AI当上科学家:字节跳动AlphaResearch,8项难题2次击败人类专家
大型语言模型(LLM)已经能在解题、编程等任务上媲美甚至超越人类,但它们能做的仅限于已有知识的“排列组合”吗?AI能否像人类科学家一样,真正地“发现”前所未有的新知识、新算法?
论文标题:AlphaResearch: Accelerating New Algorithm Discovery with Language Models ArXiv URL:http://arxiv.org/abs/2511.08522v1
来自字节跳动、纽约大学等机构的最新研究 AlphaResearch,朝着这个终极问题迈出了关键一步。它构建了一个自主研究智能体(Agent),在与人类专家的8场算法发现竞赛中,取得了2场胜利!尤其在“圆形装箱”问题上,它发现的算法超越了所有已知的最好结果。
这项工作展示了AI从“知识的应用者”转变为“知识的发现者”的巨大潜力。
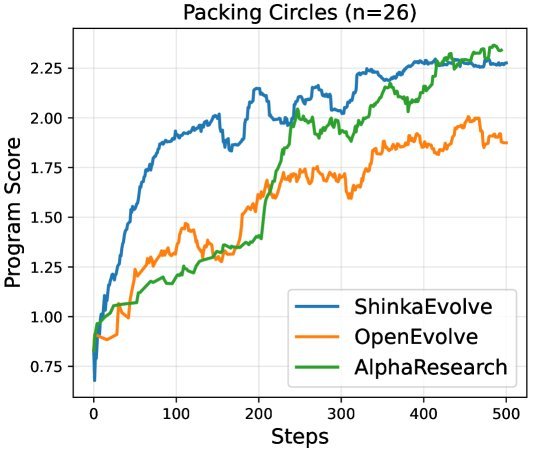 图1:在“圆形装箱 (n=26)”问题上,AlphaResearch(蓝色)的性能显著优于AlphaEvolve等其他方法。
图1:在“圆形装箱 (n=26)”问题上,AlphaResearch(蓝色)的性能显著优于AlphaEvolve等其他方法。
算法发现的“两难困境”
让AI自主发现新算法,远比我们想象的要复杂。过去的方法常常陷入一个两难的境地:
一方面,像 AlphaEvolve 这样的方法,完全依赖基于执行的验证(execution-based verification)。它们能确保生成的代码可以运行并得到一个可量化的结果。但这就像一个只会埋头做实验、却不懂科研风向的研究生,可能会找到一个技术上正确、但毫无新意或价值的“平庸”解法。
另一方面,单纯依赖AI进行想法生成(idea generation)和评估,又容易变得天马行空。AI或许能提出非常新颖的概念,可一旦真正动手实现,却发现这些想法在计算上根本不可行,或者不满足问题的基本约束。
如何让AI既能大胆创新,又能脚踏实地?AlphaResearch给出的答案是:双重研究环境。
AlphaResearch的核心机制:双重研究环境
AlphaResearch 的创新之处在于它模拟了一个更真实的科研流程,包含两个相互协作的核心环境。我们可以把它想象成一个高效的科研实验室。
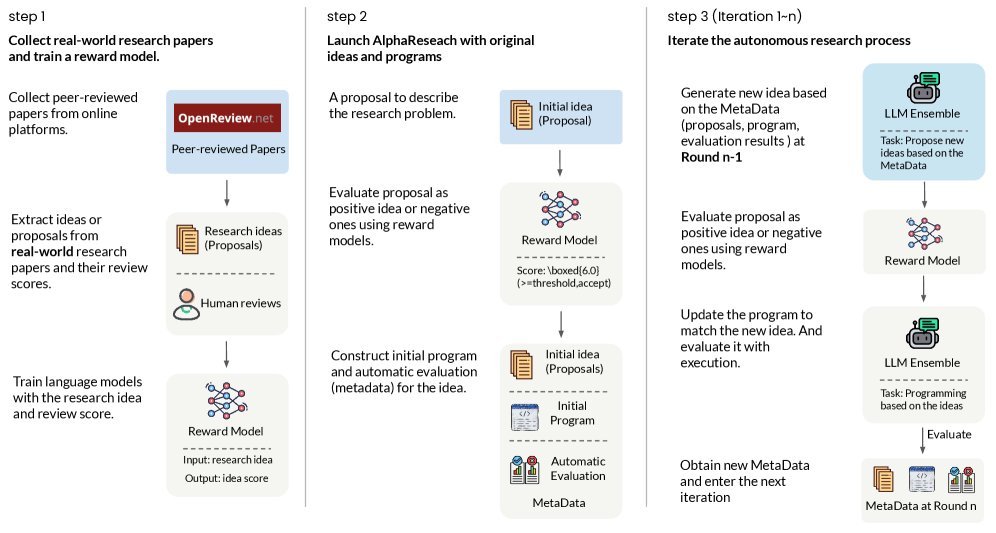 图2:AlphaResearch 的工作流程。它首先训练一个奖励模型,然后通过“提出想法 -> 双重环境验证 -> 优化”的循环来自主发现算法。
图2:AlphaResearch 的工作流程。它首先训练一个奖励模型,然后通过“提出想法 -> 双重环境验证 -> 优化”的循环来自主发现算法。
1. 模拟同行评审环境:科研的“导师”
在真正的科研中,一个想法在投入大量资源去实现之前,往往会先经过资深研究者的评估。这个想法有新意吗?有可行性吗?值得尝试吗?
AlphaResearch 通过训练一个奖励模型(Reward Model, RM)来模拟这个“同行评审”过程。这个模型就像一位经验丰富的导师。
研究团队收集了2017到2024年顶级会议ICLR的所有同行评审记录,用论文摘要作为输入,真实的评审平均分作为输出,微调训练出了一个名为 \(AlphaResearch-RM-7B\) 的模型。
这个“导师”模型的效果如何?测试结果令人惊讶:在判断一篇论文(想法)能否被接收时,\(AlphaResearch-RM-7B\) 的准确率达到了72%,显著超过了GPT-5、其他基线模型乃至人类专家的表现!
有了这位“导师”,AlphaResearch 产生的每个新想法都会先过一遍审。只有那些被认为有潜力、有新意的想法,才会被放行到下一步,大大避免了在“坏点子”上浪费计算资源。
2. 基于执行的验证环境:实验的“执行者”
通过了“导师”评审的好想法,接下来就需要进入“实验室”动手验证了。这就是基于执行的验证环境(execution-based verification)。
它就像一位严谨的实验员,负责将新想法转化为具体代码,然后运行并测量结果。
- 验证模块:检查代码是否满足问题的所有约束(例如,圆形装箱问题中,所有圆形都必须在正方形边界内且互不重叠)。
- 测量模块:如果代码有效,就计算其性能得分 $r_k$。
这个分数会作为最直接的反馈,指导智能体下一轮的迭代优化。
通过“导师”和“执行者”的协同,AlphaResearch 形成了一个高效的闭环:提出想法 -> 导师评审 -> 执行者验证 -> 结果反馈 -> 优化想法。这个循环不断进行,直到找到超越现有最佳水平的算法。
实战检验:AlphaResearchComp 竞赛
为了公平地评估 AlphaResearch 的能力,研究者们创建了一个新的评测基准 AlphaResearchComp。
这个基准包含了8个开放式的算法难题,例如“圆形装箱”、“利特尔伍德多项式”等,并为每个问题都找到了当前可验证的、人类研究者达到的最佳记录(human-best)。
| 问题名称 | 简单描述 | 目标 |
|---|---|---|
| Packing Circles (n=26) | 在单位正方形内装入26个半径可变的圆 | 最大化半径之和 |
| Packing Circles (n=32) | 在单位正方形内装入32个半径可变的圆 | 最大化半径之和 |
| Littlewood Polynomials | 寻找特定多项式在单位圆上的最小值 | 最小化 |
| Third Autocorrelation | 寻找特定序列的自相关上界 | 最小化 |
| …(其他4个问题)… | … | … |
表格概览:AlphaResearchComp中的部分问题。
比赛结果显示,AlphaResearch 在8个问题中,有2个问题找到了超越人类专家的解法,但在其余6个问题上仍落后。
尤其是在“Packing Circles (n=32)”问题上,AlphaResearch 优化出的结果达到了2.939,超越了人类设计的最佳方案和AlphaEvolve的先前记录,成为了目前已知的新SOTA(State-of-the-Art)。
同行评审“导师”的重要性
这个模拟的“同行评审”环境到底有多大用处?消融实验给出了答案。
研究者在没有“导师”模型(\(AlphaResearch-RM-7B\))的情况下运行了智能体。结果发现,这位“导师”的缺席,导致智能体尝试了大量最终执行失败或效果不佳的“坏点子”。
 图6:有无RM的对比。在400次迭代中,RM成功过滤掉了151个“坏点子”,其中108个被证实是会导致执行失败的想法,准确率超过70%。
图6:有无RM的对比。在400次迭代中,RM成功过滤掉了151个“坏点子”,其中108个被证实是会导致执行失败的想法,准确率超过70%。
如图所示,\(AlphaResearch-RM-7B\) 成功地提前否决了151个低质量想法。其中108个事后被证明确实无法成功执行。这相当于在科研初期就避免了71.5%的无用功,极大地提升了探索效率。
挑战与展望
尽管AlphaResearch取得了突破,但6/8的失败案例也提醒我们,AI自主科研之路依然漫长。在一些更复杂的难题上,AI仍难以超越人类积累的深厚直觉和洞察力。
该研究也指出了未来的方向:
- 将该方法扩展到更复杂的现实应用,如加速张量计算。
- 为智能体集成更多外部工具,提升其解决复杂问题的能力。
- 使用更大、更强的模型和更丰富的评审数据来训练奖励模型“导师”。
AlphaResearch 的探索,如同一道曙光,照亮了AI辅助科学发现的未来。它证明了,通过巧妙地模拟真实世界的科研流程,AI不仅能学习和应用知识,更有潜力去探索和拓展人类知识的边界。我们或许正处在一个由AI驱动的科研新范式的前夜。