An Empirical Study of SFT-DPO Interaction and Parameterization in Small Language Models
DPO收益甚微,LoRA竟被反超?斯坦福揭秘小模型微调的“最优解”

当前,直接偏好优化(Direct Preference Optimization, DPO)和低秩适配(Low-Rank Adaptation, LoRA)几乎已成为大模型对齐与微调的“标准动作”。我们似乎默认,先用SFT做监督微调,再用DPO对齐偏好,同时用LoRA来节省资源,就是一套黄金组合拳。
ArXiv URL:http://arxiv.org/abs/2603.20100v1
但如果你的模型没那么“大”,数据也没那么“多”呢?这套组合拳还灵吗?
来自斯坦福大学的一项最新实证研究,就给这个“想当然”的流程画上了一个大大的问号。研究者们在GPT-2(1.24亿参数)这样的小模型上系统地“解剖”了SFT、DPO、全量微调和LoRA的相互作用。
结论可能会颠覆你的认知:对于小模型,DPO带来的收益可能微乎其微,而LoRA在性能上甚至被全量微调(Full Fine-Tuning, FFT)全面超越,连训练速度的优势也荡然无存!
研究背景:当DPO与LoRA遇到小模型
在深入探讨之前,我们先快速回顾一下几个关键概念:
-
SFT (Supervised Fine-Tuning):使用有标签的数据对模型进行监督微调,教模型模仿正确答案。这是微调的基础。
-
DPO (Direct Preference Optimization):一种比RLHF更简单的对齐方法。它直接利用偏好数据(比如,答案A比答案B好),让模型学会生成更受欢迎的内容。
-
FFT (Full Fine-Tuning):全量微调,即更新模型的所有参数。效果最好,但资源消耗也最大。
-
LoRA (Low-Rank Adaptation):参数高效微调(PEFT)的代表。它通过引入少量可训练的“低秩矩阵”来模拟参数更新,冻结绝大部分原始参数,从而大幅降低显存占用。
尽管这些技术在大模型上应用广泛,但它们在小模型和中等数据量下的表现和相互作用,一直缺乏系统性的研究。这篇论文正是要填补这一空白。
实验设计:两大任务,多维度对比
为了得到可靠的结论,研究者设计了严谨的对比实验。
-
基础模型:GPT-2(124M),一个经典的解码器-only架构模型。
-
两大任务:
-
释义检测(分类任务):判断两个Quora问题是否表达相同意思。
-
莎士比亚十四行诗续写(生成任务):给定诗歌开头,生成后续内容。
-
-
核心对比维度:
-
训练策略:SFT-only vs. DPO-only vs. SFT与DPO结合。
-
参数化策略:FFT vs. LoRA。
-
通过在不同任务上交叉验证这些策略,研究旨在回答两个核心问题:
-
在小模型上,FFT和LoRA谁更优?
-
SFT和DPO如何互动?DPO应该在何时介入?
核心发现一:参数为王,全量微调(FFT)全面占优
在模型微调中,我们常常为了效率而选择LoRA。然而,这项研究的第一个惊人发现是:在GPT-2这个量级上,参数化策略的选择比是否加入DPO阶段影响更大,而FFT是毫无疑问的赢家。
研究者在释义检测任务上对比了FFT和不同秩($r=4, 8, 16$)的LoRA。结果显示:
-
性能更优:FFT在准确率和F1分数上稳定地超过了所有LoRA配置。即使是表现最好的LoRA($r=8$),也与FFT存在明显差距。
-
训练更快:更令人意外的是,在H100 GPU上,LoRA并没有带来训练时间的缩短。研究者指出,这是因为对于GPT-2这样的小模型,训练瓶颈在于计算(compute-bound),而非显存(memory-bound)。LoRA节省的显存无法转化为实际的训练速度优势。
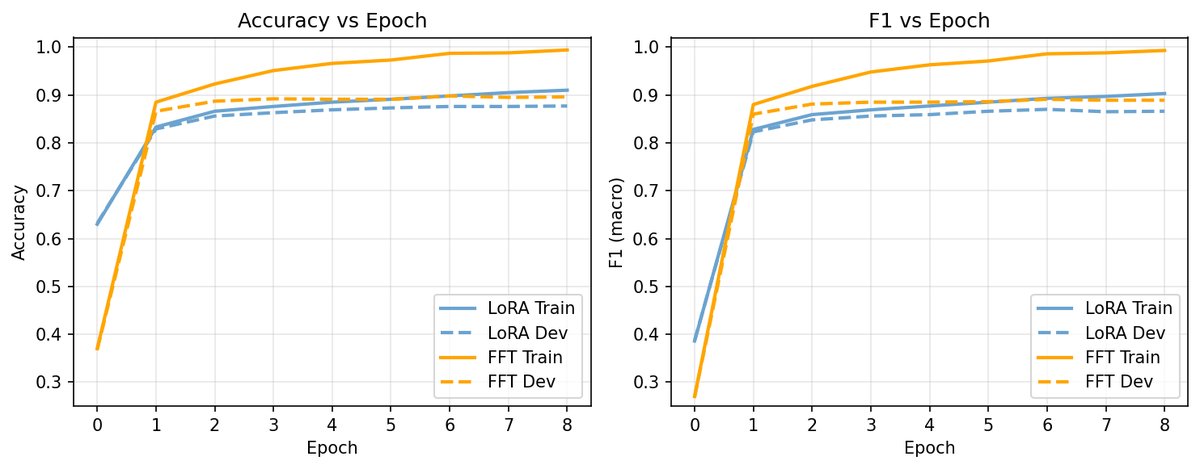
上图清晰地展示了FFT(蓝色实线)在开发集准确率上自始至终领先于不同秩的LoRA(虚线)。
这一发现提醒我们:LoRA的效率优势并非绝对,它高度依赖于模型规模和硬件条件。对于小模型,牺牲性能换来的“效率”可能根本不存在。
核心发现二:DPO的边际收益有限
DPO作为对齐模型的明星技术,表现又如何呢?答案是:在强大的SFT基础上,DPO带来的提升非常有限,甚至可以忽略不计。
研究者探索了不同的SFT与DPO“交接”时机,包括SFT-only、DPO-only,以及在SFT训练早期(第3个epoch)和后期(第9个epoch)后切换到DPO。
-
收益微小:在一个经过充分SFT训练的模型上再进行DPO,性能提升非常微弱,有时甚至没有提升。
-
DPO-only的惊喜:有趣的是,在释义检测任务中,直接从头开始进行DPO-only训练,其效果竟然能与SFT-only相媲美。研究者分析,这是因为该任务的偏好构造(正确标签 vs. 错误标签)与SFT的监督信号高度相似,使得DPO能够直接学习决策边界。
-
数据稀疏时更显无力:在数据量极小的十四行诗续写任务中(仅131首训练诗歌),DPO几乎无法在SFT的基础上带来任何有意义的改进。这表明,当模型能力和数据规模都受限时,DPO很难发挥其“精调”作用。
总而言之,DPO并非万灵药。它更像是在一个已经“吃饱”(通过SFT学到足够知识)的模型上进行的“餐后甜点”,而对于小模型来说,这道甜点可能既不美味也不必要。
实践启示:小模型微调的最佳实践
综合这项研究的发现,我们可以为小模型(如GPT-2量级)的微调提炼出几条非常实用的建议:
-
优先选择全量微调(FFT):如果计算资源允许,不要犹豫,直接上FFT。在小模型上,它是获得最佳性能最可靠的杠杆。不要想当然地认为LoRA一定更快或效果相当。
-
SFT是基石,把基础打牢:与其纠结于复杂的DPO流程,不如将精力投入到构建高质量的数据集和进行充分的SFT训练上。一个强大的SFT基座是性能的根本保障。
-
谨慎评估DPO的必要性:DPO的引入需要具体问题具体分析。如果你的SFT模型已经表现优异,DPO可能只会带来微不足道的收益。在引入它之前,先问问自己是否真的需要这“1%的提升”。
-
数据规模比训练轮数更重要:研究还发现,用更多样的数据训练更少的轮次,其效果远好于在小数据集上反复训练。数据多样性是提升泛化能力的关键。
结论
这项来自斯坦福的实证研究,为我们揭示了在小模型和有限数据场景下进行微调的“朴素真理”:与其追逐DPO和LoRA等在“大模型世界”里闪耀的技术,不如回归本源,扎扎实实地做好全量参数的监督微调(FFT-SFT)。
这并不意味着DPO和PEFT没有价值,而是在强调技术选型必须“因地制宜”。对于资源有限、模型规模不大的从业者来说,与其将宝贵的算力投入到收益不确定的高级技术上,不如集中火力,将最基础、最核心的SFT做到极致。
下次当你微调一个小模型时,或许可以先放下对DPO和LoRA的执念,先试试最简单直接的FFT,效果可能会让你惊喜。