:如果代码报错了,Agent 就知道自己错了;如果测试通过了,Agent 就获得正向反馈。
-
典型应用:代码生成任务中的强化学习。Agent 根据编译器的反馈(Pass/Fail)来调整自己的策略,这是一种 verifiable(可验证)的强信号。
A2:基于输出信号的适配 (Agent Output Signaled)
并非所有任务都有明确的工具执行反馈(比如写一篇公文,没有编译器告诉你对错)。此时,适配信号来自于对 Agent 最终输出的评估。
-
核心逻辑:依赖人类反馈(RLHF)或基于规则的评分系统,直接评价 Agent 的推理过程或最终答案。
-
典型应用:思维链(CoT)的优化。通过对 Agent 生成的推理步骤进行打分,引导其学会更缜密的思考逻辑。
T1 & T2:升级“装备”(Tool Adaptation)
有时候,由于成本过高或灾难性遗忘(Catastrophic Forgetting)的风险,我们并不想动 Agent 的参数(冻结 LLM)。这时,策略就变成了:给 Agent 配备更好、更顺手的工具。
T1:与 Agent 无关的工具适配 (Agent-Agnostic)
这相当于给员工买了一套市面上最好的通用软件。
-
核心逻辑:独立训练工具,不考虑具体是谁在使用它。
-
典型应用:训练一个更强大的通用检索器(Retriever)。无论在这个系统背后是 GPT-4 还是 Llama 3,这个检索器都能提供更准确的文档片段。这种工具具有极强的可复用性。
T2:Agent 监督下的工具适配 (Agent-Supervised)
这是该框架中最有趣的部分。它相当于给员工配备了一个“懂他心意”的专属助手。
-
核心逻辑:保持 Agent 不变,根据 Agent 的反馈来优化工具。
-
典型应用:自适应检索器。如果 Agent 总是抱怨搜不到想要的东西,我们就调整检索器的参数,使其更倾向于返回 当前这个 Agent 偏好的文档格式或内容。这里的“监督信号”直接源自 Agent 的需求。
权衡与选择:没有银弹
论文不仅提出了分类,还深入探讨了不同范式的 Trade-offs(权衡):
-
成本与灵活性:
-
A1/A2(改大脑)通常需要微调数十亿参数的模型,计算成本极高,但能从根本上改变 Agent 的行为模式。
-
T1/T2(改装备)通常只需训练轻量级的工具模型,成本低,且模块化程度高,方便系统升级。
-
-
泛化能力:
-
T1 类工具因为是在通用数据上训练的,往往能跨任务、跨模型使用。
-
A1 类方法如果过度依赖特定环境的反馈(Overfitting),可能会导致 Agent 在环境稍有变化时就无所适从。
-
-
模块化:
- T2 允许我们在不重新训练昂贵 LLM 的情况下,通过更新外挂工具(如记忆模块、检索模块)来持续改进系统性能。
未来的方向:协同进化
文章最后指出,单一的适配策略往往存在局限。未来的 Agentic AI 系统将走向 Co-Adaptation(协同适配):即 Agent 和 Tool 在交互中共同进化。
想象一下,一个科研 Agent 在探索未知领域时,不仅通过阅读文献提升了自己的认知(Agent Adaptation),同时还顺手优化了自己的文献检索引擎(Tool Adaptation),这将是通往更高级通用智能体的必经之路。
这篇论文为我们提供了一张清晰的“作战地图”。无论你是研究者还是工程师,在设计下一个 Agent 系统时,不妨先问自己一个问题:我现在的瓶颈是在“大脑”,还是在“工具”?