Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents
Agentic Memory:让LLM像人类一样“自主管理”记忆,长程推理能力暴涨49%

在人工智能的浩瀚星空中,大语言模型(LLM)无疑是最耀眼的那颗星。然而,这颗“星”一直有一个挥之不去的阴影——记忆力。
ArXiv URL:http://arxiv.org/abs/2601.01885v1
你是否遇到过这样的情况:和AI聊久了,它就“忘了”前面的设定;或者在处理超长任务时,它因为上下文窗口(Context Window)爆满而开始胡言乱语?现有的解决方案,无论是RAG(检索增强生成)还是各种外挂记忆库,往往都是“硬塞”给模型:要么是机械地检索,要么是基于死板的规则触发。
模型本身并不知道它该记住什么,该忘掉什么。
今天我们要解读的这篇论文 Agentic Memory (AgeMem),来自阿里巴巴和武汉大学的研究团队,它提出了一种革命性的思路:把记忆管理的权力交还给Agent自己。
这就好比从“填鸭式教育”变成了“自主学习”。Agent不再是被动地接收信息,而是像人一样,拥有了决定“此时此刻我需要记笔记(LTM)”还是“这段对话没用可以删了(STM)”的能力。
核心痛点:记忆的“割裂”与“被动”
在长程任务(Long-horizon tasks)中,LLM面临着根本性的限制:
-
窗口有限:无论上下文窗口多大,总有耗尽的一天。
-
管理割裂:现有的方法通常把长期记忆(LTM)和短期记忆(STM)分开处理。LTM靠外挂数据库,STM靠滑动窗口。两者互不通气,导致信息碎片化。
-
缺乏自主性:什么时候该存?存什么?这些决策通常由人类写死的规则(Heuristics)或者一个独立的“记忆控制器”决定,而不是Agent自己根据当前任务动态调整。
AgeMem:让记忆成为一种“工具”
AgeMem的核心思想非常直观且优雅:将记忆操作通过“工具调用(Tool Use)”的方式,直接整合进Agent的策略(Policy)中。
想象一下,Agent的手里除了有“搜索”、“计算器”这些工具外,现在多了一套记忆工具箱:
-
针对长期记忆(LTM):
-
\(Add\):这条信息很重要,我要存进永久库里。
-
\(Update\):之前记错了,或者情况变了,我要更新一下。
-
\(Delete\):这条信息过时了,删掉吧。
-
\(Retrieve\):我现在需要用到之前的知识,检索一下。
-
-
针对短期记忆(STM):
-
\(Summary\):刚才聊得太啰嗦了,我总结一下要点,把原话删了省空间。
-
\(Filter\):这几句话是废话,直接过滤掉。
-
通过这种方式,Agent在思考问题时,会像下面这样进行自我对话:
“用户提到了一个新的偏好,我应该调用 \(Add\) 工具把它存入长期记忆。同时,当前的对话历史太长了,我应该调用 \(Summary\) 工具压缩一下上下文。”
怎么训练?“三步走”策略与Step-wise GRPO
有了工具,Agent不会用怎么办?直接让它在复杂任务中乱试,很难收敛。作者设计了一套三阶段渐进式强化学习(RL)策略:
-
第一阶段:学会存(LTM Storage)。先让Agent在简单环境下学会识别关键信息并存入长期记忆。
-
第二阶段:学会管(STM Management)。引入干扰信息,训练Agent利用总结和过滤工具来维护短期上下文的纯净。
-
第三阶段:统筹兼顾(Unified Management)。在完整的长程任务中,让Agent同时协调LTM和STM,实现端到端的优化。
为了解决记忆操作带来的奖励稀疏(Sparse Reward)和不连续(Discontinuous)问题(比如你现在存了一个记忆,可能要过很久才能看到它带来的好处),作者提出了一种Step-wise GRPO(Group Relative Policy Optimization)算法。
简单来说,GRPO不需要训练一个额外的Value Model(这在大模型上很贵),而是通过对比一组采样轨迹的优劣来更新策略。Step-wise的设计更是将长期的任务奖励分配到了每一个具体的记忆操作步骤上,让Agent明白“刚才那一存,功不可没”。
实验结果:全面碾压
研究团队在ALFWorld、SciWorld、HotpotQA等5个高难度长程基准测试上进行了评估。结果非常硬核:
-
综合性能暴涨:在Qwen2.5-7B模型上,AgeMem相比无记忆基线,性能提升了惊人的49.59%!
-
超越强基线:相比目前最先进的Mem0和A-Mem等记忆增强方法,AgeMem依然保持了显著优势(平均提升4.8%~8.5%)。
-
工具使用更智能:经过RL训练后,Agent不仅学会了频繁使用\(Add\)和\(Update\)来维护知识库,还学会了在上下文拥挤时主动使用\(Filter\)。
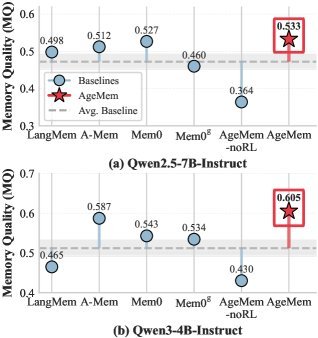
(图注:AgeMem在多个数据集上均取得了最佳性能,证明了统一记忆管理的有效性)
总结与展望
AgeMem的成功告诉我们一个道理:最好的记忆管理,不是给大脑外挂一个硬盘,而是教会大脑如何整理自己的抽屉。
通过将记忆操作“工具化”并结合强化学习,AgeMem让Agent具备了类似人类的元认知能力——知道何时记忆、何时遗忘。这不仅突破了Context Window的物理限制,更为迈向真正的通用人工智能(AGI)补上了关键的一块拼图。
未来的Agent,或许不再需要我们担心它“金鱼脑”,因为它比我们更懂得如何管理记忆。