AI Agent Systems: Architectures, Applications, and Evaluation
JACM重磅综述:拆解AI Agent三大核心架构与“Agent Transformer”新范式

大模型(LLM)的出现让自然语言成为了计算的通用接口,但我们面临的一个尴尬现实是:大多数现实世界的任务并非简单的单轮问答。无论是处理复杂的企业工作流、编写并运行代码,还是操作浏览器完成购物,仅靠“生成文本”是远远不够的。
ArXiv URL:http://arxiv.org/abs/2601.01743v1
如何将一个只会“说话”的模型,进化为一个能“做事”的智能体?
这篇发表于 JACM 2025 的综述论文《AI Agent Systems: Architectures, Applications, and Evaluation》给出了答案。该研究由亚利桑那州立大学等机构完成,它不仅系统梳理了 AI智能体(AI Agents)的架构全景,更提出了一个统一的 Agent Transformer 抽象范式,为理解从“聊天机器人”到“自主智能体”的进化提供了清晰的理论框架。
从“对话者”到“执行者”的跨越
现代数字工作的本质是碎片化的:知识分散在文档和数据库中,行动通过各种 API 和工具完成,而成功的定义是“端到端的产出”而非“看起来合理的回答”。传统的对话系统常常因为幻觉(Hallucinations)和缺乏与现实世界的连接(Grounding)而败下阵来。
该研究指出,AI智能体 填补了这一空白。它不仅仅是一个文本生成器,更是一个控制器(Controller)。它将基础模型与推理、规划、记忆和工具使用相结合,形成了一个能够观察环境、制定计划、调用工具并验证结果的闭环系统。
核心抽象:什么是“Agent Transformer”?
为了统一各种纷繁复杂的 Agent 设计(如 ReAct, AutoGPT, ToolFormer 等),该研究提出了一个极具洞察力的抽象概念:Agent Transformer。
这并非指某个具体的模型权重,而是一种系统级的抽象。作者将 Agent 定义为一个嵌入在结构化控制循环中的 Transformer 策略模型。这个循环包含四个显式接口:
-
环境观测(Observations):来自外部世界的输入。
-
记忆(Memory):短期工作上下文和长期状态存储。
-
工具(Tools):带有类型化模式(Schema)的外部能力接口。
-
验证器(Verifiers):在产生副作用前检查提案的批评机制。
我们可以用一个优雅的公式来描述这个过程:
\[\mathcal{A}\;=\;(\pi_{\theta},\mathcal{M},\mathcal{T},\mathcal{V},\mathcal{E})\]在这个循环中,智能体的行为被建模为对 交互轨迹(Interaction Traces)的序列处理:
\[\tilde{a}_{t}\sim\pi_{\theta}(\,\cdot\mid o_{t},m_{t}),\qquad\hat{a}_{t}\leftarrow\mathrm{Validate}(\mathcal{V},\tilde{a}_{t})\] \[\mathcal{E}_{t+1}\leftarrow\mathrm{Exec}(\mathcal{E}_{t},\mathcal{T},\hat{a}_{t})\]这意味着,Agent 不再是简单的 $Input \rightarrow Output$,而是一个包含检索、规划、验证、执行和更新记忆的动态系统。
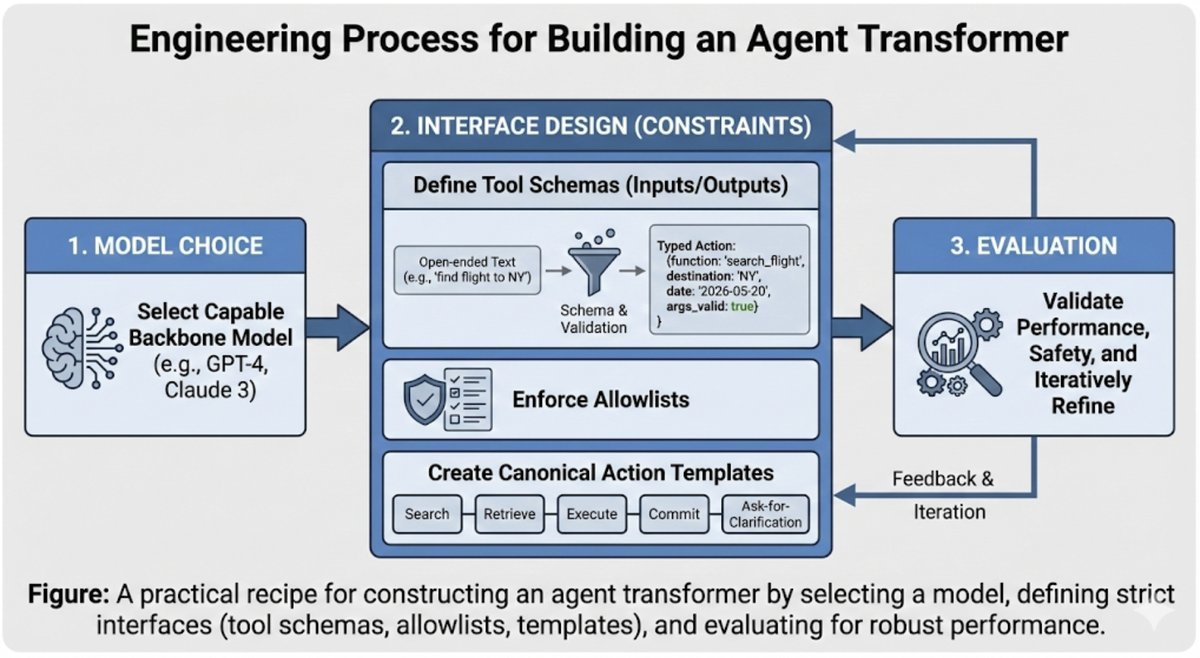
图 1:Agent Transformer 抽象架构,展示了策略模型与记忆、工具、验证器及环境的交互接口。
这一抽象统一了当前主流的几种设计模式:
-
检索增强生成(RAG):将检索视为一种“记忆”操作。
-
ReAct:将推理(Reasoning)与行动(Acting)交织,通过交替生成“思考 Token”和“工具调用”来增强逻辑性。
-
MRKL:通过路由机制将任务分发给专门的工具,分离了语言理解与确定性计算。
-
反思机制(Reflection):引入内部反馈通道,允许 Agent 在犯错后自我修正。
智能体是如何“学习”的?
如果说基础模型提供了“智商”,那么 Agent 系统则是教会模型如何使用这份智商来解决问题。该研究总结了 Agent 学习的三个层次:
-
强化学习(Reinforcement Learning, RL):
RL 非常适合 Agent,因为它直接优化长周期的回报(Return),而非单步预测。通过 RLHF(人类反馈强化学习),模型学会了如何遵循指令;而在 Agent 场景下,RL 更重要的是教会模型“何时搜索信息”、“何时行动”以及“如何从错误中恢复”。
-
模仿学习(Imitation Learning, IL):
通过学习专家演示的 结构化轨迹(即包含观察、中间思考、工具调用和结果的序列),Agent 可以快速获得基线能力。但这往往需要结合验证机制,以防止模型盲目模仿演示中的偏差。
-
上下文学习(In-Context Learning, ICL):
这是目前最灵活的“软编程”方式。通过在 Prompt 中提供工具的 Schema 和少样本示例(Few-shot exemplars),我们无需更新参数就能定义 Agent 的行为规范和协议。
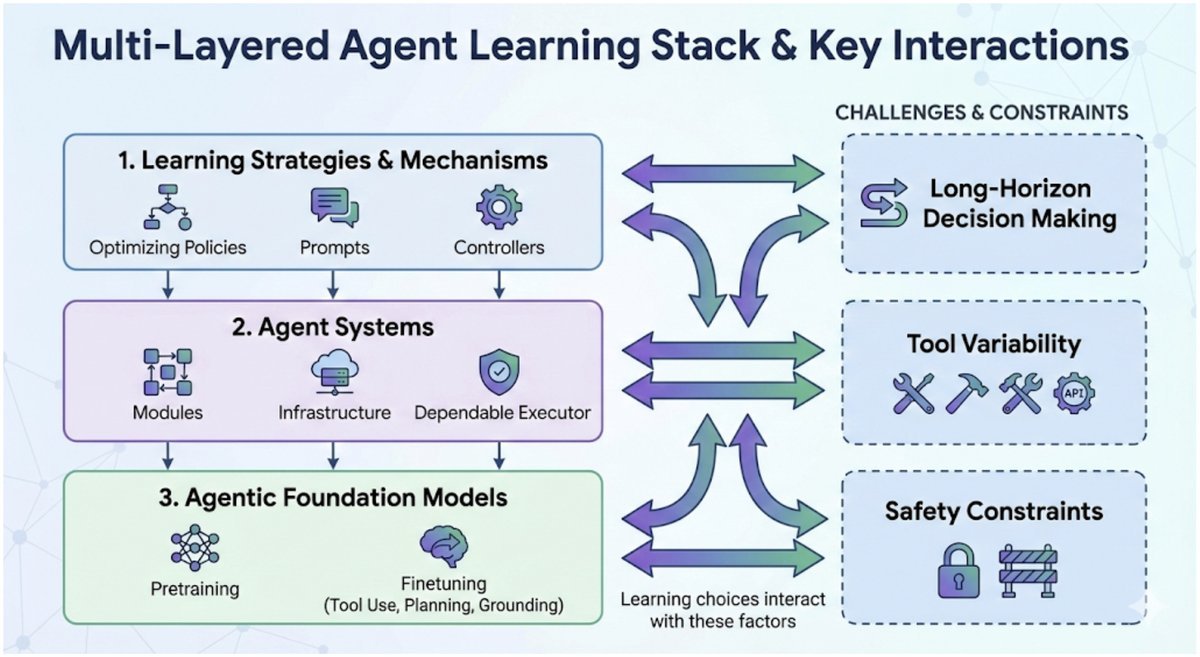
图 2:Agent AI 学习的全景图,涵盖了从机制、系统工程到基础模型微调的各个层面。
值得注意的是,该研究还强调了 传统RGB(Rules, Graphs, Behavior trees)的重要性。在 LLM 时代,规则和状态机并没有过时,它们作为“护栏”和“接口”,为概率性的模型提供了确定性的安全边界。
挑战:评估与可靠性
构建 Agent 很容易,但构建一个可靠的 Agent 极难。该研究指出了当前领域的几个核心痛点:
-
非确定性与复现难:由于采样随机性和外部工具(如 Web 搜索结果)的变化,Agent 的评估极其困难。今天能跑通的代码,明天可能因为环境变化而报错。
-
长程误差累积:在多步推理中,一个小小的错误(如选错了工具参数)会在后续步骤中被放大,导致最终任务失败。
-
安全性风险:Agent 具有执行能力(副作用),这意味着 提示注入(Prompt Injection)不再仅仅是输出脏话,而是可能导致恶意的数据删除或资金转账。因此,安全防御必须深入到工具调用的每一个环节,而不仅仅是过滤最终的文本回复。
总结
这篇综述不仅仅是对现有技术的罗列,更是一次对 AI Agent 本质的深度思考。它告诉我们,未来的 AI 系统竞争,将不再局限于谁的模型参数更大,而在于谁能构建出更高效、更可靠的 Agent Transformer 系统架构——一个能将模糊的自然语言意图,转化为精确、可执行、可验证的现实世界行动的闭环系统。