An Empirical Study on Noisy Data and LLM Pretraining Loss Divergence
Meta/牛津重磅:噪声数据引爆LLM训练崩溃!深度比宽度更致命,诊断新法公开

动辄花费数百万美元训练的大模型,最怕遇到什么?除了硬件故障,最令人心惊肉跳的莫过于看着Loss曲线突然“起飞”,然后一去不复返——也就是所谓的损失发散(Loss Divergence)。
ArXiv URL:http://arxiv.org/abs/2602.02400v1
长期以来,工程师们往往将训练不稳定归咎于学习率(Learning Rate)过高或架构设计问题。然而,Meta和牛津大学的一项最新联合研究揭示了一个常被忽视却致命的元凶:数据噪声。
这项研究并未止步于“数据质量很重要”这种泛泛之谈,而是通过严谨的控制变量实验,回答了几个硬核问题:什么样的噪声最致命?模型变大后会更脆弱吗?如何区分是“学习率太高”还是“数据太脏”导致的崩溃?
噪声:不仅仅是“脏数据”
在大规模Web语料库中,噪声无处不在,从乱码到哈希值。为了量化研究,作者没有使用模糊的“低质量文本”,而是向干净数据中注入了受控的均匀随机噪声(Uniform Random Noise)。
研究首先抛出了一个明确的结论:噪声数据确实会导致预训练损失发散,而且噪声的类型至关重要。
如上图所示,即使是完全相同的架构和噪声比例,仅仅改变随机种子,有的模型能挺过去,有的则直接崩溃。
更有趣的发现是噪声的“注入方式”。研究对比了两种噪声引入策略:
-
覆盖(Overwriting):用噪声Token替换原有Token。
-
插入(Inserting):在原有文本中插入噪声Token。
结果显示,插入噪声比覆盖噪声更具破坏性。这可能是因为插入随机Token破坏了原本的语言结构和位置编码的连续性,给模型的上下文学习带来了更大的干扰。
扩展定律的阴暗面:深度比宽度更危险
随着模型规模的扩大,我们通常期待模型能力变强,但它是否也变得更“娇气”了?
研究团队在4.8亿到52亿参数的范围内进行了测试,发现了一个令人不安的趋势:模型越大,对噪声越敏感。但这其中有一个关键的细微差别——深度(层数)比宽度(隐藏层维度)的影响大得多。
在控制变量实验中:
-
增加宽度(从1024到4096):虽然参数量增加了,但模型的崩溃概率并没有显著增加。
-
增加深度(从5层到35层):模型的稳定性急剧下降。在极端情况下,35层的模型即使只面对5%的噪声,也有15%的概率发生训练崩溃。
这意味着,在设计超大模型时,如果数据质量存疑,盲目堆叠层数可能会带来巨大的训练风险。
诊断神技:是学习率太高,还是数据太脏?
当训练Loss炸了,工程师该怎么办?是调低学习率重跑,还是去清洗数据?这通常需要凭经验瞎猜。
但这篇论文提供了一个非常实用的定量诊断工具。
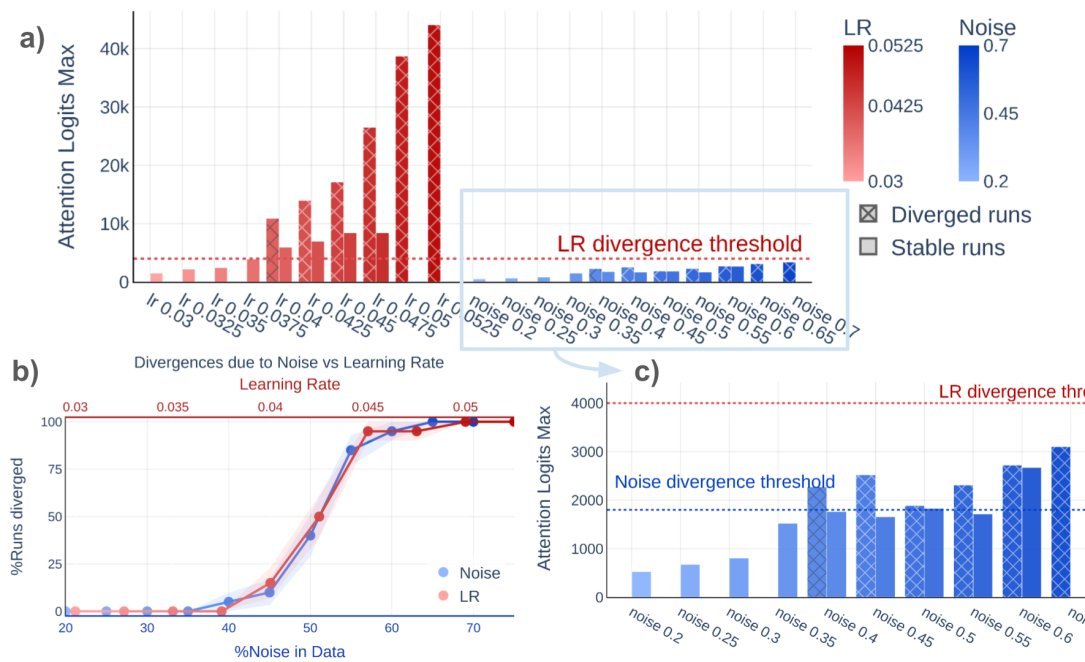
研究发现,虽然高学习率(High LR)和噪声数据(Noisy Data)都会导致Loss发散,但它们在模型内部的激活模式(Activation Patterns)上表现截然不同。
关键指标是最大注意力Logit(Maximum Attention Logit),即 $z_{ij}=\frac{\langle q_{i},k_{j}\rangle}{\sqrt{d_{h}}}$ 中的最大值。
-
高学习率导致的崩溃:最大注意力Logit通常会飙升到极高的数值(约 4000)才发生崩溃。这是因为过大的更新步长导致参数范数爆炸。
-
噪声数据导致的崩溃:最大注意力Logit也会升高,但在达到一个较低的阈值(约 1800)时,模型就已经崩溃了。
诊断指南:如果你的模型挂了,检查一下崩溃前的Attention Logits。如果它在1800左右就撑不住了,别犹豫,去洗数据吧,调学习率可能没用;如果它飙到了4000+,那才是学习率的问题。
此外,参数范数(Parameter Norms)也是一个辅助指标:噪声导致的崩溃通常伴随着较小的参数范数,而高学习率则会导致参数范数膨胀。
MoE 并不比 Dense 更脆弱
混合专家模型(Mixture-of-Experts, MoE)因其稀疏性通常被认为训练难度更大。人们担心:会不会某些Expert运气不好,分到了全是噪声的数据,从而导致局部崩溃,进而拖累整体?
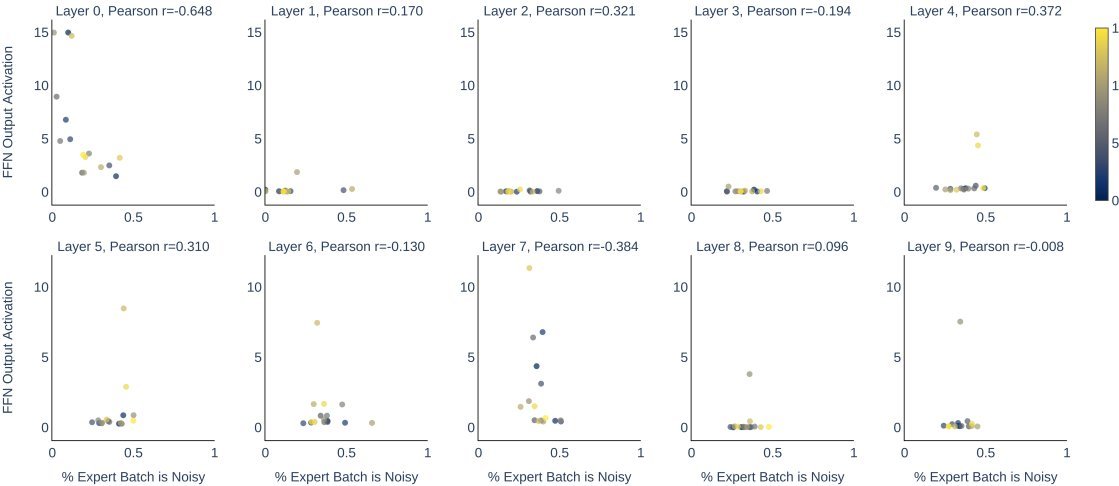
研究团队对比了Dense模型和同等激活参数量的MoE模型。结果令人宽慰:MoE模型对噪声数据的敏感度与Dense模型相当。
通过分析MoE的路由情况(上图),研究人员发现,虽然不同Expert接收到的噪声比例确实不同,但这与Expert输出的激活幅度(Activation Magnitude)之间几乎没有相关性(平均皮尔逊相关系数为 -0.009)。这意味着MoE的路由机制并没有因为噪声数据而产生特异性的“毒性积聚”。
总结与启示
这篇论文为LLM训练师们提供了一份宝贵的“避坑指南”:
-
数据清洗不仅为了效果,更为了活着:噪声不仅仅降低模型性能,它能直接导致训练失败。
-
警惕深层模型:如果你的模型很深(Layer很多),请务必使用更高质量的数据。
-
科学诊断:利用Attention Logits的阈值差异,快速定位训练失败的根源,避免在错误的调整方向上浪费昂贵的算力。
在迈向万亿参数模型的路上,数据质量不仅是天花板,更是地基。地基不稳,再宏伟的大厦也会在顷刻间崩塌。